 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Powered TASS: Target-Aware Single-Stream Network for Audio-Visual Question Answering
Paper and Code
May 13, 2024


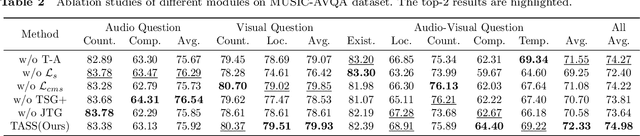
While vision-language pretrained models (VLMs) excel in various multimodal understanding tasks, their potential in fine-grained audio-visual reasoning, particularly for audio-visual question answering (AVQA), remains largely unexplored. AVQA presents specific challenges for VLMs due to the requirement of visual understanding at the region level and seamless integration with audio modality. Previous VLM-based AVQA methods merely used CLIP as a feature encoder but underutilized its knowledge, and mistreated audio and video as separate entities in a dual-stream framework as most AVQA methods. This paper proposes a new CLIP-powered target-aware single-stream (TASS) network for AVQA using the image-text matching knowledge of the pretrained model through the audio-visual matching characteristic of nature. It consists of two key components: the target-aware spatial grounding module (TSG+) and the single-stream joint temporal grounding module (JTG). Specifically, we propose a TSG+ module to transfer the image-text matching knowledge from CLIP models to our region-text matching process without corresponding ground-truth labels. Moreover, unlike previous separate dual-stream networks that still required an additional audio-visual fusion module, JTG unifies audio-visual fusion and question-aware temporal grounding in a simplified single-stream architecture. It treats audio and video as a cohesive entity and further extends the pretrained image-text knowledge to audio-text matching by preserving their temporal correlation with our proposed cross-modal synchrony (CMS) loss. Extensive experiments conducted on the MUSIC-AVQA benchmark verified the effectiveness of our proposed method over existing state-of-the-art methods.