Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuBo-VLM: Unified Vision-Language Model designed for HUman roBOt interaction tasks
Paper and Code


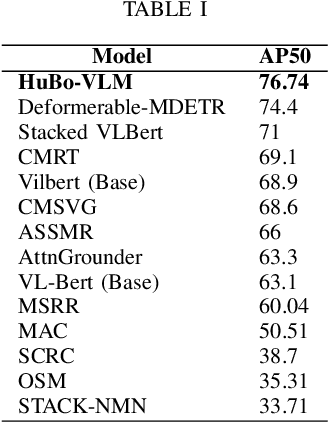
Human robot interaction is an exciting task, which aimed to guide robots following instructions from human. Since huge gap lies between human natural language and machine codes, end to end human robot interaction models is fair challenging. Further, visual information receiving from sensors of robot is also a hard language for robot to perceive. In this work, HuBo-VLM is proposed to tackle perception tasks associated with human robot interaction including object detection and visual grounding by a unified transformer based vision language model. Extensive experiments on the Talk2Car benchmark demonstrate the effectiveness of our approach. Code would be publicly available in https://github.com/dzcgaara/HuBo-VLM.
View paper on