 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPGNet: Cascade Point-Grid Fusion Network for Real-Time LiDAR Semantic Segmentation
Paper and Code
Apr 27, 2022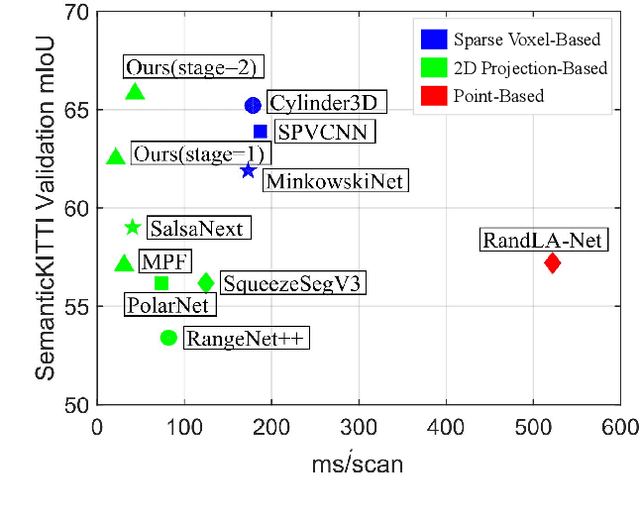
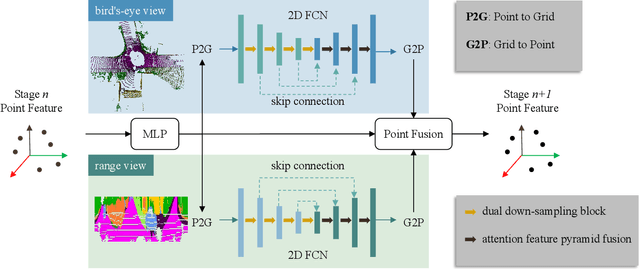
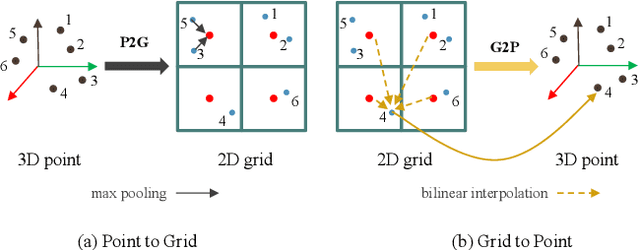
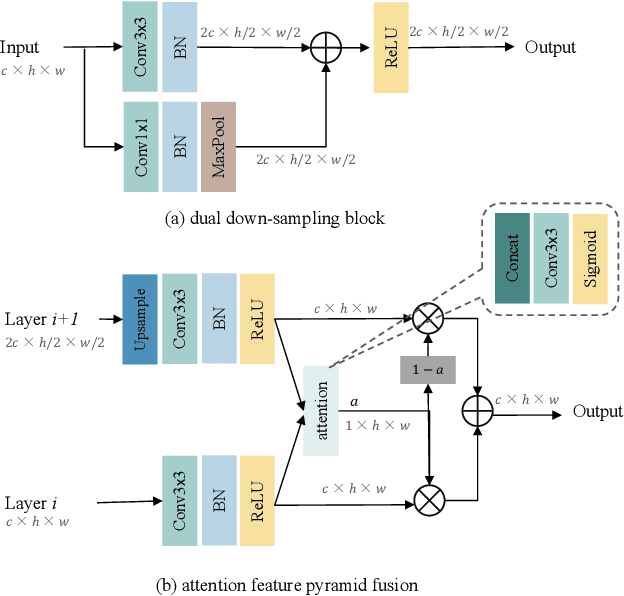
LiDAR semantic segmentation essential for advanced autonomous driving is required to be accurate, fast, and easy-deployed on mobile platforms. Previous point-based or sparse voxel-based methods are far away from real-time applications since time-consuming neighbor searching or sparse 3D convolution are employed. Recent 2D projection-based methods, including range view and multi-view fusion, can run in real time, but suffer from lower accuracy due to information loss during the 2D projection. Besides, to improve the performance, previous methods usually adopt test time augmentation (TTA), which further slows down the inference process. To achieve a better speed-accuracy trade-off, we propose Cascade Point-Grid Fusion Network (CPGNet), which ensures both effectiveness and efficiency mainly by the following two techniques: 1) the novel Point-Grid (PG) fusion block extracts semantic features mainly on the 2D projected grid for efficiency, while summarizes both 2D and 3D features on 3D point for minimal information loss; 2) the proposed transformation consistency loss narrows the gap between the single-time model inference and TTA. The experiments on the SemanticKITTI and nuScenes benchmarks demonstrate that the CPGNet without ensemble models or TTA is comparable with the state-of-the-art RPVNet, while it runs 4.7 times faster.