 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMV-DETR: Multi-modality indoor object detection by Multi-View DEtecton TRansformers
Paper and Code
Aug 13, 2024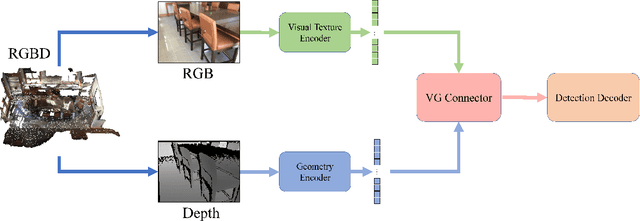
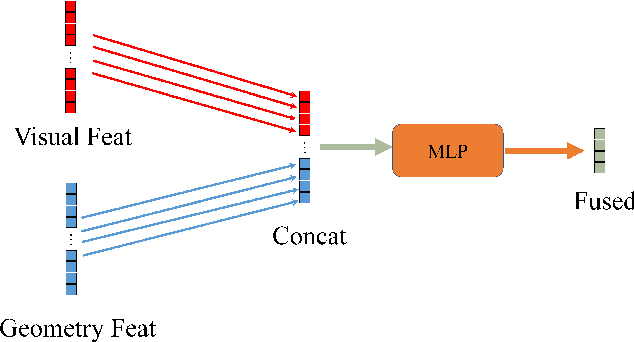
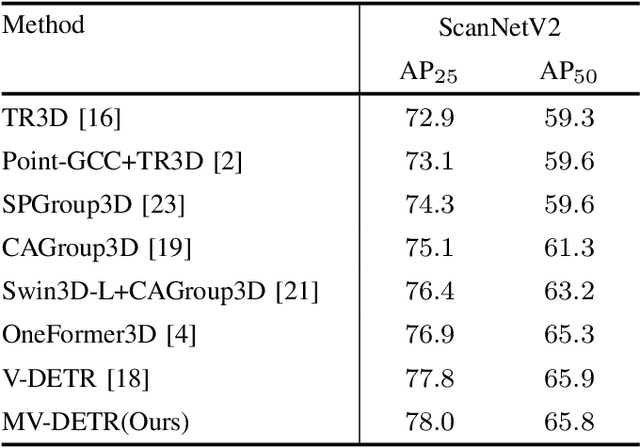
We introduce a novel MV-DETR pipeline which is effective while efficient transformer based detection method. Given input RGBD data, we notice that there are super strong pretraining weights for RGB data while less effective works for depth related data. First and foremost , we argue that geometry and texture cues are both of vital importance while could be encoded separately. Secondly, we find that visual texture feature is relatively hard to extract compared with geometry feature in 3d space. Unfortunately, single RGBD dataset with thousands of data is not enough for training an discriminating filter for visual texture feature extraction. Last but certainly not the least, we designed a lightweight VG module consists of a visual textual encoder, a geometry encoder and a VG connector. Compared with previous state of the art works like V-DETR, gains from pretrained visual encoder could be seen. Extensive experiments on ScanNetV2 dataset shows the effectiveness of our method. It is worth mentioned that our method achieve 78\% AP which create new state of the art on ScanNetv2 benchmark.