 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUPS: Point Cloud Unified Panoptic Segmentation
Feb 28, 2023Point cloud panoptic segmentation is a challenging task that seeks a holistic solution for both semantic and instance segmentation to predict groupings of coherent points. Previous approaches treat semantic and instance segmentation as surrogate tasks, and they either use clustering methods or bounding boxes to gather instance groupings with costly computation and hand-crafted designs in the instance segmentation task. In this paper, we propose a simple but effective point cloud unified panoptic segmentation (PUPS) framework, which use a set of point-level classifiers to directly predict semantic and instance groupings in an end-to-end manner. To realize PUPS, we introduce bipartite matching to our training pipeline so that our classifiers are able to exclusively predict groupings of instances, getting rid of hand-crafted designs, e.g. anchors and Non-Maximum Suppression (NMS). In order to achieve better grouping results, we utilize a transformer decoder to iteratively refine the point classifiers and develop a context-aware CutMix augmentation to overcome the class imbalance problem. As a result, PUPS achieves 1st place on the leader board of SemanticKITTI panoptic segmentation task and state-of-the-art results on nuScenes.
When Video Classification Meets Incremental Classes
Jun 30, 2021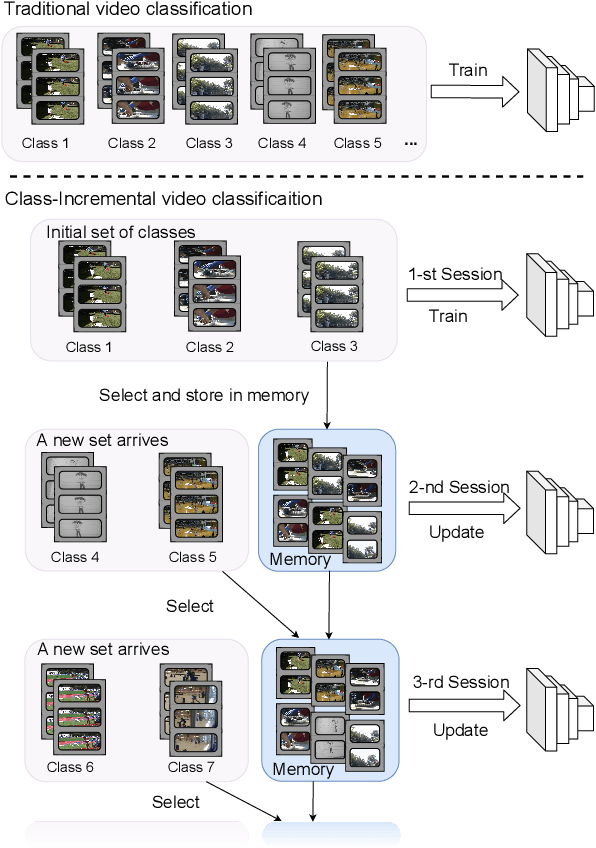

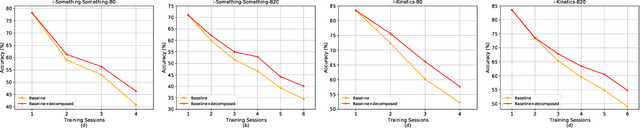
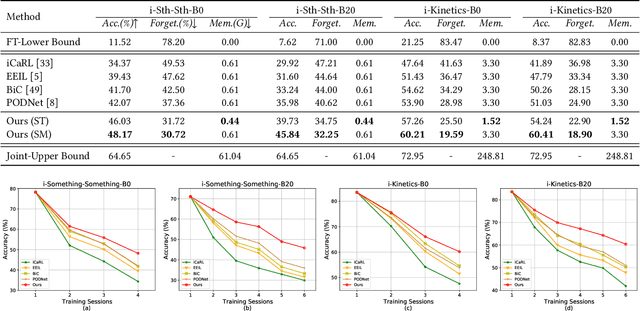
With the rapid development of social media, tremendous videos with new classes are generated daily, which raise an urgent demand for video classification methods that can continuously update new classes while maintaining the knowledge of old videos with limited storage and computing resources. In this paper, we summarize this task as \textit{Class-Incremental Video Classification (CIVC)} and propose a novel framework to address it. As a subarea of incremental learning tasks, the challenge of \textit{catastrophic forgetting} is unavoidable in CIVC. To better alleviate it, we utilize some characteristics of videos. First, we decompose the spatio-temporal knowledge before distillation rather than treating it as a whole in the knowledge transfer process; trajectory is also used to refine the decomposition. Second, we propose a dual granularity exemplar selection method to select and store representative video instances of old classes and key-frames inside videos under a tight storage budget. We benchmark our method and previous SOTA class-incremental learning methods on Something-Something V2 and Kinetics datasets, and our method outperforms previous methods significantly.