 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRBench: End-to-end Paper Reproduction in Physics Research
Mar 29, 2026AI agents powered by large language models exhibit strong reasoning and problem-solving capabilities, enabling them to assist scientific research tasks such as formula derivation and code generation. However, whether these agents can reliably perform end-to-end reproduction from real scientific papers remains an open question. We introduce PRBench, a benchmark of 30 expert-curated tasks spanning 11 subfields of physics. Each task requires an agent to comprehend the methodology of a published paper, implement the corresponding algorithms from scratch, and produce quantitative results matching the original publication. Agents are provided only with the task instruction and paper content, and operate in a sandboxed execution environment. All tasks are contributed by domain experts from over 20 research groups at the School of Physics, Peking University, each grounded in a real published paper and validated through end-to-end reproduction with verified ground-truth results and detailed scoring rubrics. Using an agentified assessment pipeline, we evaluate a set of coding agents on PRBench and analyze their capabilities across key dimensions of scientific reasoning and execution. The best-performing agent, OpenAI Codex powered by GPT-5.3-Codex, achieves a mean overall score of 34%. All agents exhibit a zero end-to-end callback success rate, with particularly poor performance in data accuracy and code correctness. We further identify systematic failure modes, including errors in formula implementation, inability to debug numerical simulations, and fabrication of output data. Overall, PRBench provides a rigorous benchmark for evaluating progress toward autonomous scientific research.
GRAIL:Learning to Interact with Large Knowledge Graphs for Retrieval Augmented Reasoning
Aug 07, 2025Large Language Models (LLMs) integrated with Retrieval-Augmented Generation (RAG) techniques have exhibited remarkable performance across a wide range of domains. However, existing RAG approaches primarily operate on unstructured data and demonstrate limited capability in handling structured knowledge such as knowledge graphs. Meanwhile, current graph retrieval methods fundamentally struggle to capture holistic graph structures while simultaneously facing precision control challenges that manifest as either critical information gaps or excessive redundant connections, collectively undermining reasoning performance. To address this challenge, we propose GRAIL: Graph-Retrieval Augmented Interactive Learning, a framework designed to interact with large-scale graphs for retrieval-augmented reasoning. Specifically, GRAIL integrates LLM-guided random exploration with path filtering to establish a data synthesis pipeline, where a fine-grained reasoning trajectory is automatically generated for each task. Based on the synthesized data, we then employ a two-stage training process to learn a policy that dynamically decides the optimal actions at each reasoning step. The overall objective of precision-conciseness balance in graph retrieval is decoupled into fine-grained process-supervised rewards to enhance data efficiency and training stability. In practical deployment, GRAIL adopts an interactive retrieval paradigm, enabling the model to autonomously explore graph paths while dynamically balancing retrieval breadth and precision. Extensive experiments have shown that GRAIL achieves an average accuracy improvement of 21.01% and F1 improvement of 22.43% on three knowledge graph question-answering datasets. Our source code and datasets is available at https://github.com/Changgeww/GRAIL.
Time's Up! An Empirical Study of LLM Reasoning Ability Under Output Length Constraint
Apr 22, 2025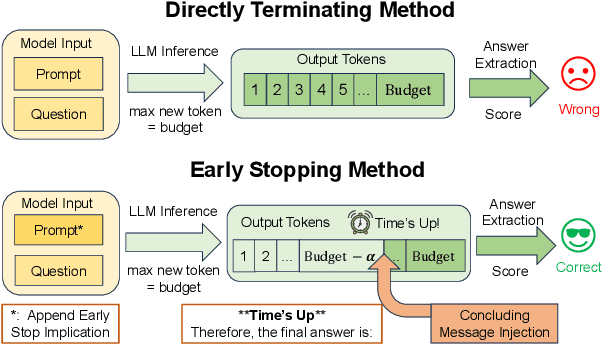
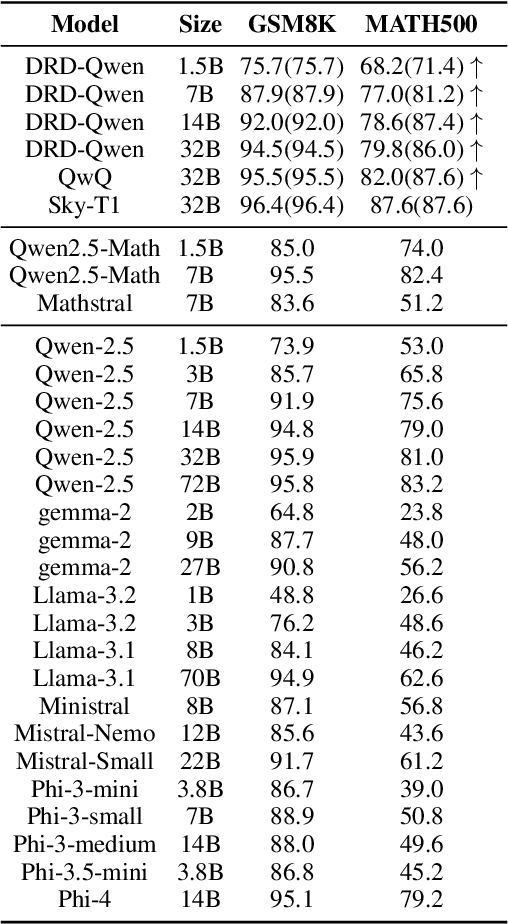
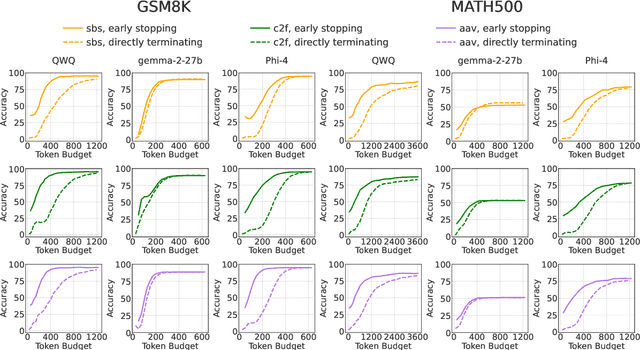
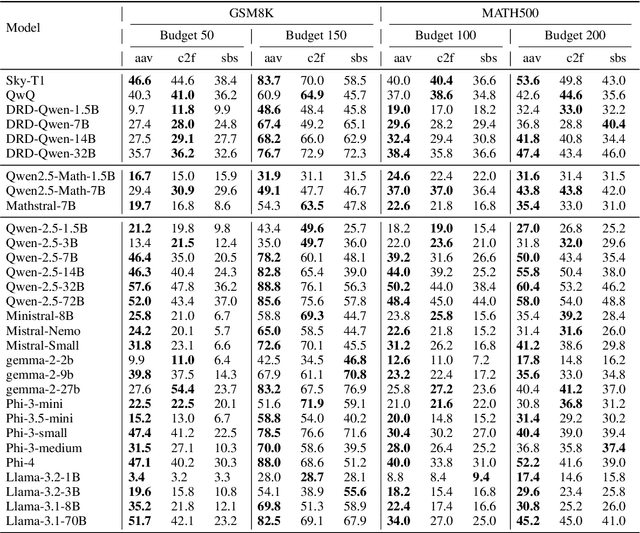
Recent work has demonstrated the remarkable potential of Large Language Models (LLMs) in test-time scaling. By making the models think before answering, they are able to achieve much higher accuracy with extra inference computation. However, in many real-world scenarios, models are used under time constraints, where an answer should be given to the user within a certain output length. It is unclear whether and how the reasoning abilities of LLMs remain effective under such constraints. We take a first look at this problem by conducting an in-depth empirical study. Specifically, we test more than 25 LLMs on common reasoning datasets under a wide range of output length budgets, and we analyze the correlation between the inference accuracy and various properties including model type, model size, prompt style, etc. We also consider the mappings between the token budgets and the actual on-device latency budgets. The results have demonstrated several interesting findings regarding the budget-aware LLM reasoning that differ from the unconstrained situation, e.g. the optimal choices of model sizes and prompts change under different budgets. These findings offer practical guidance for users to deploy LLMs under real-world latency constraints.
Data Center Cooling System Optimization Using Offline Reinforcement Learning
Jan 25, 2025



The recent advances in information technology and artificial intelligence have fueled a rapid expansion of the data center (DC) industry worldwide, accompanied by an immense appetite for electricity to power the DCs. In a typical DC, around 30~40% of the energy is spent on the cooling system rather than on computer servers, posing a pressing need for developing new energy-saving optimization technologies for DC cooling systems. However, optimizing such real-world industrial systems faces numerous challenges, including but not limited to a lack of reliable simulation environments, limited historical data, and stringent safety and control robustness requirements. In this work, we present a novel physics-informed offline reinforcement learning (RL) framework for energy efficiency optimization of DC cooling systems. The proposed framework models the complex dynamical patterns and physical dependencies inside a server room using a purposely designed graph neural network architecture that is compliant with the fundamental time-reversal symmetry. Because of its well-behaved and generalizable state-action representations, the model enables sample-efficient and robust latent space offline policy learning using limited real-world operational data. Our framework has been successfully deployed and verified in a large-scale production DC for closed-loop control of its air-cooling units (ACUs). We conducted a total of 2000 hours of short and long-term experiments in the production DC environment. The results show that our method achieves 14~21% energy savings in the DC cooling system, without any violation of the safety or operational constraints. Our results have demonstrated the significant potential of offline RL in solving a broad range of data-limited, safety-critical real-world industrial control problems.
Variational Bayesian Inference for Tensor Robust Principal Component Analysis
Dec 25, 2024



Tensor Robust Principal Component Analysis (TRPCA) holds a crucial position in machine learning and computer vision. It aims to recover underlying low-rank structures and characterizing the sparse structures of noise. Current approaches often encounter difficulties in accurately capturing the low-rank properties of tensors and balancing the trade-off between low-rank and sparse components, especially in a mixed-noise scenario. To address these challenges, we introduce a Bayesian framework for TRPCA, which integrates a low-rank tensor nuclear norm prior and a generalized sparsity-inducing prior. By embedding the proposed priors within the Bayesian framework, our method can automatically determine the optimal tensor nuclear norm and achieve a balance between the nuclear norm and sparse components. Furthermore, our method can be efficiently extended to the weighted tensor nuclear norm model. Experiments conducted on synthetic and real-world datasets demonstrate the effectiveness and superiority of our method compared to state-of-the-art approaches.
AdaptDHM: Adaptive Distribution Hierarchical Model for Multi-Domain CTR Prediction
Nov 22, 2022



Large-scale commercial platforms usually involve numerous business domains for diverse business strategies and expect their recommendation systems to provide click-through rate (CTR) predictions for multiple domains simultaneously. Existing promising and widely-used multi-domain models discover domain relationships by explicitly constructing domain-specific networks, but the computation and memory boost significantly with the increase of domains. To reduce computational complexity, manually grouping domains with particular business strategies is common in industrial applications. However, this pre-defined data partitioning way heavily relies on prior knowledge, and it may neglect the underlying data distribution of each domain, hence limiting the model's representation capability. Regarding the above issues, we propose an elegant and flexible multi-distribution modeling paradigm, named Adaptive Distribution Hierarchical Model (AdaptDHM), which is an end-to-end optimization hierarchical structure consisting of a clustering process and classification process. Specifically, we design a distribution adaptation module with a customized dynamic routing mechanism. Instead of introducing prior knowledge for pre-defined data allocation, this routing algorithm adaptively provides a distribution coefficient for each sample to determine which cluster it belongs to. Each cluster corresponds to a particular distribution so that the model can sufficiently capture the commonalities and distinctions between these distinct clusters. Extensive experiments on both public and large-scale Alibaba industrial datasets verify the effectiveness and efficiency of AdaptDHM: Our model achieves impressive prediction accuracy and its time cost during the training stage is more than 50% less than that of other models.