 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCS$^2$: A Controllable and Simultaneous Synthesizer of Images and Annotations with Minimal Human Intervention
Paper and Code
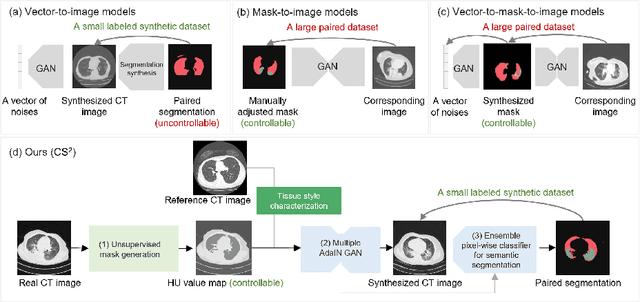
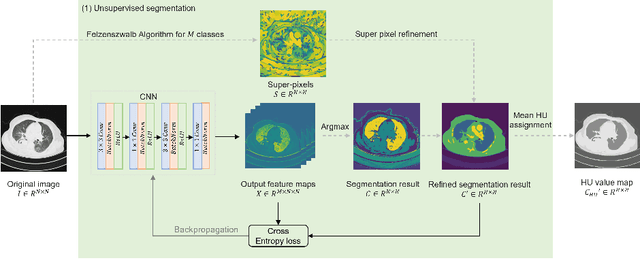

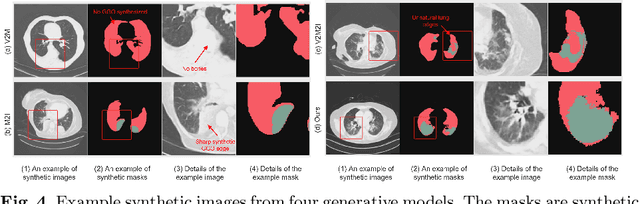
The destitution of image data and corresponding expert annotations limit the training capacities of AI diagnostic models and potentially inhibit their performance. To address such a problem of data and label scarcity, generative models have been developed to augment the training datasets. Previously proposed generative models usually require manually adjusted annotations (e.g., segmentation masks) or need pre-labeling. However, studies have found that these pre-labeling based methods can induce hallucinating artifacts, which might mislead the downstream clinical tasks, while manual adjustment could be onerous and subjective. To avoid manual adjustment and pre-labeling, we propose a novel controllable and simultaneous synthesizer (dubbed CS$^2$) in this study to generate both realistic images and corresponding annotations at the same time. Our CS$^2$ model is trained and validated using high resolution CT (HRCT) data collected from COVID-19 patients to realize an efficient infections segmentation with minimal human intervention. Our contributions include 1) a conditional image synthesis network that receives both style information from reference CT images and structural information from unsupervised segmentation masks, and 2) a corresponding segmentation mask synthesis network to automatically segment these synthesized images simultaneously. Our experimental studies on HRCT scans collected from COVID-19 patients demonstrate that our CS$^2$ model can lead to realistic synthesized datasets and promising segmentation results of COVID infections compared to the state-of-the-art nnUNet trained and fine-tuned in a fully supervised manner.