 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSRGAN: Explicitly Learning Disentangled Representation of Underlying Structure and Rendering for Image Generation without Tuple Supervision
Paper and Code
Sep 30, 2019
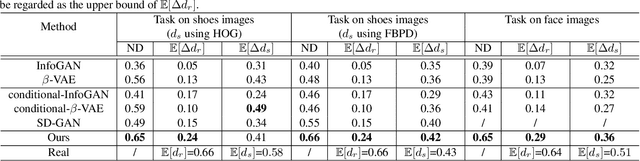
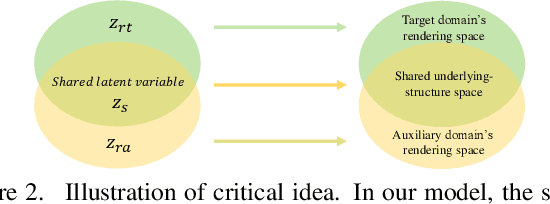
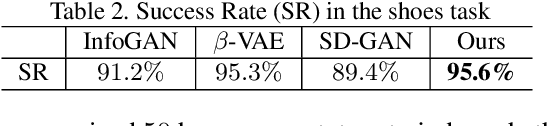
We focus on explicitly learning disentangled representation for natural image generation, where the underlying spatial structure and the rendering on the structure can be independently controlled respectively, yet using no tuple supervision. The setting is significant since tuple supervision is costly and sometimes even unavailable. However, the task is highly unconstrained and thus ill-posed. To address this problem, we propose to introduce an auxiliary domain which shares a common underlying-structure space with the target domain, and we make a partially shared latent space assumption. The key idea is to encourage the partially shared latent variable to represent the similar underlying spatial structures in both domains, while the two domain-specific latent variables will be unavoidably arranged to present renderings of two domains respectively. This is achieved by designing two parallel generative networks with a common Progressive Rendering Architecture (PRA), which constrains both generative networks' behaviors to model shared underlying structure and to model spatially dependent relation between rendering and underlying structure. Thus, we propose DSRGAN (GANs for Disentangling Underlying Structure and Rendering) to instantiate our method. We also propose a quantitative criterion (the Normalized Disentanglability) to quantify disentanglability. Comparison to the state-of-the-art methods shows that DSRGAN can significantly outperform them in disentanglability.