 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Unsupervised Mask-guided Annotated CT Image Synthesis with Minimum Manual Segmentations
Paper and Code
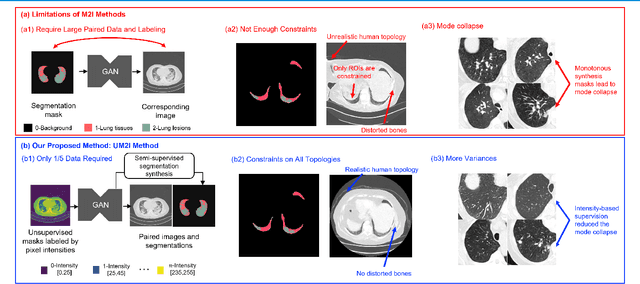
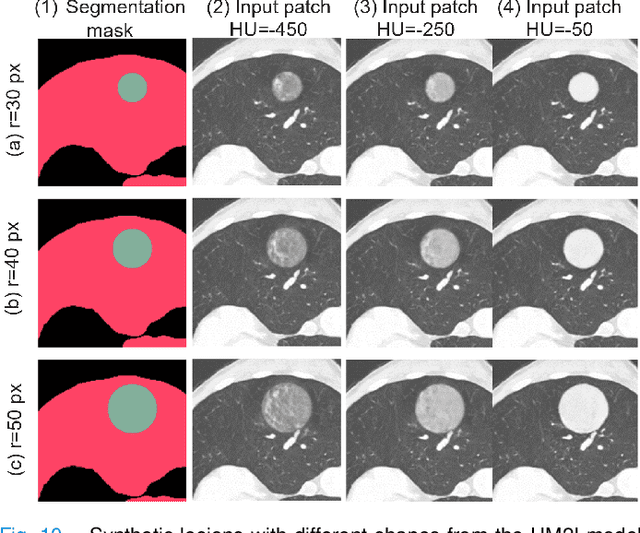
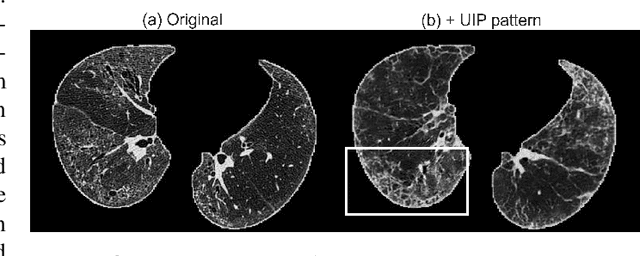
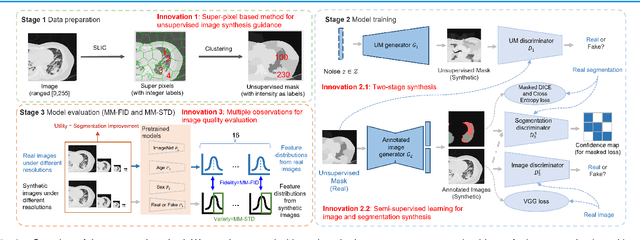
As a pragmatic data augmentation tool, data synthesis has generally returned dividends in performance for deep learning based medical image analysis. However, generating corresponding segmentation masks for synthetic medical images is laborious and subjective. To obtain paired synthetic medical images and segmentations, conditional generative models that use segmentation masks as synthesis conditions were proposed. However, these segmentation mask-conditioned generative models still relied on large, varied, and labeled training datasets, and they could only provide limited constraints on human anatomical structures, leading to unrealistic image features. Moreover, the invariant pixel-level conditions could reduce the variety of synthetic lesions and thus reduce the efficacy of data augmentation. To address these issues, in this work, we propose a novel strategy for medical image synthesis, namely Unsupervised Mask (UM)-guided synthesis, to obtain both synthetic images and segmentations using limited manual segmentation labels. We first develop a superpixel based algorithm to generate unsupervised structural guidance and then design a conditional generative model to synthesize images and annotations simultaneously from those unsupervised masks in a semi-supervised multi-task setting. In addition, we devise a multi-scale multi-task Fr\'echet Inception Distance (MM-FID) and multi-scale multi-task standard deviation (MM-STD) to harness both fidelity and variety evaluations of synthetic CT images. With multiple analyses on different scales, we could produce stable image quality measurements with high reproducibility. Compared with the segmentation mask guided synthesis, our UM-guided synthesis provided high-quality synthetic images with significantly higher fidelity, variety, and utility ($p<0.05$ by Wilcoxon Signed Ranked test).