 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
Two Tasks, One Goal: Uniting Motion and Planning for Excellent End To End Autonomous Driving Performance
Apr 17, 2025End-to-end autonomous driving has made impressive progress in recent years. Former end-to-end autonomous driving approaches often decouple planning and motion tasks, treating them as separate modules. This separation overlooks the potential benefits that planning can gain from learning out-of-distribution data encountered in motion tasks. However, unifying these tasks poses significant challenges, such as constructing shared contextual representations and handling the unobservability of other vehicles' states. To address these challenges, we propose TTOG, a novel two-stage trajectory generation framework. In the first stage, a diverse set of trajectory candidates is generated, while the second stage focuses on refining these candidates through vehicle state information. To mitigate the issue of unavailable surrounding vehicle states, TTOG employs a self-vehicle data-trained state estimator, subsequently extended to other vehicles. Furthermore, we introduce ECSA (equivariant context-sharing scene adapter) to enhance the generalization of scene representations across different agents. Experimental results demonstrate that TTOG achieves state-of-the-art performance across both planning and motion tasks. Notably, on the challenging open-loop nuScenes dataset, TTOG reduces the L2 distance by 36.06\%. Furthermore, on the closed-loop Bench2Drive dataset, our approach achieves a 22\% improvement in the driving score (DS), significantly outperforming existing baselines.
Don't Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving
Mar 05, 2025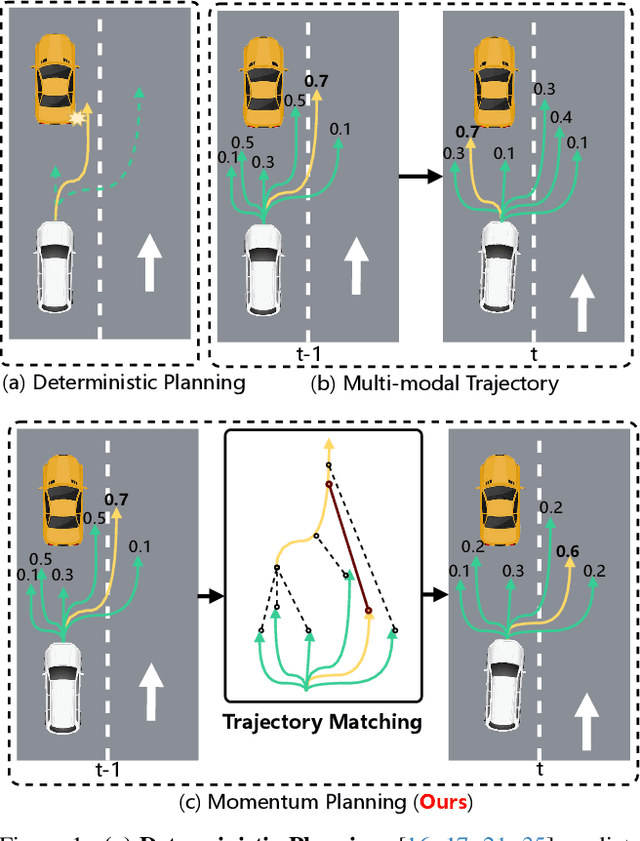


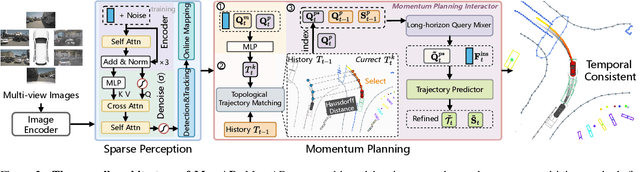
End-to-end autonomous driving frameworks enable seamless integration of perception and planning but often rely on one-shot trajectory prediction, which may lead to unstable control and vulnerability to occlusions in single-frame perception. To address this, we propose the Momentum-Aware Driving (MomAD) framework, which introduces trajectory momentum and perception momentum to stabilize and refine trajectory predictions. MomAD comprises two core components: (1) Topological Trajectory Matching (TTM) employs Hausdorff Distance to select the optimal planning query that aligns with prior paths to ensure coherence;(2) Momentum Planning Interactor (MPI) cross-attends the selected planning query with historical queries to expand static and dynamic perception files. This enriched query, in turn, helps regenerate long-horizon trajectory and reduce collision risks. To mitigate noise arising from dynamic environments and detection errors, we introduce robust instance denoising during training, enabling the planning model to focus on critical signals and improve its robustness. We also propose a novel Trajectory Prediction Consistency (TPC) metric to quantitatively assess planning stability. Experiments on the nuScenes dataset demonstrate that MomAD achieves superior long-term consistency (>=3s) compared to SOTA methods. Moreover, evaluations on the curated Turning-nuScenes shows that MomAD reduces the collision rate by 26% and improves TPC by 0.97m (33.45%) over a 6s prediction horizon, while closedloop on Bench2Drive demonstrates an up to 16.3% improvement in success rate.
SparseDet: A Simple and Effective Framework for Fully Sparse LiDAR-based 3D Object Detection
Jun 16, 2024



LiDAR-based sparse 3D object detection plays a crucial role in autonomous driving applications due to its computational efficiency advantages. Existing methods either use the features of a single central voxel as an object proxy, or treat an aggregated cluster of foreground points as an object proxy. However, the former lacks the ability to aggregate contextual information, resulting in insufficient information expression in object proxies. The latter relies on multi-stage pipelines and auxiliary tasks, which reduce the inference speed. To maintain the efficiency of the sparse framework while fully aggregating contextual information, in this work, we propose SparseDet which designs sparse queries as object proxies. It introduces two key modules, the Local Multi-scale Feature Aggregation (LMFA) module and the Global Feature Aggregation (GFA) module, aiming to fully capture the contextual information, thereby enhancing the ability of the proxies to represent objects. Where LMFA sub-module achieves feature fusion across different scales for sparse key voxels %which does this through via coordinate transformations and using nearest neighbor relationships to capture object-level details and local contextual information, GFA sub-module uses self-attention mechanisms to selectively aggregate the features of the key voxels across the entire scene for capturing scene-level contextual information. Experiments on nuScenes and KITTI demonstrate the effectiveness of our method. Specifically, on nuScene, SparseDet surpasses the previous best sparse detector VoxelNeXt by 2.2\% mAP with 13.5 FPS, and on KITTI, it surpasses VoxelNeXt by 1.12\% $\mathbf{AP_{3D}}$ on hard level tasks with 17.9 FPS.
ContrastAlign: Toward Robust BEV Feature Alignment via Contrastive Learning for Multi-Modal 3D Object Detection
May 27, 2024



In the field of 3D object detection tasks, fusing heterogeneous features from LiDAR and camera sensors into a unified Bird's Eye View (BEV) representation is a widely adopted paradigm. However, existing methods are often compromised by imprecise sensor calibration, resulting in feature misalignment in LiDAR-camera BEV fusion. Moreover, such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a novel ContrastAlign approach that utilizes contrastive learning to enhance the alignment of heterogeneous modalities, thereby improving the robustness of the fusion process. Specifically, our approach includes the L-Instance module, which directly outputs LiDAR instance features within LiDAR BEV features. Then, we introduce the C-Instance module, which predicts camera instance features through RoI (Region of Interest) pooling on the camera BEV features. We propose the InstanceFusion module, which utilizes contrastive learning to generate similar instance features across heterogeneous modalities. We then use graph matching to calculate the similarity between the neighboring camera instance features and the similarity instance features to complete the alignment of instance features. Our method achieves state-of-the-art performance, with an mAP of 70.3%, surpassing BEVFusion by 1.8% on the nuScenes validation set. Importantly, our method outperforms BEVFusion by 7.3% under conditions with misalignment noise.
INT: Towards Infinite-frames 3D Detection with An Efficient Framework
Sep 30, 2022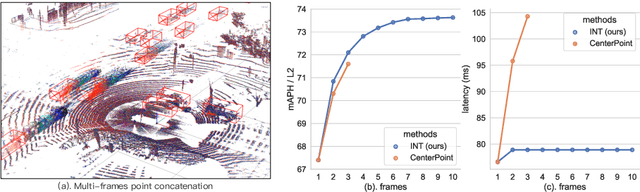
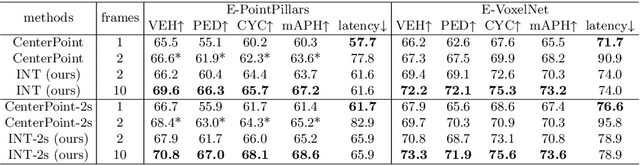
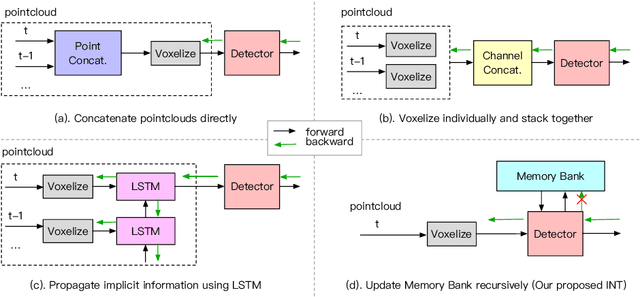
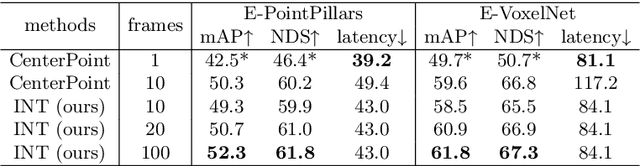
It is natural to construct a multi-frame instead of a single-frame 3D detector for a continuous-time stream. Although increasing the number of frames might improve performance, previous multi-frame studies only used very limited frames to build their systems due to the dramatically increased computational and memory cost. To address these issues, we propose a novel on-stream training and prediction framework that, in theory, can employ an infinite number of frames while keeping the same amount of computation as a single-frame detector. This infinite framework (INT), which can be used with most existing detectors, is utilized, for example, on the popular CenterPoint, with significant latency reductions and performance improvements. We've also conducted extensive experiments on two large-scale datasets, nuScenes and Waymo Open Dataset, to demonstrate the scheme's effectiveness and efficiency. By employing INT on CenterPoint, we can get around 7% (Waymo) and 15% (nuScenes) performance boost with only 2~4ms latency overhead, and currently SOTA on the Waymo 3D Detection leaderboard.
CPGNet: Cascade Point-Grid Fusion Network for Real-Time LiDAR Semantic Segmentation
Apr 27, 2022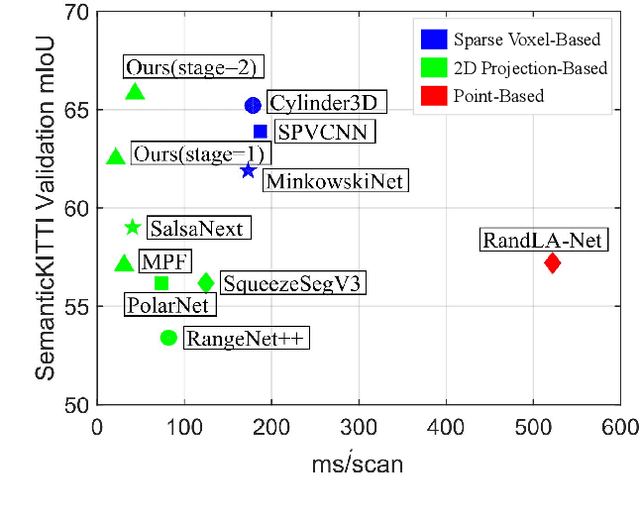
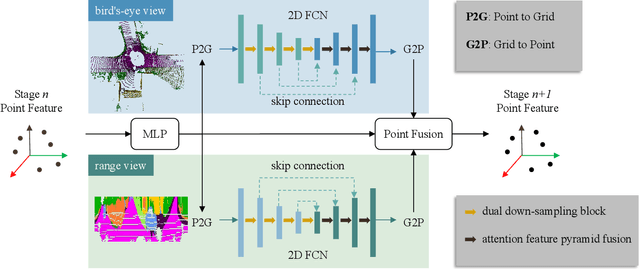
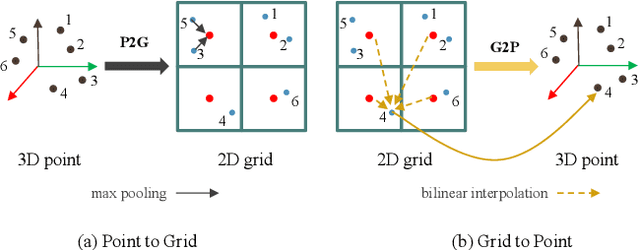
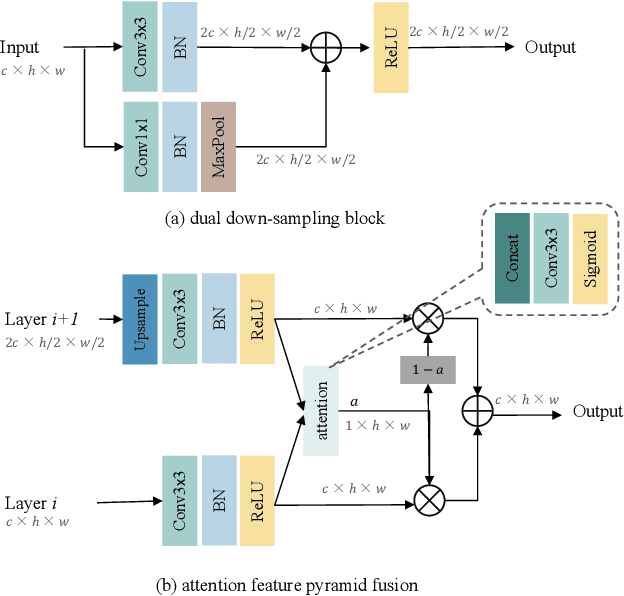
LiDAR semantic segmentation essential for advanced autonomous driving is required to be accurate, fast, and easy-deployed on mobile platforms. Previous point-based or sparse voxel-based methods are far away from real-time applications since time-consuming neighbor searching or sparse 3D convolution are employed. Recent 2D projection-based methods, including range view and multi-view fusion, can run in real time, but suffer from lower accuracy due to information loss during the 2D projection. Besides, to improve the performance, previous methods usually adopt test time augmentation (TTA), which further slows down the inference process. To achieve a better speed-accuracy trade-off, we propose Cascade Point-Grid Fusion Network (CPGNet), which ensures both effectiveness and efficiency mainly by the following two techniques: 1) the novel Point-Grid (PG) fusion block extracts semantic features mainly on the 2D projected grid for efficiency, while summarizes both 2D and 3D features on 3D point for minimal information loss; 2) the proposed transformation consistency loss narrows the gap between the single-time model inference and TTA. The experiments on the SemanticKITTI and nuScenes benchmarks demonstrate that the CPGNet without ensemble models or TTA is comparable with the state-of-the-art RPVNet, while it runs 4.7 times faster.