 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrayscale Data Construction and Multi-Level Ranking Objective for Dialogue Response Selection
Paper and Code
Apr 28, 2020
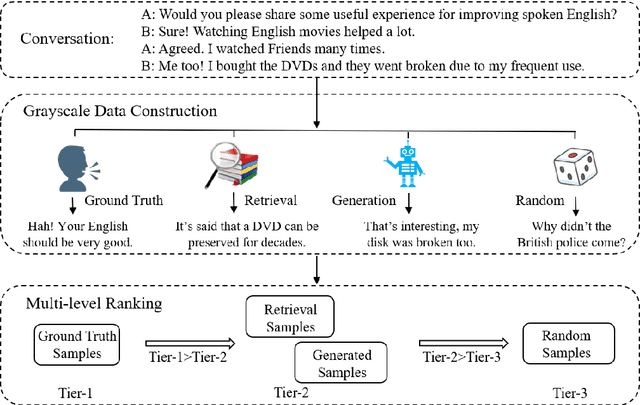
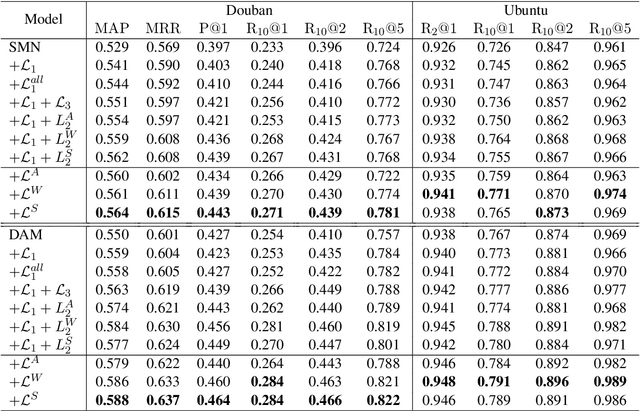
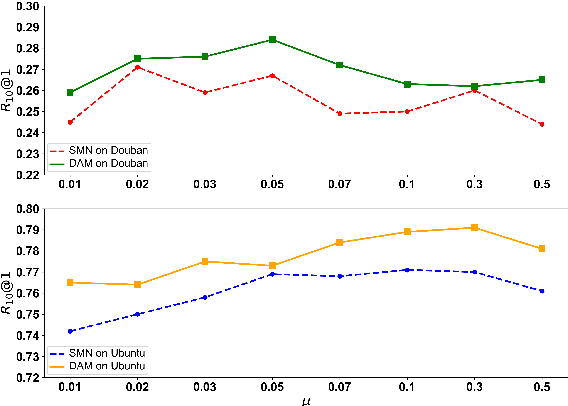
Response selection plays a vital role in building retrieval-based conversation systems. Recent works on enhancing response selection mainly focus on inventing new neural architectures for better modeling the relation between dialogue context and response candidates. In almost all these previous works, binary-labeled training data are assumed: Every response candidate is either positive (relevant) or negative (irrelevant). We propose to automatically build training data with grayscale labels. To make full use of the grayscale training data, we propose a multi-level ranking strategy. Experimental results on two benchmark datasets show that our new training strategy significantly improves performance over existing state-of-the-art matching models in terms of various evaluation metrics.