 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionFormer: A Multi-sensory Fusion in Bird's-Eye-View and Temporal Consistent Transformer for 3D Objection
Sep 11, 2023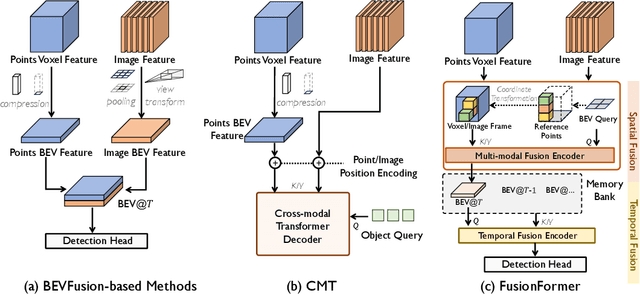
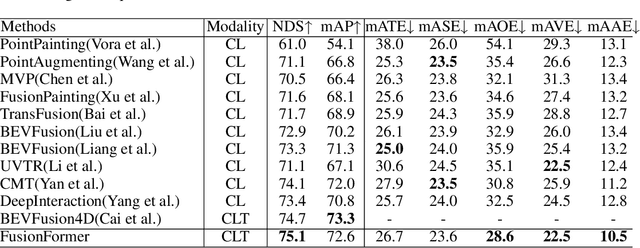
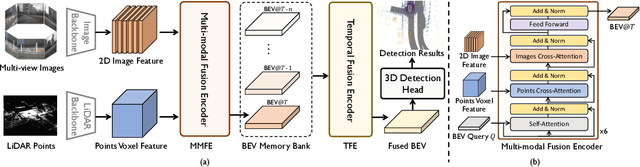
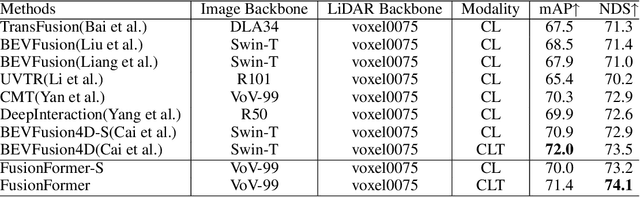
Multi-sensor modal fusion has demonstrated strong advantages in 3D object detection tasks. However, existing methods that fuse multi-modal features through a simple channel concatenation require transformation features into bird's eye view space and may lose the information on Z-axis thus leads to inferior performance. To this end, we propose FusionFormer, an end-to-end multi-modal fusion framework that leverages transformers to fuse multi-modal features and obtain fused BEV features. And based on the flexible adaptability of FusionFormer to the input modality representation, we propose a depth prediction branch that can be added to the framework to improve detection performance in camera-based detection tasks. In addition, we propose a plug-and-play temporal fusion module based on transformers that can fuse historical frame BEV features for more stable and reliable detection results. We evaluate our method on the nuScenes dataset and achieve 72.6% mAP and 75.1% NDS for 3D object detection tasks, outperforming state-of-the-art methods.
INT: Towards Infinite-frames 3D Detection with An Efficient Framework
Sep 30, 2022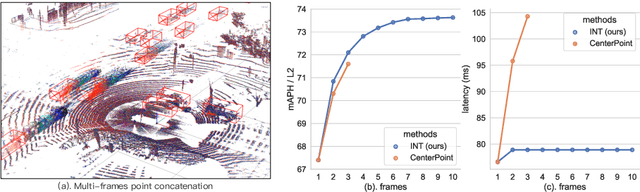
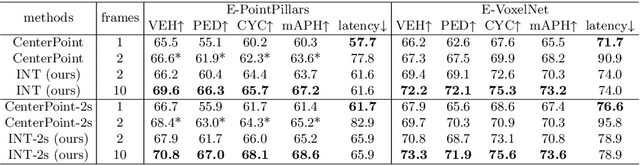
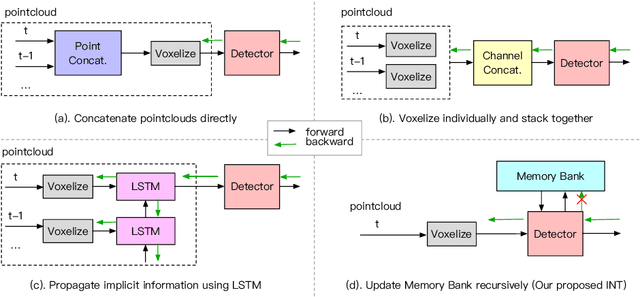
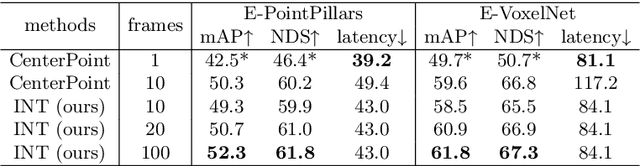
It is natural to construct a multi-frame instead of a single-frame 3D detector for a continuous-time stream. Although increasing the number of frames might improve performance, previous multi-frame studies only used very limited frames to build their systems due to the dramatically increased computational and memory cost. To address these issues, we propose a novel on-stream training and prediction framework that, in theory, can employ an infinite number of frames while keeping the same amount of computation as a single-frame detector. This infinite framework (INT), which can be used with most existing detectors, is utilized, for example, on the popular CenterPoint, with significant latency reductions and performance improvements. We've also conducted extensive experiments on two large-scale datasets, nuScenes and Waymo Open Dataset, to demonstrate the scheme's effectiveness and efficiency. By employing INT on CenterPoint, we can get around 7% (Waymo) and 15% (nuScenes) performance boost with only 2~4ms latency overhead, and currently SOTA on the Waymo 3D Detection leaderboard.