 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Models Unveil Patterns in Medical Images Through Vision-Language Conditioning
Paper and Code
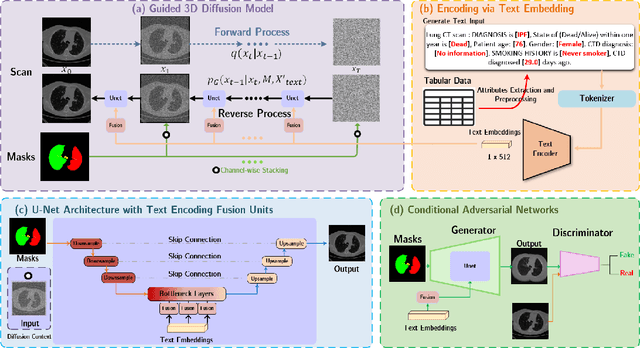



Deep generative models have significantly advanced medical imaging analysis by enhancing dataset size and quality. Beyond mere data augmentation, our research in this paper highlights an additional, significant capacity of deep generative models: their ability to reveal and demonstrate patterns in medical images. We employ a generative structure with hybrid conditions, combining clinical data and segmentation masks to guide the image synthesis process. Furthermore, we innovatively transformed the tabular clinical data into textual descriptions. This approach simplifies the handling of missing values and also enables us to leverage large pre-trained vision-language models that investigate the relations between independent clinical entries and comprehend general terms, such as gender and smoking status. Our approach differs from and presents a more challenging task than traditional medical report-guided synthesis due to the less visual correlation of our clinical information with the images. To overcome this, we introduce a text-visual embedding mechanism that strengthens the conditions, ensuring the network effectively utilizes the provided information. Our pipeline is generalizable to both GAN-based and diffusion models. Experiments on chest CT, particularly focusing on the smoking status, demonstrated a consistent intensity shift in the lungs which is in agreement with clinical observations, indicating the effectiveness of our method in capturing and visualizing the impact of specific attributes on medical image patterns. Our methods offer a new avenue for the early detection and precise visualization of complex clinical conditions with deep generative models. All codes are https://github.com/junzhin/DGM-VLC.