 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA level-wise training scheme for learning neural multigrid smoothers with application to integral equations
Mar 01, 2026Convolution-type integral equations commonly occur in signal processing and image processing. Discretizing these equations yields large and ill-conditioned linear systems. While the classic multigrid method is effective for solving linear systems derived from partial differential equations (PDE) problems, it fails to solve integral equations because its smoothers, which are implemented as conventional relaxation methods, are ineffective in reducing high-frequency components in the errors. We propose a novel neural multigrid scheme where learned neural operators replace classical smoothers. Unlike classical smoothers, these operators are trained offline. Once trained, the neural smoothers generalize to new right-hand-side vectors without retraining, making it an efficient solver. We design level-wise loss functions incorporating spectral filtering to emulate the multigrid frequency decomposition principle, ensuring each operator focuses on solving distinct high-frequency spectral bands. Although we focus on integral equations, the framework is generalizable to all kinds of problems, including PDE problems. Our experiments demonstrate superior efficiency over classical solvers and robust convergence across varying problem sizes and regularization weights.
Variational Bayesian Inference for Tensor Robust Principal Component Analysis
Dec 25, 2024



Tensor Robust Principal Component Analysis (TRPCA) holds a crucial position in machine learning and computer vision. It aims to recover underlying low-rank structures and characterizing the sparse structures of noise. Current approaches often encounter difficulties in accurately capturing the low-rank properties of tensors and balancing the trade-off between low-rank and sparse components, especially in a mixed-noise scenario. To address these challenges, we introduce a Bayesian framework for TRPCA, which integrates a low-rank tensor nuclear norm prior and a generalized sparsity-inducing prior. By embedding the proposed priors within the Bayesian framework, our method can automatically determine the optimal tensor nuclear norm and achieve a balance between the nuclear norm and sparse components. Furthermore, our method can be efficiently extended to the weighted tensor nuclear norm model. Experiments conducted on synthetic and real-world datasets demonstrate the effectiveness and superiority of our method compared to state-of-the-art approaches.
BP-DeepONet: A new method for cuffless blood pressure estimation using the physcis-informed DeepONet
Feb 29, 2024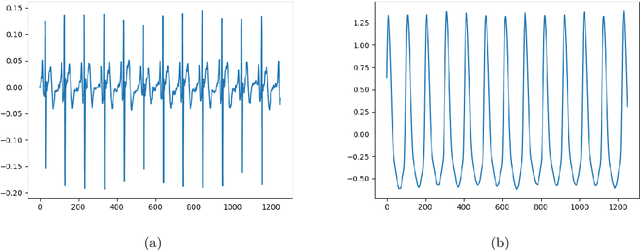

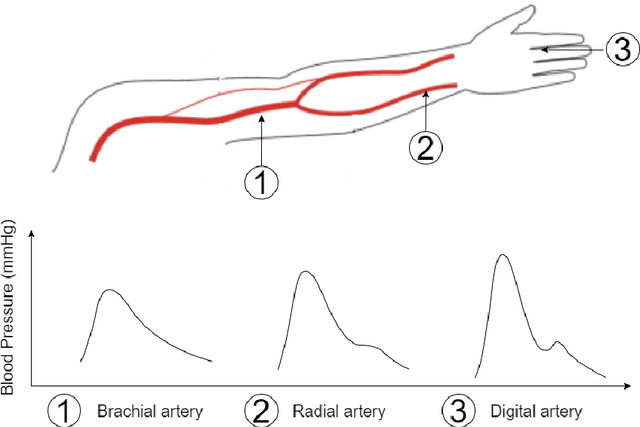
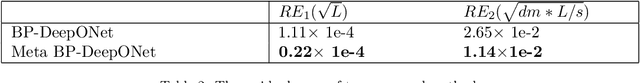
Cardiovascular diseases (CVDs) are the leading cause of death worldwide, with blood pressure serving as a crucial indicator. Arterial blood pressure (ABP) waveforms provide continuous pressure measurements throughout the cardiac cycle and offer valuable diagnostic insights. Consequently, there is a significant demand for non-invasive and cuff-less methods to measure ABP waveforms continuously. Accurate prediction of ABP waveforms can also improve the estimation of mean blood pressure, an essential cardiovascular health characteristic. This study proposes a novel framework based on the physics-informed DeepONet approach to predict ABP waveforms. Unlike previous methods, our approach requires the predicted ABP waveforms to satisfy the Navier-Stokes equation with a time-periodic condition and a Windkessel boundary condition. Notably, our framework is the first to predict ABP waveforms continuously, both with location and time, within the part of the artery that is being simulated. Furthermore, our method only requires ground truth data at the outlet boundary and can handle periodic conditions with varying periods. Incorporating the Windkessel boundary condition in our solution allows for generating natural physical reflection waves, which closely resemble measurements observed in real-world cases. Moreover, accurately estimating the hyper-parameters in the Navier-Stokes equation for our simulations poses a significant challenge. To overcome this obstacle, we introduce the concept of meta-learning, enabling the neural networks to learn these parameters during the training process.
VJT: A Video Transformer on Joint Tasks of Deblurring, Low-light Enhancement and Denoising
Jan 26, 2024Video restoration task aims to recover high-quality videos from low-quality observations. This contains various important sub-tasks, such as video denoising, deblurring and low-light enhancement, since video often faces different types of degradation, such as blur, low light, and noise. Even worse, these kinds of degradation could happen simultaneously when taking videos in extreme environments. This poses significant challenges if one wants to remove these artifacts at the same time. In this paper, to the best of our knowledge, we are the first to propose an efficient end-to-end video transformer approach for the joint task of video deblurring, low-light enhancement, and denoising. This work builds a novel multi-tier transformer where each tier uses a different level of degraded video as a target to learn the features of video effectively. Moreover, we carefully design a new tier-to-tier feature fusion scheme to learn video features incrementally and accelerate the training process with a suitable adaptive weighting scheme. We also provide a new Multiscene-Lowlight-Blur-Noise (MLBN) dataset, which is generated according to the characteristics of the joint task based on the RealBlur dataset and YouTube videos to simulate realistic scenes as far as possible. We have conducted extensive experiments, compared with many previous state-of-the-art methods, to show the effectiveness of our approach clearly.
Double-well Net for Image Segmentation
Dec 31, 2023In this study, our goal is to integrate classical mathematical models with deep neural networks by introducing two novel deep neural network models for image segmentation known as Double-well Nets. Drawing inspiration from the Potts model, our models leverage neural networks to represent a region force functional. We extend the well-know MBO (Merriman-Bence-Osher) scheme to solve the Potts model. The widely recognized Potts model is approximated using a double-well potential and then solved by an operator-splitting method, which turns out to be an extension of the well-known MBO scheme. Subsequently, we replace the region force functional in the Potts model with a UNet-type network, which is data-driven, and also introduce control variables to enhance effectiveness. The resulting algorithm is a neural network activated by a function that minimizes the double-well potential. What sets our proposed Double-well Nets apart from many existing deep learning methods for image segmentation is their strong mathematical foundation. They are derived from the network approximation theory and employ the MBO scheme to approximately solve the Potts model. By incorporating mathematical principles, Double-well Nets bridge the MBO scheme and neural networks, and offer an alternative perspective for designing networks with mathematical backgrounds. Through comprehensive experiments, we demonstrate the performance of Double-well Nets, showcasing their superior accuracy and robustness compared to state-of-the-art neural networks. Overall, our work represents a valuable contribution to the field of image segmentation by combining the strengths of classical variational models and deep neural networks. The Double-well Nets introduce an innovative approach that leverages mathematical foundations to enhance segmentation performance.
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models
Oct 18, 2023
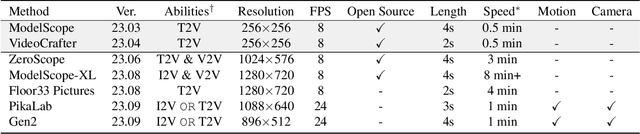

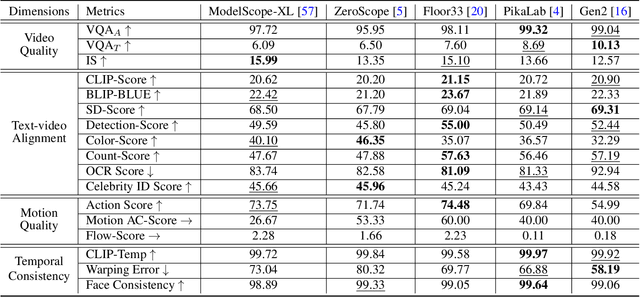
The vision and language generative models have been overgrown in recent years. For video generation, various open-sourced models and public-available services are released for generating high-visual quality videos. However, these methods often use a few academic metrics, for example, FVD or IS, to evaluate the performance. We argue that it is hard to judge the large conditional generative models from the simple metrics since these models are often trained on very large datasets with multi-aspect abilities. Thus, we propose a new framework and pipeline to exhaustively evaluate the performance of the generated videos. To achieve this, we first conduct a new prompt list for text-to-video generation by analyzing the real-world prompt list with the help of the large language model. Then, we evaluate the state-of-the-art video generative models on our carefully designed benchmarks, in terms of visual qualities, content qualities, motion qualities, and text-caption alignment with around 18 objective metrics. To obtain the final leaderboard of the models, we also fit a series of coefficients to align the objective metrics to the users' opinions. Based on the proposed opinion alignment method, our final score shows a higher correlation than simply averaging the metrics, showing the effectiveness of the proposed evaluation method.
Connections between Operator-splitting Methods and Deep Neural Networks with Applications in Image Segmentation
Jul 18, 2023Deep neural network is a powerful tool for many tasks. Understanding why it is so successful and providing a mathematical explanation is an important problem and has been one popular research direction in past years. In the literature of mathematical analysis of deep deep neural networks, a lot of works are dedicated to establishing representation theories. How to make connections between deep neural networks and mathematical algorithms is still under development. In this paper, we give an algorithmic explanation for deep neural networks, especially in their connection with operator splitting and multigrid methods. We show that with certain splitting strategies, operator-splitting methods have the same structure as networks. Utilizing this connection and the Potts model for image segmentation, two networks inspired by operator-splitting methods are proposed. The two networks are essentially two operator-splitting algorithms solving the Potts model. Numerical experiments are presented to demonstrate the effectiveness of the proposed networks.
PottsMGNet: A Mathematical Explanation of Encoder-Decoder Based Neural Networks
Jul 18, 2023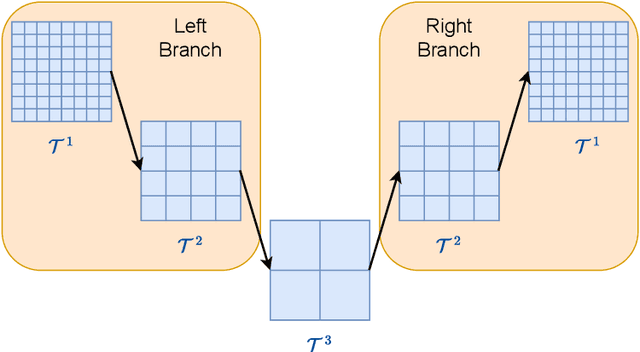
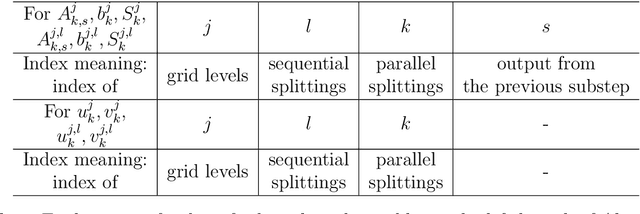
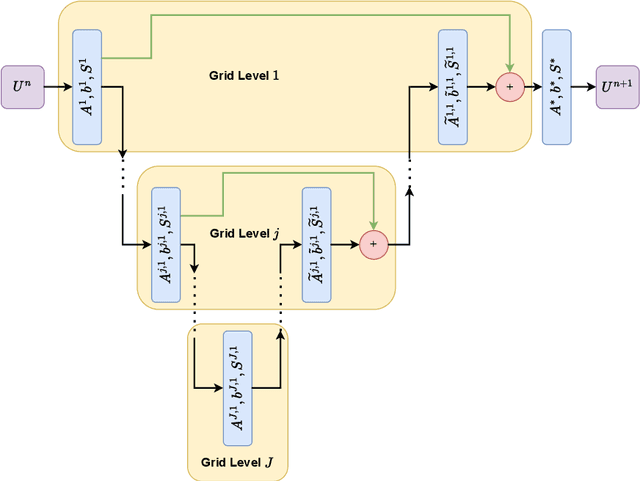
For problems in image processing and many other fields, a large class of effective neural networks has encoder-decoder-based architectures. Although these networks have made impressive performances, mathematical explanations of their architectures are still underdeveloped. In this paper, we study the encoder-decoder-based network architecture from the algorithmic perspective and provide a mathematical explanation. We use the two-phase Potts model for image segmentation as an example for our explanations. We associate the segmentation problem with a control problem in the continuous setting. Then, multigrid method and operator splitting scheme, the PottsMGNet, are used to discretize the continuous control model. We show that the resulting discrete PottsMGNet is equivalent to an encoder-decoder-based network. With minor modifications, it is shown that a number of the popular encoder-decoder-based neural networks are just instances of the proposed PottsMGNet. By incorporating the Soft-Threshold-Dynamics into the PottsMGNet as a regularizer, the PottsMGNet has shown to be robust with the network parameters such as network width and depth and achieved remarkable performance on datasets with very large noise. In nearly all our experiments, the new network always performs better or as good on accuracy and dice score than existing networks for image segmentation.
Dual-View Selective Instance Segmentation Network for Unstained Live Adherent Cells in Differential Interference Contrast Images
Jan 27, 2023



Despite recent advances in data-independent and deep-learning algorithms, unstained live adherent cell instance segmentation remains a long-standing challenge in cell image processing. Adherent cells' inherent visual characteristics, such as low contrast structures, fading edges, and irregular morphology, have made it difficult to distinguish from one another, even by human experts, let alone computational methods. In this study, we developed a novel deep-learning algorithm called dual-view selective instance segmentation network (DVSISN) for segmenting unstained adherent cells in differential interference contrast (DIC) images. First, we used a dual-view segmentation (DVS) method with pairs of original and rotated images to predict the bounding box and its corresponding mask for each cell instance. Second, we used a mask selection (MS) method to filter the cell instances predicted by the DVS to keep masks closest to the ground truth only. The developed algorithm was trained and validated on our dataset containing 520 images and 12198 cells. Experimental results demonstrate that our algorithm achieves an AP_segm of 0.555, which remarkably overtakes a benchmark by a margin of 23.6%. This study's success opens up a new possibility of using rotated images as input for better prediction in cell images.
Spherical Image Inpainting with Frame Transformation and Data-driven Prior Deep Networks
Sep 29, 2022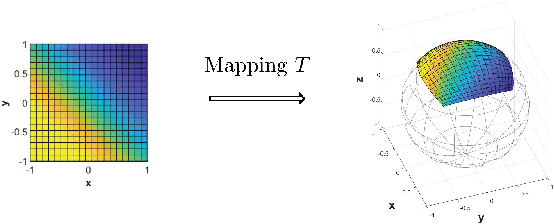
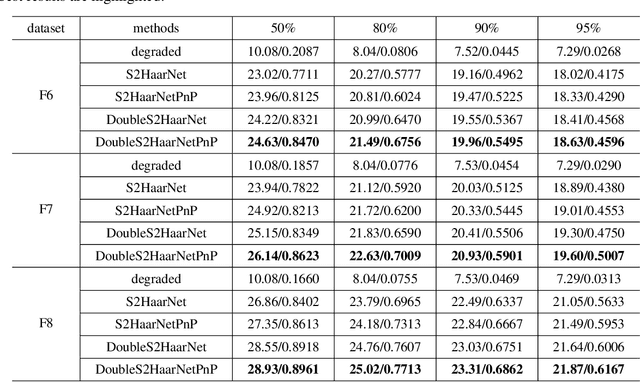
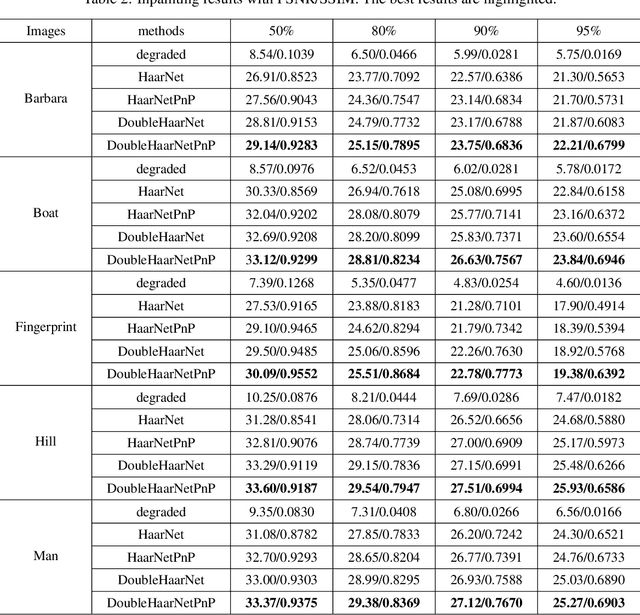
Spherical image processing has been widely applied in many important fields, such as omnidirectional vision for autonomous cars, global climate modelling, and medical imaging. It is non-trivial to extend an algorithm developed for flat images to the spherical ones. In this work, we focus on the challenging task of spherical image inpainting with deep learning-based regularizer. Instead of a naive application of existing models for planar images, we employ a fast directional spherical Haar framelet transform and develop a novel optimization framework based on a sparsity assumption of the framelet transform. Furthermore, by employing progressive encoder-decoder architecture, a new and better-performed deep CNN denoiser is carefully designed and works as an implicit regularizer. Finally, we use a plug-and-play method to handle the proposed optimization model, which can be implemented efficiently by training the CNN denoiser prior. Numerical experiments are conducted and show that the proposed algorithms can greatly recover damaged spherical images and achieve the best performance over purely using deep learning denoiser and plug-and-play model.