 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Implicit Sample Noise Modeling: Deviation-driven Matrix Factorization
Oct 28, 2016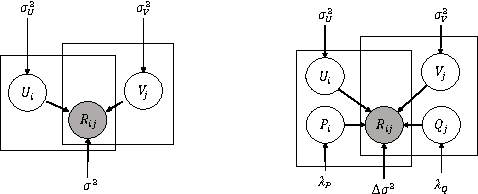
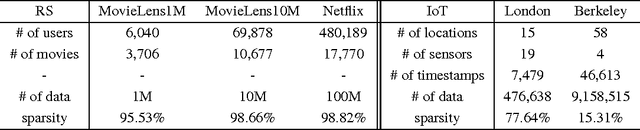

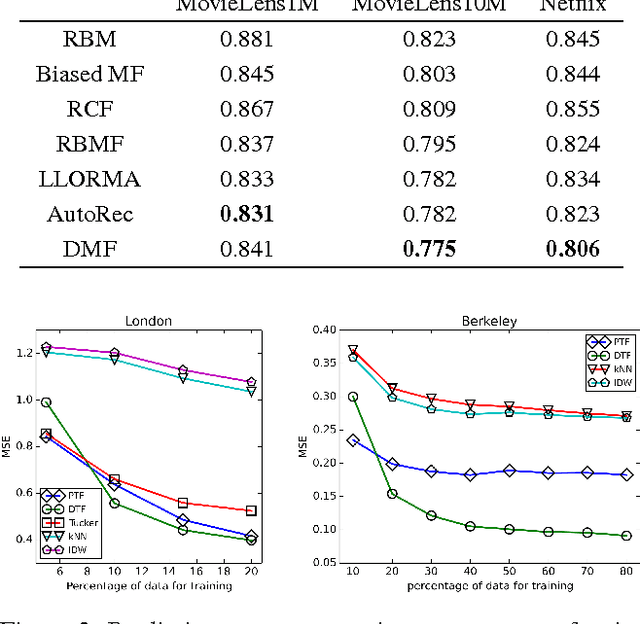
The objective function of a matrix factorization model usually aims to minimize the average of a regression error contributed by each element. However, given the existence of stochastic noises, the implicit deviations of sample data from their true values are almost surely diverse, which makes each data point not equally suitable for fitting a model. In this case, simply averaging the cost among data in the objective function is not ideal. Intuitively we would like to emphasize more on the reliable instances (i.e., those contain smaller noise) while training a model. Motivated by such observation, we derive our formula from a theoretical framework for optimal weighting under heteroscedastic noise distribution. Specifically, by modeling and learning the deviation of data, we design a novel matrix factorization model. Our model has two advantages. First, it jointly learns the deviation and conducts dynamic reweighting of instances, allowing the model to converge to a better solution. Second, during learning the deviated instances are assigned lower weights, which leads to faster convergence since the model does not need to overfit the noise. The experiments are conducted in clean recommendation and noisy sensor datasets to test the effectiveness of the model in various scenarios. The results show that our model outperforms the state-of-the-art factorization and deep learning models in both accuracy and efficiency.
Cost-aware Pre-training for Multiclass Cost-sensitive Deep Learning
May 24, 2016
Deep learning has been one of the most prominent machine learning techniques nowadays, being the state-of-the-art on a broad range of applications where automatic feature extraction is needed. Many such applications also demand varying costs for different types of mis-classification errors, but it is not clear whether or how such cost information can be incorporated into deep learning to improve performance. In this work, we propose a novel cost-aware algorithm that takes into account the cost information into not only the training stage but also the pre-training stage of deep learning. The approach allows deep learning to conduct automatic feature extraction with the cost information effectively. Extensive experimental results demonstrate that the proposed approach outperforms other deep learning models that do not digest the cost information in the pre-training stage.