 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoPETR: Improving Temporal Camera-Only 3D Detection by Integrating Enhanced Rotary Position Embedding
Apr 18, 2025This technical report introduces a targeted improvement to the StreamPETR framework, specifically aimed at enhancing velocity estimation, a critical factor influencing the overall NuScenes Detection Score. While StreamPETR exhibits strong 3D bounding box detection performance as reflected by its high mean Average Precision our analysis identified velocity estimation as a substantial bottleneck when evaluated on the NuScenes dataset. To overcome this limitation, we propose a customized positional embedding strategy tailored to enhance temporal modeling capabilities. Experimental evaluations conducted on the NuScenes test set demonstrate that our improved approach achieves a state-of-the-art NDS of 70.86% using the ViT-L backbone, setting a new benchmark for camera-only 3D object detection.
MV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers
Aug 13, 2024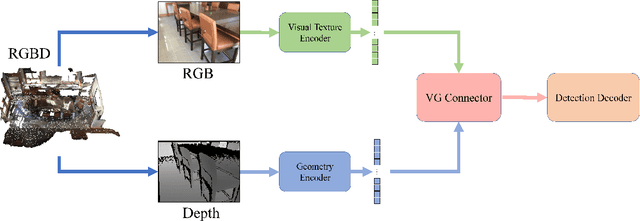
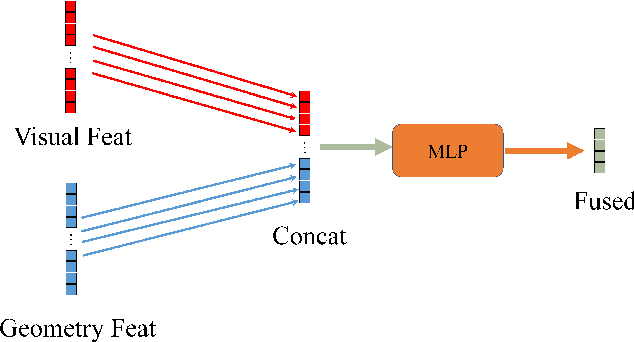
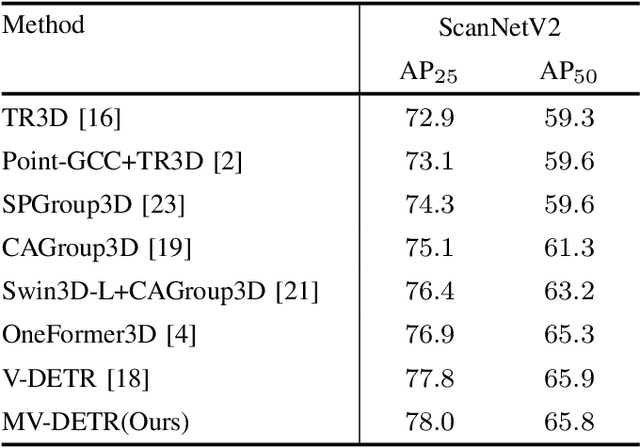
We introduce a novel MV-DETR pipeline which is effective while efficient transformer based detection method. Given input RGBD data, we notice that there are super strong pretraining weights for RGB data while less effective works for depth related data. First and foremost , we argue that geometry and texture cues are both of vital importance while could be encoded separately. Secondly, we find that visual texture feature is relatively hard to extract compared with geometry feature in 3d space. Unfortunately, single RGBD dataset with thousands of data is not enough for training an discriminating filter for visual texture feature extraction. Last but certainly not the least, we designed a lightweight VG module consists of a visual textual encoder, a geometry encoder and a VG connector. Compared with previous state of the art works like V-DETR, gains from pretrained visual encoder could be seen. Extensive experiments on ScanNetV2 dataset shows the effectiveness of our method. It is worth mentioned that our method achieve 78\% AP which create new state of the art on ScanNetv2 benchmark.
LVIC: Multi-modality segmentation by Lifting Visual Info as Cue
Mar 08, 2024


Multi-modality fusion is proven an effective method for 3d perception for autonomous driving. However, most current multi-modality fusion pipelines for LiDAR semantic segmentation have complicated fusion mechanisms. Point painting is a quite straight forward method which directly bind LiDAR points with visual information. Unfortunately, previous point painting like methods suffer from projection error between camera and LiDAR. In our experiments, we find that this projection error is the devil in point painting. As a result of that, we propose a depth aware point painting mechanism, which significantly boosts the multi-modality fusion. Apart from that, we take a deeper look at the desired visual feature for LiDAR to operate semantic segmentation. By Lifting Visual Information as Cue, LVIC ranks 1st on nuScenes LiDAR semantic segmentation benchmark. Our experiments show the robustness and effectiveness. Codes would be make publicly available soon.
PeP: a Point enhanced Painting method for unified point cloud tasks
Oct 11, 2023


Point encoder is of vital importance for point cloud recognition. As the very beginning step of whole model pipeline, adding features from diverse sources and providing stronger feature encoding mechanism would provide better input for downstream modules. In our work, we proposed a novel PeP module to tackle above issue. PeP contains two main parts, a refined point painting method and a LM-based point encoder. Experiments results on the nuScenes and KITTI datasets validate the superior performance of our PeP. The advantages leads to strong performance on both semantic segmentation and object detection, in both lidar and multi-modal settings. Notably, our PeP module is model agnostic and plug-and-play. Our code will be publicly available soon.
HuBo-VLM: Unified Vision-Language Model designed for HUman roBOt interaction tasks
Aug 24, 2023

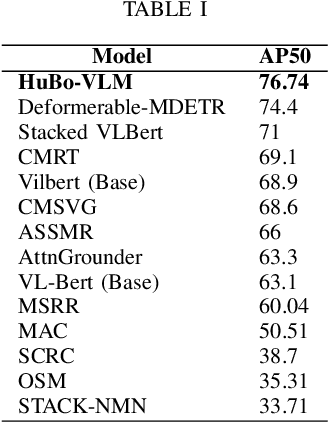
Human robot interaction is an exciting task, which aimed to guide robots following instructions from human. Since huge gap lies between human natural language and machine codes, end to end human robot interaction models is fair challenging. Further, visual information receiving from sensors of robot is also a hard language for robot to perceive. In this work, HuBo-VLM is proposed to tackle perception tasks associated with human robot interaction including object detection and visual grounding by a unified transformer based vision language model. Extensive experiments on the Talk2Car benchmark demonstrate the effectiveness of our approach. Code would be publicly available in https://github.com/dzcgaara/HuBo-VLM.
OG: Equip vision occupancy with instance segmentation and visual grounding
Jul 12, 2023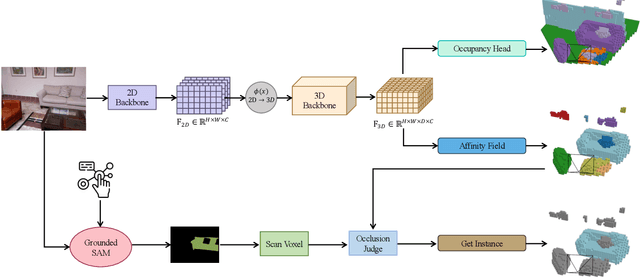
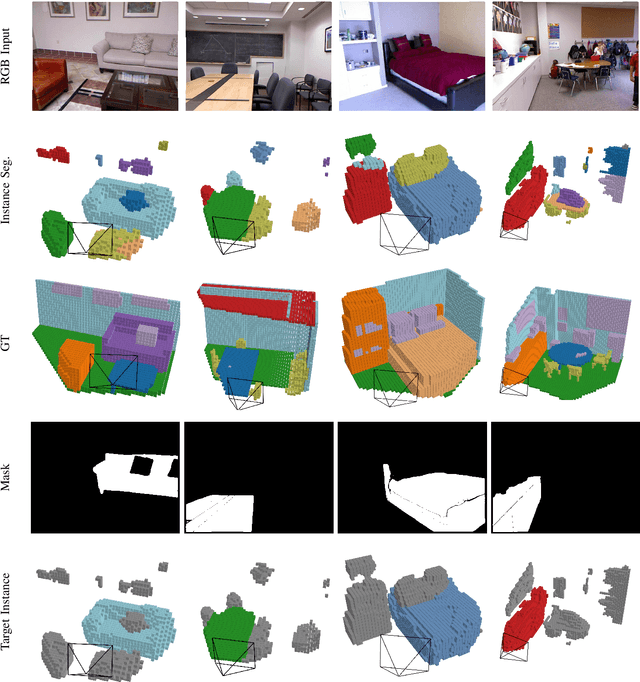
Occupancy prediction tasks focus on the inference of both geometry and semantic labels for each voxel, which is an important perception mission. However, it is still a semantic segmentation task without distinguishing various instances. Further, although some existing works, such as Open-Vocabulary Occupancy (OVO), have already solved the problem of open vocabulary detection, visual grounding in occupancy has not been solved to the best of our knowledge. To tackle the above two limitations, this paper proposes Occupancy Grounding (OG), a novel method that equips vanilla occupancy instance segmentation ability and could operate visual grounding in a voxel manner with the help of grounded-SAM. Keys to our approach are (1) affinity field prediction for instance clustering and (2) association strategy for aligning 2D instance masks and 3D occupancy instances. Extensive experiments have been conducted whose visualization results and analysis are shown below. Our code will be publicly released soon.
Deep Transfer Convolutional Neural Network and Extreme Learning Machine for Lung Nodule Diagnosis on CT images
Jan 05, 2020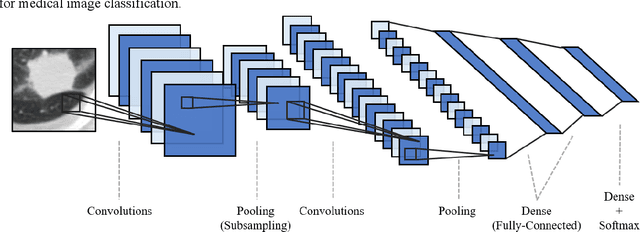
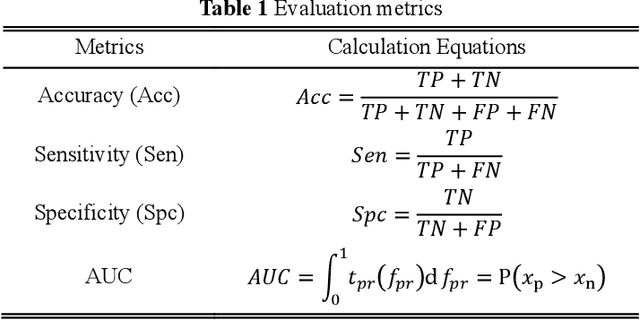
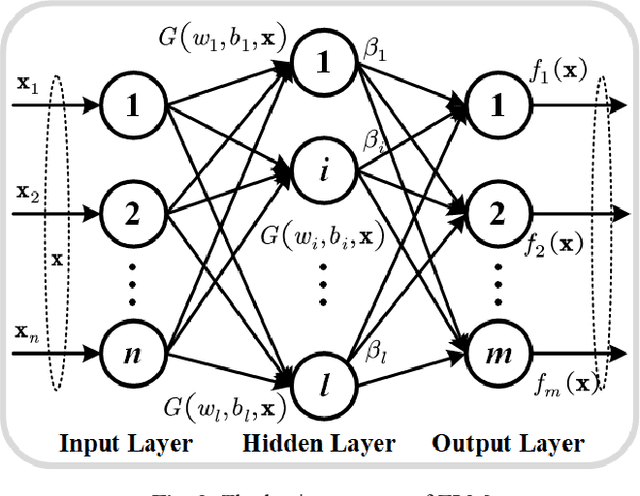
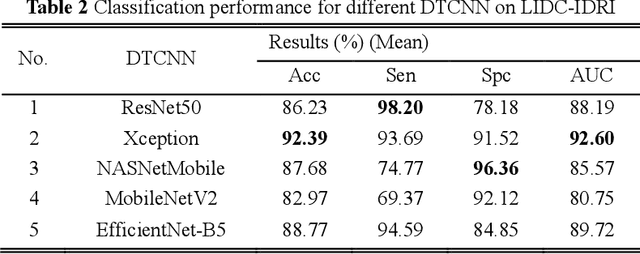
Diagnosis of benign-malignant nodules in the lung on Computed Tomography (CT) images is critical for determining tumor level and reducing patient mortality. Deep learning-based diagnosis of nodules in lung CT images, however, is time-consuming and less accurate due to redundant structure and the lack of adequate training data. In this paper, a novel diagnosis method based on Deep Transfer Convolutional Neural Network (DTCNN) and Extreme Learning Machine (ELM) is explored, which merges the synergy of two algorithms to deal with benign-malignant nodules classification. An optimal DTCNN is first adopted to extract high level features of lung nodules, which has been trained with the ImageNet dataset beforehand. After that, an ELM classifier is further developed to classify benign and malignant lung nodules. Two datasets, including the Lung Image Database Consortium and Image Database Resource Initiative (LIDC-IDRI) public dataset and a private dataset from the First Affiliated Hospital of Guangzhou Medical University in China (FAH-GMU), have been conducted to verify the efficiency and effectiveness of the proposed approach. The experimental results show that our novel DTCNN-ELM model provides the most reliable results compared with current state-of-the-art methods.