 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025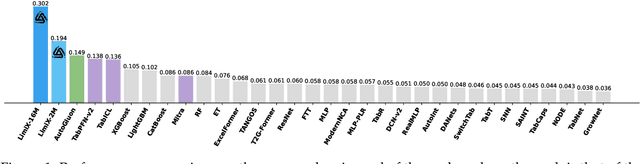
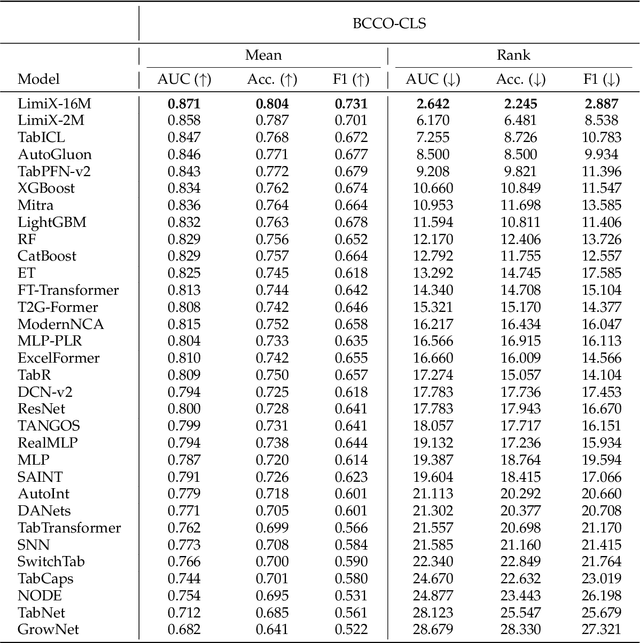
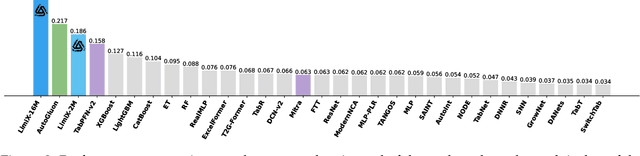
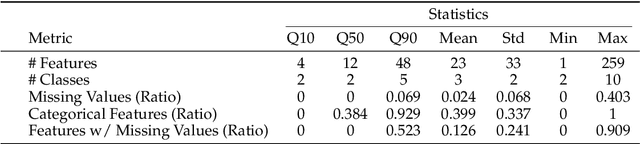
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.
CLIP-Powered TASS: Target-Aware Single-Stream Network for Audio-Visual Question Answering
May 13, 2024


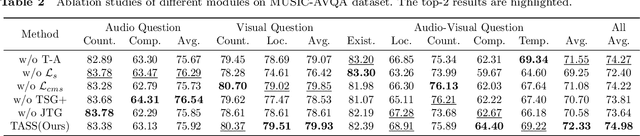
While vision-language pretrained models (VLMs) excel in various multimodal understanding tasks, their potential in fine-grained audio-visual reasoning, particularly for audio-visual question answering (AVQA), remains largely unexplored. AVQA presents specific challenges for VLMs due to the requirement of visual understanding at the region level and seamless integration with audio modality. Previous VLM-based AVQA methods merely used CLIP as a feature encoder but underutilized its knowledge, and mistreated audio and video as separate entities in a dual-stream framework as most AVQA methods. This paper proposes a new CLIP-powered target-aware single-stream (TASS) network for AVQA using the image-text matching knowledge of the pretrained model through the audio-visual matching characteristic of nature. It consists of two key components: the target-aware spatial grounding module (TSG+) and the single-stream joint temporal grounding module (JTG). Specifically, we propose a TSG+ module to transfer the image-text matching knowledge from CLIP models to our region-text matching process without corresponding ground-truth labels. Moreover, unlike previous separate dual-stream networks that still required an additional audio-visual fusion module, JTG unifies audio-visual fusion and question-aware temporal grounding in a simplified single-stream architecture. It treats audio and video as a cohesive entity and further extends the pretrained image-text knowledge to audio-text matching by preserving their temporal correlation with our proposed cross-modal synchrony (CMS) loss. Extensive experiments conducted on the MUSIC-AVQA benchmark verified the effectiveness of our proposed method over existing state-of-the-art methods.
Target-Aware Spatio-Temporal Reasoning via Answering Questions in Dynamics Audio-Visual Scenarios
May 21, 2023Audio-visual question answering (AVQA) is a challenging task that requires multistep spatio-temporal reasoning over multimodal contexts. To achieve scene understanding ability similar to humans, the AVQA task presents specific challenges, including effectively fusing audio and visual information and capturing question-relevant audio-visual features while maintaining temporal synchronization. This paper proposes a Target-aware Joint Spatio-Temporal Grounding Network for AVQA to address these challenges. The proposed approach has two main components: the Target-aware Spatial Grounding module, the Tri-modal consistency loss and corresponding Joint audio-visual temporal grounding module. The Target-aware module enables the model to focus on audio-visual cues relevant to the inquiry subject by exploiting the explicit semantics of text modality. The Tri-modal consistency loss facilitates the interaction between audio and video during question-aware temporal grounding and incorporates fusion within a simpler single-stream architecture. Experimental results on the MUSIC-AVQA dataset demonstrate the effectiveness and superiority of the proposed method over existing state-of-the-art methods. Our code will be availiable soon.
Leveraging the Video-level Semantic Consistency of Event for Audio-visual Event Localization
Oct 11, 2022

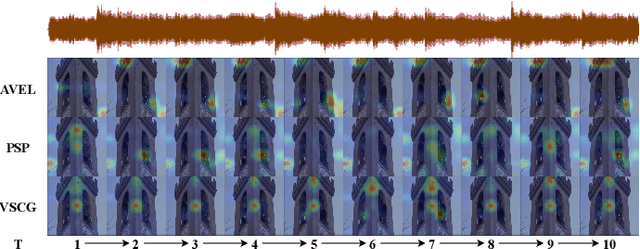

Audio-visual event localization has attracted much attention in recent years. Most existing methods are often limited to independently encoding and classifying each video segment separated from the full video (which can be regarded as the segment-level representations of events). However, they ignore the semantic consistency of the event within the same full video (which can be considered as the video-level representations of events). In contrast to existing methods, we propose a novel video-level semantic consistency guidance network for the AVE task. Specifically, we propose an event semantic consistency modeling (ESCM) module to explore the video-level semantic consistency of events. It consists of two components: cross-modal event representation extractor (CERE) and intra-modal semantic consistency enhancer (ISCE). CERE is proposed to obtain the event semantic representation at the video level including, audio and visual modules. Furthermore, ISCE takes the video-level event semantic representation as the prior knowledge to guide the model to focus on the semantic continuity of the event within each modality. Moreover, we propose a new negative pair filter loss to encourage the network to filter out the irrelevant segment pairs and a new smooth loss to further increase the gap between different categories of events under the weakly-supervised setting. We perform extensive experiments on the public AVE dataset and outperform the state-of-the-art methods in both fully and weakly supervised settings, thus verifying the effectiveness of our method.
ML4C: Seeing Causality Through Latent Vicinity
Oct 01, 2021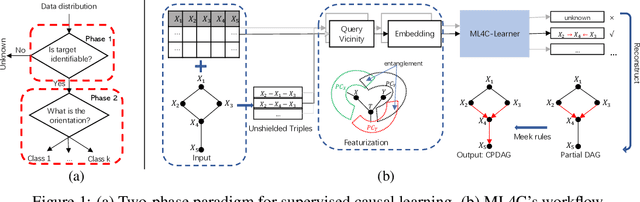
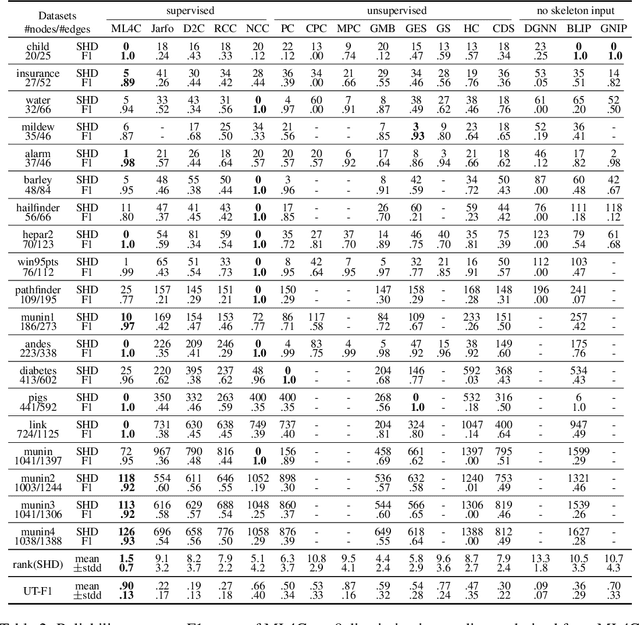

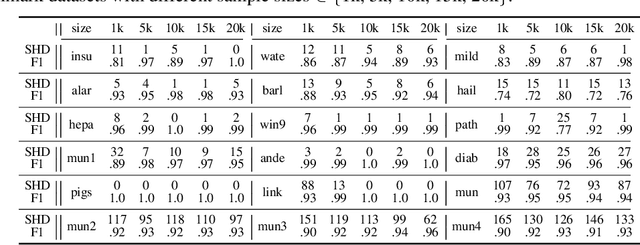
Supervised Causal Learning (SCL) aims to learn causal relations from observational data by accessing previously seen datasets associated with ground truth causal relations. This paper presents a first attempt at addressing a fundamental question: What are the benefits from supervision and how does it benefit? Starting from seeing that SCL is not better than random guessing if the learning target is non-identifiable a priori, we propose a two-phase paradigm for SCL by explicitly considering structure identifiability. Following this paradigm, we tackle the problem of SCL on discrete data and propose ML4C. The core of ML4C is a binary classifier with a novel learning target: it classifies whether an Unshielded Triple (UT) is a v-structure or not. Starting from an input dataset with the corresponding skeleton provided, ML4C orients each UT once it is classified as a v-structure. These v-structures are together used to construct the final output. To address the fundamental question of SCL, we propose a principled method for ML4C featurization: we exploit the vicinity of a given UT (i.e., the neighbors of UT in skeleton), and derive features by considering the conditional dependencies and structural entanglement within the vicinity. We further prove that ML4C is asymptotically perfect. Last but foremost, thorough experiments conducted on benchmark datasets demonstrate that ML4C remarkably outperforms other state-of-the-art algorithms in terms of accuracy, robustness, tolerance and transferability. In summary, ML4C shows promising results on validating the effectiveness of supervision for causal learning.