 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
MedQ-Bench: Evaluating and Exploring Medical Image Quality Assessment Abilities in MLLMs
Oct 02, 2025
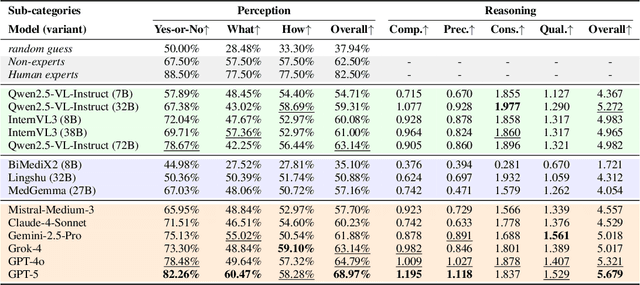
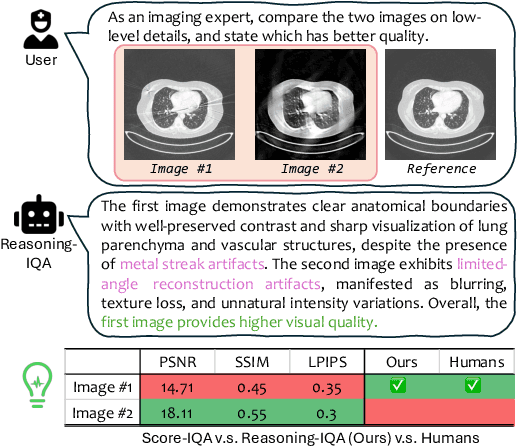

Medical Image Quality Assessment (IQA) serves as the first-mile safety gate for clinical AI, yet existing approaches remain constrained by scalar, score-based metrics and fail to reflect the descriptive, human-like reasoning process central to expert evaluation. To address this gap, we introduce MedQ-Bench, a comprehensive benchmark that establishes a perception-reasoning paradigm for language-based evaluation of medical image quality with Multi-modal Large Language Models (MLLMs). MedQ-Bench defines two complementary tasks: (1) MedQ-Perception, which probes low-level perceptual capability via human-curated questions on fundamental visual attributes; and (2) MedQ-Reasoning, encompassing both no-reference and comparison reasoning tasks, aligning model evaluation with human-like reasoning on image quality. The benchmark spans five imaging modalities and over forty quality attributes, totaling 2,600 perceptual queries and 708 reasoning assessments, covering diverse image sources including authentic clinical acquisitions, images with simulated degradations via physics-based reconstructions, and AI-generated images. To evaluate reasoning ability, we propose a multi-dimensional judging protocol that assesses model outputs along four complementary axes. We further conduct rigorous human-AI alignment validation by comparing LLM-based judgement with radiologists. Our evaluation of 14 state-of-the-art MLLMs demonstrates that models exhibit preliminary but unstable perceptual and reasoning skills, with insufficient accuracy for reliable clinical use. These findings highlight the need for targeted optimization of MLLMs in medical IQA. We hope that MedQ-Bench will catalyze further exploration and unlock the untapped potential of MLLMs for medical image quality evaluation.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
MedITok: A Unified Tokenizer for Medical Image Synthesis and Interpretation
May 25, 2025Advanced autoregressive models have reshaped multimodal AI. However, their transformative potential in medical imaging remains largely untapped due to the absence of a unified visual tokenizer -- one capable of capturing fine-grained visual structures for faithful image reconstruction and realistic image synthesis, as well as rich semantics for accurate diagnosis and image interpretation. To this end, we present MedITok, the first unified tokenizer tailored for medical images, encoding both low-level structural details and high-level clinical semantics within a unified latent space. To balance these competing objectives, we introduce a novel two-stage training framework: a visual representation alignment stage that cold-starts the tokenizer reconstruction learning with a visual semantic constraint, followed by a textual semantic representation alignment stage that infuses detailed clinical semantics into the latent space. Trained on the meticulously collected large-scale dataset with over 30 million medical images and 2 million image-caption pairs, MedITok achieves state-of-the-art performance on more than 30 datasets across 9 imaging modalities and 4 different tasks. By providing a unified token space for autoregressive modeling, MedITok supports a wide range of tasks in clinical diagnostics and generative healthcare applications. Model and code will be made publicly available at: https://github.com/Masaaki-75/meditok.
RetinaLogos: Fine-Grained Synthesis of High-Resolution Retinal Images Through Captions
May 19, 2025The scarcity of high-quality, labelled retinal imaging data, which presents a significant challenge in the development of machine learning models for ophthalmology, hinders progress in the field. To synthesise Colour Fundus Photographs (CFPs), existing methods primarily relying on predefined disease labels face significant limitations. However, current methods remain limited, thus failing to generate images for broader categories with diverse and fine-grained anatomical structures. To overcome these challenges, we first introduce an innovative pipeline that creates a large-scale, synthetic Caption-CFP dataset comprising 1.4 million entries, called RetinaLogos-1400k. Specifically, RetinaLogos-1400k uses large language models (LLMs) to describe retinal conditions and key structures, such as optic disc configuration, vascular distribution, nerve fibre layers, and pathological features. Furthermore, based on this dataset, we employ a novel three-step training framework, called RetinaLogos, which enables fine-grained semantic control over retinal images and accurately captures different stages of disease progression, subtle anatomical variations, and specific lesion types. Extensive experiments demonstrate state-of-the-art performance across multiple datasets, with 62.07% of text-driven synthetic images indistinguishable from real ones by ophthalmologists. Moreover, the synthetic data improves accuracy by 10%-25% in diabetic retinopathy grading and glaucoma detection, thereby providing a scalable solution to augment ophthalmic datasets.
Ophora: A Large-Scale Data-Driven Text-Guided Ophthalmic Surgical Video Generation Model
May 13, 2025In ophthalmic surgery, developing an AI system capable of interpreting surgical videos and predicting subsequent operations requires numerous ophthalmic surgical videos with high-quality annotations, which are difficult to collect due to privacy concerns and labor consumption. Text-guided video generation (T2V) emerges as a promising solution to overcome this issue by generating ophthalmic surgical videos based on surgeon instructions. In this paper, we present Ophora, a pioneering model that can generate ophthalmic surgical videos following natural language instructions. To construct Ophora, we first propose a Comprehensive Data Curation pipeline to convert narrative ophthalmic surgical videos into a large-scale, high-quality dataset comprising over 160K video-instruction pairs, Ophora-160K. Then, we propose a Progressive Video-Instruction Tuning scheme to transfer rich spatial-temporal knowledge from a T2V model pre-trained on natural video-text datasets for privacy-preserved ophthalmic surgical video generation based on Ophora-160K. Experiments on video quality evaluation via quantitative analysis and ophthalmologist feedback demonstrate that Ophora can generate realistic and reliable ophthalmic surgical videos based on surgeon instructions. We also validate the capability of Ophora for empowering downstream tasks of ophthalmic surgical workflow understanding. Code is available at https://github.com/mar-cry/Ophora.
GMAI-VL-R1: Harnessing Reinforcement Learning for Multimodal Medical Reasoning
Apr 02, 2025Recent advances in general medical AI have made significant strides, but existing models often lack the reasoning capabilities needed for complex medical decision-making. This paper presents GMAI-VL-R1, a multimodal medical reasoning model enhanced by reinforcement learning (RL) to improve its reasoning abilities. Through iterative training, GMAI-VL-R1 optimizes decision-making, significantly boosting diagnostic accuracy and clinical support. We also develop a reasoning data synthesis method, generating step-by-step reasoning data via rejection sampling, which further enhances the model's generalization. Experimental results show that after RL training, GMAI-VL-R1 excels in tasks such as medical image diagnosis and visual question answering. While the model demonstrates basic memorization with supervised fine-tuning, RL is crucial for true generalization. Our work establishes new evaluation benchmarks and paves the way for future advancements in medical reasoning models. Code, data, and model will be released at \href{https://github.com/uni-medical/GMAI-VL-R1}{this link}.
Unpaired Translation of Chest X-ray Images for Lung Opacity Diagnosis via Adaptive Activation Masks and Cross-Domain Alignment
Mar 25, 2025Chest X-ray radiographs (CXRs) play a pivotal role in diagnosing and monitoring cardiopulmonary diseases. However, lung opac- ities in CXRs frequently obscure anatomical structures, impeding clear identification of lung borders and complicating the localization of pathology. This challenge significantly hampers segmentation accuracy and precise lesion identification, which are crucial for diagnosis. To tackle these issues, our study proposes an unpaired CXR translation framework that converts CXRs with lung opacities into counterparts without lung opacities while preserving semantic features. Central to our approach is the use of adaptive activation masks to selectively modify opacity regions in lung CXRs. Cross-domain alignment ensures translated CXRs without opacity issues align with feature maps and prediction labels from a pre-trained CXR lesion classifier, facilitating the interpretability of the translation process. We validate our method using RSNA, MIMIC-CXR-JPG and JSRT datasets, demonstrating superior translation quality through lower Frechet Inception Distance (FID) and Kernel Inception Distance (KID) scores compared to existing meth- ods (FID: 67.18 vs. 210.4, KID: 0.01604 vs. 0.225). Evaluation on RSNA opacity, MIMIC acute respiratory distress syndrome (ARDS) patient CXRs and JSRT CXRs show our method enhances segmentation accuracy of lung borders and improves lesion classification, further underscoring its potential in clinical settings (RSNA: mIoU: 76.58% vs. 62.58%, Sensitivity: 85.58% vs. 77.03%; MIMIC ARDS: mIoU: 86.20% vs. 72.07%, Sensitivity: 92.68% vs. 86.85%; JSRT: mIoU: 91.08% vs. 85.6%, Sensitivity: 97.62% vs. 95.04%). Our approach advances CXR imaging analysis, especially in investigating segmentation impacts through image translation techniques.
Anatomy-Guided Radiology Report Generation with Pathology-Aware Regional Prompts
Nov 16, 2024



Radiology reporting generative AI holds significant potential to alleviate clinical workloads and streamline medical care. However, achieving high clinical accuracy is challenging, as radiological images often feature subtle lesions and intricate structures. Existing systems often fall short, largely due to their reliance on fixed size, patch-level image features and insufficient incorporation of pathological information. This can result in the neglect of such subtle patterns and inconsistent descriptions of crucial pathologies. To address these challenges, we propose an innovative approach that leverages pathology-aware regional prompts to explicitly integrate anatomical and pathological information of various scales, significantly enhancing the precision and clinical relevance of generated reports. We develop an anatomical region detector that extracts features from distinct anatomical areas, coupled with a novel multi-label lesion detector that identifies global pathologies. Our approach emulates the diagnostic process of radiologists, producing clinically accurate reports with comprehensive diagnostic capabilities. Experimental results show that our model outperforms previous state-of-the-art methods on most natural language generation and clinical efficacy metrics, with formal expert evaluations affirming its potential to enhance radiology practice.
Decoding Report Generators: A Cyclic Vision-Language Adapter for Counterfactual Explanations
Nov 08, 2024
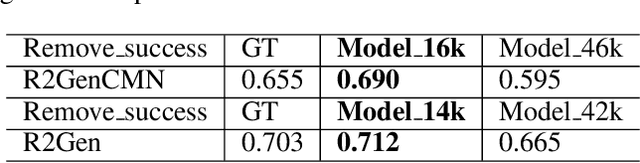
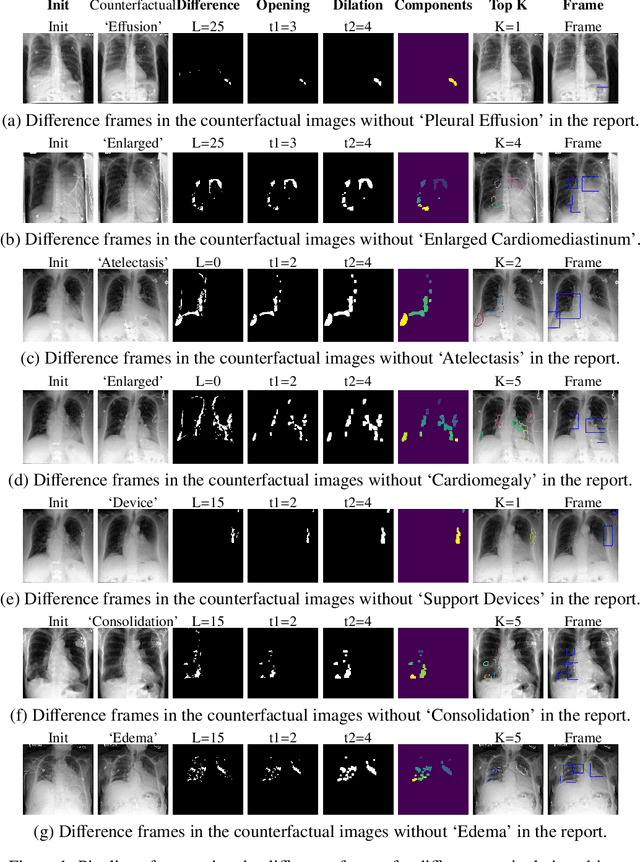
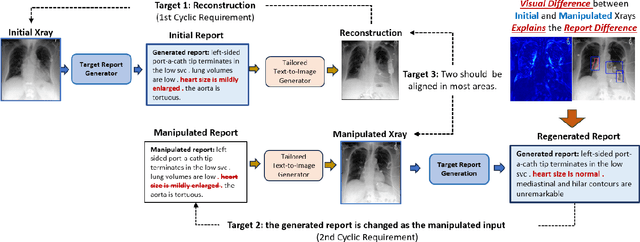
Despite significant advancements in report generation methods, a critical limitation remains: the lack of interpretability in the generated text. This paper introduces an innovative approach to enhance the explainability of text generated by report generation models. Our method employs cyclic text manipulation and visual comparison to identify and elucidate the features in the original content that influence the generated text. By manipulating the generated reports and producing corresponding images, we create a comparative framework that highlights key attributes and their impact on the text generation process. This approach not only identifies the image features aligned to the generated text but also improves transparency but also provides deeper insights into the decision-making mechanisms of the report generation models. Our findings demonstrate the potential of this method to significantly enhance the interpretability and transparency of AI-generated reports.