 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEXTS-Diff: TEXTS-Aware Diffusion Model for Real-World Text Image Super-Resolution
Jan 24, 2026Real-world text image super-resolution aims to restore overall visual quality and text legibility in images suffering from diverse degradations and text distortions. However, the scarcity of text image data in existing datasets results in poor performance on text regions. In addition, datasets consisting of isolated text samples limit the quality of background reconstruction. To address these limitations, we construct Real-Texts, a large-scale, high-quality dataset collected from real-world images, which covers diverse scenarios and contains natural text instances in both Chinese and English. Additionally, we propose the TEXTS-Aware Diffusion Model (TEXTS-Diff) to achieve high-quality generation in both background and textual regions. This approach leverages abstract concepts to improve the understanding of textual elements within visual scenes and concrete text regions to enhance textual details. It mitigates distortions and hallucination artifacts commonly observed in text regions, while preserving high-quality visual scene fidelity. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple evaluation metrics, exhibiting superior generalization ability and text restoration accuracy in complex scenarios. All the code, model, and dataset will be released.
RoPETR: Improving Temporal Camera-Only 3D Detection by Integrating Enhanced Rotary Position Embedding
Apr 18, 2025This technical report introduces a targeted improvement to the StreamPETR framework, specifically aimed at enhancing velocity estimation, a critical factor influencing the overall NuScenes Detection Score. While StreamPETR exhibits strong 3D bounding box detection performance as reflected by its high mean Average Precision our analysis identified velocity estimation as a substantial bottleneck when evaluated on the NuScenes dataset. To overcome this limitation, we propose a customized positional embedding strategy tailored to enhance temporal modeling capabilities. Experimental evaluations conducted on the NuScenes test set demonstrate that our improved approach achieves a state-of-the-art NDS of 70.86% using the ViT-L backbone, setting a new benchmark for camera-only 3D object detection.
UdeerLID+: Integrating LiDAR, Image, and Relative Depth with Semi-Supervised
Sep 10, 2024Road segmentation is a critical task for autonomous driving systems, requiring accurate and robust methods to classify road surfaces from various environmental data. Our work introduces an innovative approach that integrates LiDAR point cloud data, visual image, and relative depth maps derived from images. The integration of multiple data sources in road segmentation presents both opportunities and challenges. One of the primary challenges is the scarcity of large-scale, accurately labeled datasets that are necessary for training robust deep learning models. To address this, we have developed the [UdeerLID+] framework under a semi-supervised learning paradigm. Experiments results on KITTI datasets validate the superior performance.
MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers
Aug 13, 2024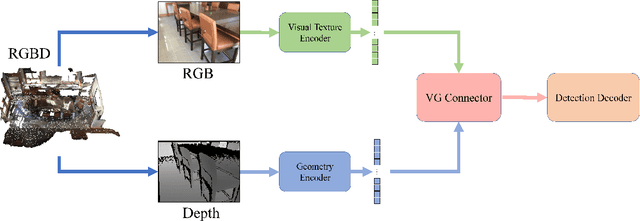
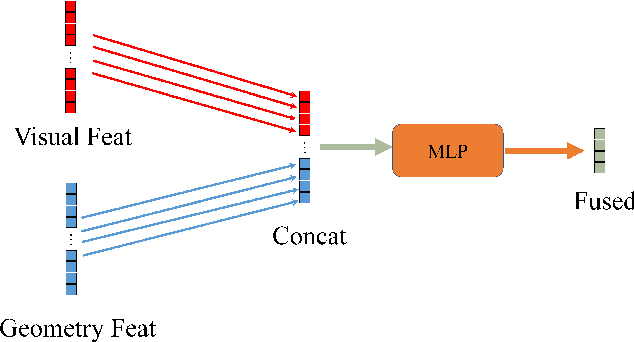
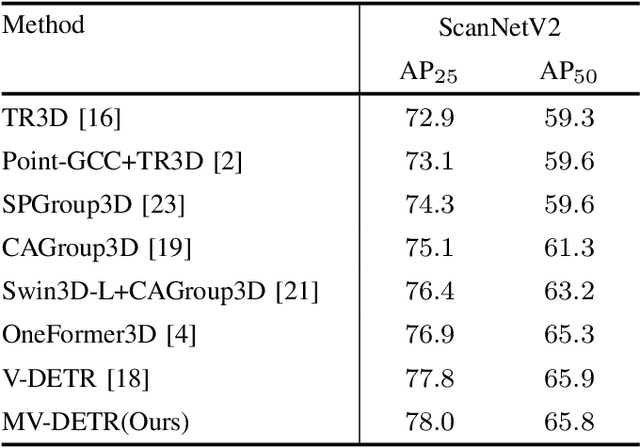
We introduce a novel MV-DETR pipeline which is effective while efficient transformer based detection method. Given input RGBD data, we notice that there are super strong pretraining weights for RGB data while less effective works for depth related data. First and foremost , we argue that geometry and texture cues are both of vital importance while could be encoded separately. Secondly, we find that visual texture feature is relatively hard to extract compared with geometry feature in 3d space. Unfortunately, single RGBD dataset with thousands of data is not enough for training an discriminating filter for visual texture feature extraction. Last but certainly not the least, we designed a lightweight VG module consists of a visual textual encoder, a geometry encoder and a VG connector. Compared with previous state of the art works like V-DETR, gains from pretrained visual encoder could be seen. Extensive experiments on ScanNetV2 dataset shows the effectiveness of our method. It is worth mentioned that our method achieve 78\% AP which create new state of the art on ScanNetv2 benchmark.
LVIC: Multi-modality segmentation by Lifting Visual Info as Cue
Mar 08, 2024


Multi-modality fusion is proven an effective method for 3d perception for autonomous driving. However, most current multi-modality fusion pipelines for LiDAR semantic segmentation have complicated fusion mechanisms. Point painting is a quite straight forward method which directly bind LiDAR points with visual information. Unfortunately, previous point painting like methods suffer from projection error between camera and LiDAR. In our experiments, we find that this projection error is the devil in point painting. As a result of that, we propose a depth aware point painting mechanism, which significantly boosts the multi-modality fusion. Apart from that, we take a deeper look at the desired visual feature for LiDAR to operate semantic segmentation. By Lifting Visual Information as Cue, LVIC ranks 1st on nuScenes LiDAR semantic segmentation benchmark. Our experiments show the robustness and effectiveness. Codes would be make publicly available soon.
PeP: a Point enhanced Painting method for unified point cloud tasks
Oct 11, 2023


Point encoder is of vital importance for point cloud recognition. As the very beginning step of whole model pipeline, adding features from diverse sources and providing stronger feature encoding mechanism would provide better input for downstream modules. In our work, we proposed a novel PeP module to tackle above issue. PeP contains two main parts, a refined point painting method and a LM-based point encoder. Experiments results on the nuScenes and KITTI datasets validate the superior performance of our PeP. The advantages leads to strong performance on both semantic segmentation and object detection, in both lidar and multi-modal settings. Notably, our PeP module is model agnostic and plug-and-play. Our code will be publicly available soon.
Low-Resolution Self-Attention for Semantic Segmentation
Oct 08, 2023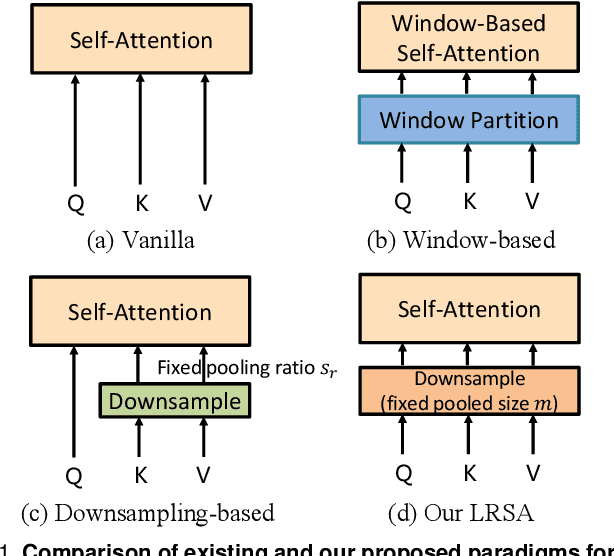
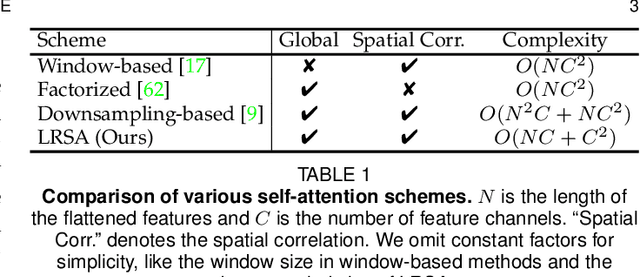
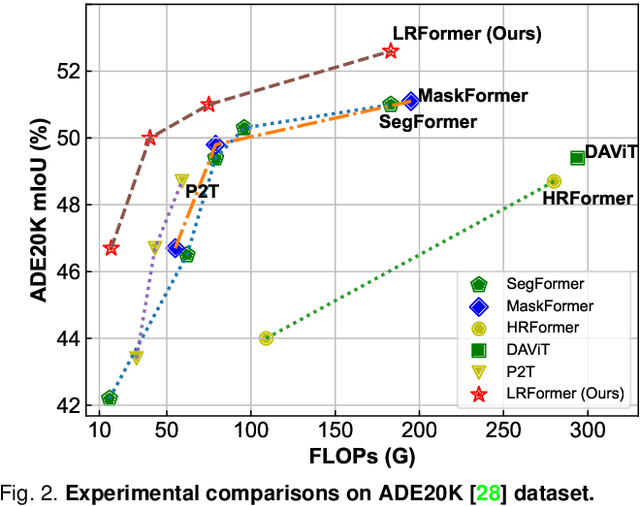

Semantic segmentation tasks naturally require high-resolution information for pixel-wise segmentation and global context information for class prediction. While existing vision transformers demonstrate promising performance, they often utilize high resolution context modeling, resulting in a computational bottleneck. In this work, we challenge conventional wisdom and introduce the Low-Resolution Self-Attention (LRSA) mechanism to capture global context at a significantly reduced computational cost. Our approach involves computing self-attention in a fixed low-resolution space regardless of the input image's resolution, with additional 3x3 depth-wise convolutions to capture fine details in the high-resolution space. We demonstrate the effectiveness of our LRSA approach by building the LRFormer, a vision transformer with an encoder-decoder structure. Extensive experiments on the ADE20K, COCO-Stuff, and Cityscapes datasets demonstrate that LRFormer outperforms state-of-the-art models. The code will be made available at https://github.com/yuhuan-wu/LRFormer.
Construction of Paired Knowledge Graph-Text Datasets Informed by Cyclic Evaluation
Sep 20, 2023



Datasets that pair Knowledge Graphs (KG) and text together (KG-T) can be used to train forward and reverse neural models that generate text from KG and vice versa. However models trained on datasets where KG and text pairs are not equivalent can suffer from more hallucination and poorer recall. In this paper, we verify this empirically by generating datasets with different levels of noise and find that noisier datasets do indeed lead to more hallucination. We argue that the ability of forward and reverse models trained on a dataset to cyclically regenerate source KG or text is a proxy for the equivalence between the KG and the text in the dataset. Using cyclic evaluation we find that manually created WebNLG is much better than automatically created TeKGen and T-REx. Guided by these observations, we construct a new, improved dataset called LAGRANGE using heuristics meant to improve equivalence between KG and text and show the impact of each of the heuristics on cyclic evaluation. We also construct two synthetic datasets using large language models (LLMs), and observe that these are conducive to models that perform significantly well on cyclic generation of text, but less so on cyclic generation of KGs, probably because of a lack of a consistent underlying ontology.
HuBo-VLM: Unified Vision-Language Model designed for HUman roBOt interaction tasks
Aug 24, 2023

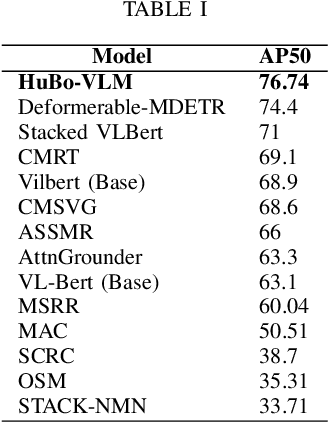
Human robot interaction is an exciting task, which aimed to guide robots following instructions from human. Since huge gap lies between human natural language and machine codes, end to end human robot interaction models is fair challenging. Further, visual information receiving from sensors of robot is also a hard language for robot to perceive. In this work, HuBo-VLM is proposed to tackle perception tasks associated with human robot interaction including object detection and visual grounding by a unified transformer based vision language model. Extensive experiments on the Talk2Car benchmark demonstrate the effectiveness of our approach. Code would be publicly available in https://github.com/dzcgaara/HuBo-VLM.
PUPS: Point Cloud Unified Panoptic Segmentation
Feb 28, 2023Point cloud panoptic segmentation is a challenging task that seeks a holistic solution for both semantic and instance segmentation to predict groupings of coherent points. Previous approaches treat semantic and instance segmentation as surrogate tasks, and they either use clustering methods or bounding boxes to gather instance groupings with costly computation and hand-crafted designs in the instance segmentation task. In this paper, we propose a simple but effective point cloud unified panoptic segmentation (PUPS) framework, which use a set of point-level classifiers to directly predict semantic and instance groupings in an end-to-end manner. To realize PUPS, we introduce bipartite matching to our training pipeline so that our classifiers are able to exclusively predict groupings of instances, getting rid of hand-crafted designs, e.g. anchors and Non-Maximum Suppression (NMS). In order to achieve better grouping results, we utilize a transformer decoder to iteratively refine the point classifiers and develop a context-aware CutMix augmentation to overcome the class imbalance problem. As a result, PUPS achieves 1st place on the leader board of SemanticKITTI panoptic segmentation task and state-of-the-art results on nuScenes.