 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Error-Guided Under-sampling Optimization for Multi-Contrast MRI Reconstruction
Jan 14, 2026Magnetic resonance imaging (MRI) plays a vital role in clinical diagnostics, yet it remains hindered by long acquisition times and motion artifacts. Multi-contrast MRI reconstruction has emerged as a promising direction by leveraging complementary information from fully-sampled reference scans. However, existing approaches suffer from three major limitations: (1) superficial reference fusion strategies, such as simple concatenation, (2) insufficient utilization of the complementary information provided by the reference contrast, and (3) fixed under-sampling patterns. We propose an efficient and interpretable frequency error-guided reconstruction framework to tackle these issues. We first employ a conditional diffusion model to learn a Frequency Error Prior (FEP), which is then incorporated into a unified framework for jointly optimizing both the under-sampling pattern and the reconstruction network. The proposed reconstruction model employs a model-driven deep unfolding framework that jointly exploits frequency- and image-domain information. In addition, a spatial alignment module and a reference feature decomposition strategy are incorporated to improve reconstruction quality and bridge model-based optimization with data-driven learning for improved physical interpretability. Comprehensive validation across multiple imaging modalities, acceleration rates (4-30x), and sampling schemes demonstrates consistent superiority over state-of-the-art methods in both quantitative metrics and visual quality. All codes are available at https://github.com/fangxinming/JUF-MRI.
Edge-guided Low-light Image Enhancement with Inertial Bregman Alternating Linearized Minimization
Mar 02, 2024
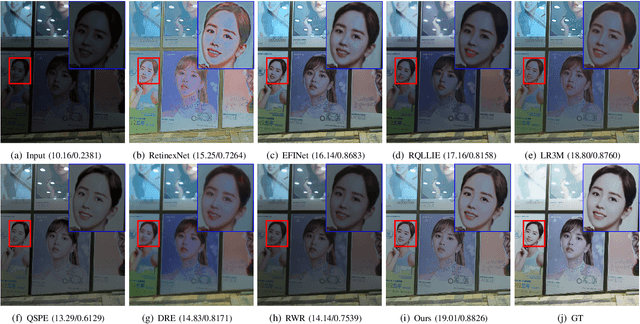


Prior-based methods for low-light image enhancement often face challenges in extracting available prior information from dim images. To overcome this limitation, we introduce a simple yet effective Retinex model with the proposed edge extraction prior. More specifically, we design an edge extraction network to capture the fine edge features from the low-light image directly. Building upon the Retinex theory, we decompose the low-light image into its illumination and reflectance components and introduce an edge-guided Retinex model for enhancing low-light images. To solve the proposed model, we propose a novel inertial Bregman alternating linearized minimization algorithm. This algorithm addresses the optimization problem associated with the edge-guided Retinex model, enabling effective enhancement of low-light images. Through rigorous theoretical analysis, we establish the convergence properties of the algorithm. Besides, we prove that the proposed algorithm converges to a stationary point of the problem through nonconvex optimization theory. Furthermore, extensive experiments are conducted on multiple real-world low-light image datasets to demonstrate the efficiency and superiority of the proposed scheme.
Dynamic Multimodal Information Bottleneck for Multimodality Classification
Nov 06, 2023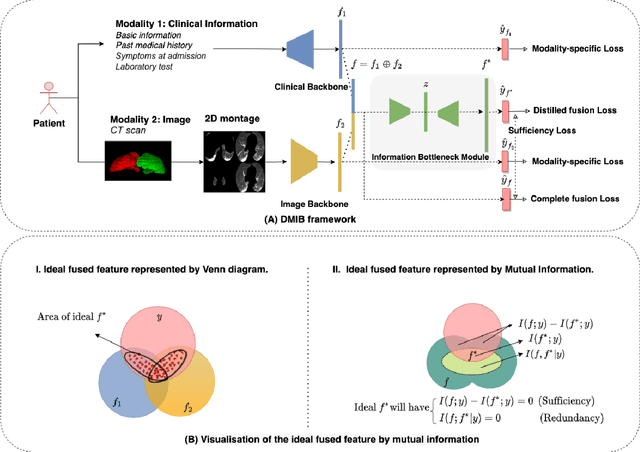

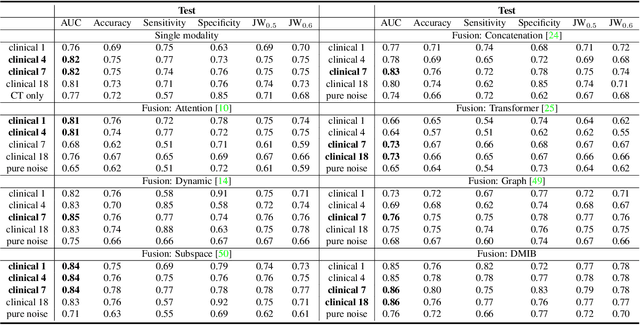
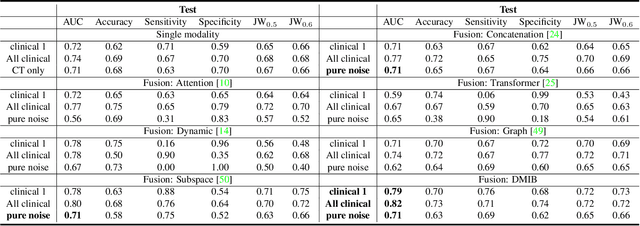
Effectively leveraging multimodal data such as various images, laboratory tests and clinical information is gaining traction in a variety of AI-based medical diagnosis and prognosis tasks. Most existing multi-modal techniques only focus on enhancing their performance by leveraging the differences or shared features from various modalities and fusing feature across different modalities. These approaches are generally not optimal for clinical settings, which pose the additional challenges of limited training data, as well as being rife with redundant data or noisy modality channels, leading to subpar performance. To address this gap, we study the robustness of existing methods to data redundancy and noise and propose a generalized dynamic multimodal information bottleneck framework for attaining a robust fused feature representation. Specifically, our information bottleneck module serves to filter out the task-irrelevant information and noises in the fused feature, and we further introduce a sufficiency loss to prevent dropping of task-relevant information, thus explicitly preserving the sufficiency of prediction information in the distilled feature. We validate our model on an in-house and a public COVID19 dataset for mortality prediction as well as two public biomedical datasets for diagnostic tasks. Extensive experiments show that our method surpasses the state-of-the-art and is significantly more robust, being the only method to remain performance when large-scale noisy channels exist. Our code is publicly available at https://github.com/BII-wushuang/DMIB.
Spherical Image Inpainting with Frame Transformation and Data-driven Prior Deep Networks
Sep 29, 2022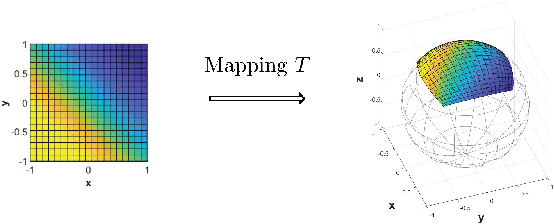
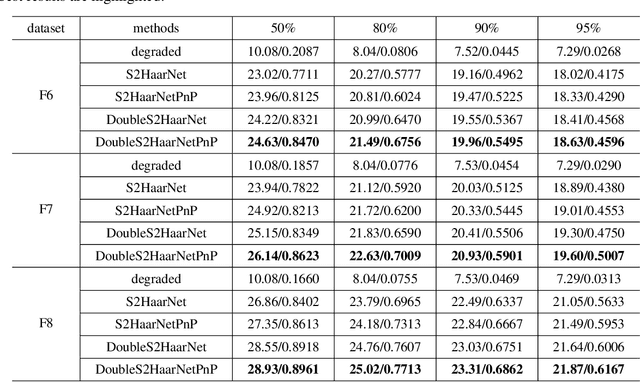
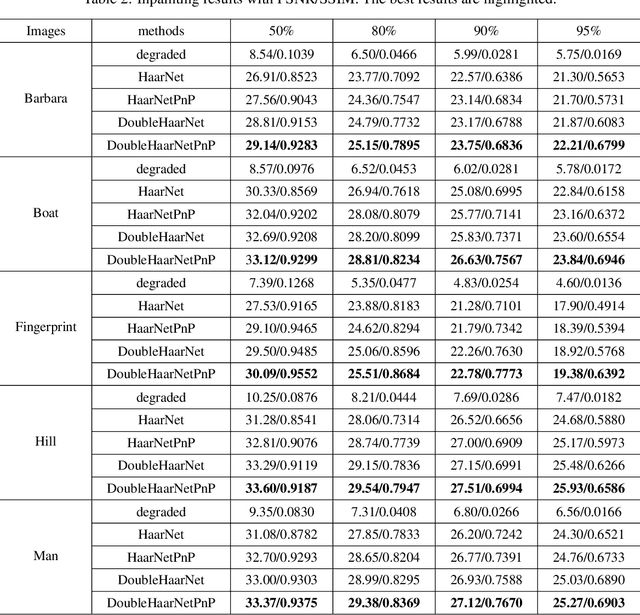
Spherical image processing has been widely applied in many important fields, such as omnidirectional vision for autonomous cars, global climate modelling, and medical imaging. It is non-trivial to extend an algorithm developed for flat images to the spherical ones. In this work, we focus on the challenging task of spherical image inpainting with deep learning-based regularizer. Instead of a naive application of existing models for planar images, we employ a fast directional spherical Haar framelet transform and develop a novel optimization framework based on a sparsity assumption of the framelet transform. Furthermore, by employing progressive encoder-decoder architecture, a new and better-performed deep CNN denoiser is carefully designed and works as an implicit regularizer. Finally, we use a plug-and-play method to handle the proposed optimization model, which can be implemented efficiently by training the CNN denoiser prior. Numerical experiments are conducted and show that the proposed algorithms can greatly recover damaged spherical images and achieve the best performance over purely using deep learning denoiser and plug-and-play model.