 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXRZero-G0: Pushing the Frontier of Dexterous Robotic Manipulation with Interfaces, Quality and Ratios
Apr 14, 2026The acquisition of high-quality, action-aligned demonstration data remains a fundamental bottleneck in scaling foundation models for dexterous robot manipulation. Although robot-free human demonstrations (e.g., the UMI paradigm) offer a scalable alternative to traditional teleoperation, current systems are constrained by sub-optimal hardware ergonomics, open-loop workflows, and a lack of systematic data-mixing strategies. To address these limitations, we present XRZero-G0, a hardware-software co-designed system for embodied data collection and policy learning. The system features an ergonomic, virtual reality interface equipped with a top-view camera and dual specialized grippers to directly improve collection efficiency. To ensure dataset reliability, we propose a closed-loop collection, inspection, training, and evaluation pipeline for non-proprioceptive data. This workflow achieves an 85% data validity rate and establishes a transparent mechanism for quality control. Furthermore, we investigate the empirical scaling behaviors and optimal mixing ratios of robot-free data. Extensive experiments indicate that combining a minimal volume of real-robot data with large-scale robot-free data (e.g., a 10:1 ratio) achieves performance comparable to exclusively real-robot datasets, while reducing acquisition costs by a factor of twenty. Utilizing XRZero-G0, we construct a 2,000-hour robot-free dataset that enables zero-shot cross-embodiment transfer to a target physical robot, demonstrating a highly scalable methodology for generalized real-world manipulation.Our project repository: https://github.com/X-Square-Robot/XRZero-G0
NeurNCD: Novel Class Discovery via Implicit Neural Representation
Jun 06, 2025
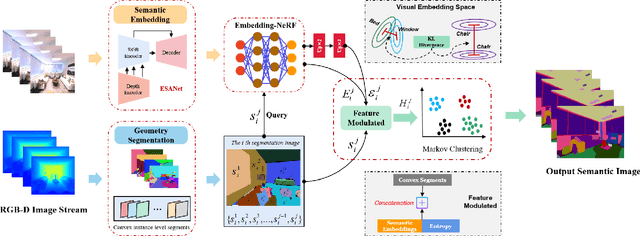
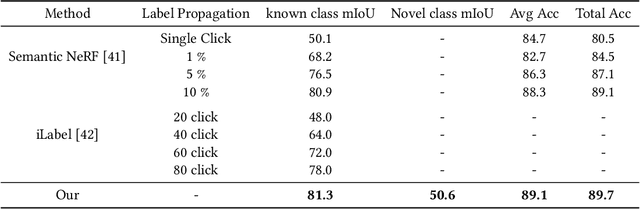

Discovering novel classes in open-world settings is crucial for real-world applications. Traditional explicit representations, such as object descriptors or 3D segmentation maps, are constrained by their discrete, hole-prone, and noisy nature, which hinders accurate novel class discovery. To address these challenges, we introduce NeurNCD, the first versatile and data-efficient framework for novel class discovery that employs the meticulously designed Embedding-NeRF model combined with KL divergence as a substitute for traditional explicit 3D segmentation maps to aggregate semantic embedding and entropy in visual embedding space. NeurNCD also integrates several key components, including feature query, feature modulation and clustering, facilitating efficient feature augmentation and information exchange between the pre-trained semantic segmentation network and implicit neural representations. As a result, our framework achieves superior segmentation performance in both open and closed-world settings without relying on densely labelled datasets for supervised training or human interaction to generate sparse label supervision. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art approaches on the NYUv2 and Replica datasets.
Don't Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving
Mar 05, 2025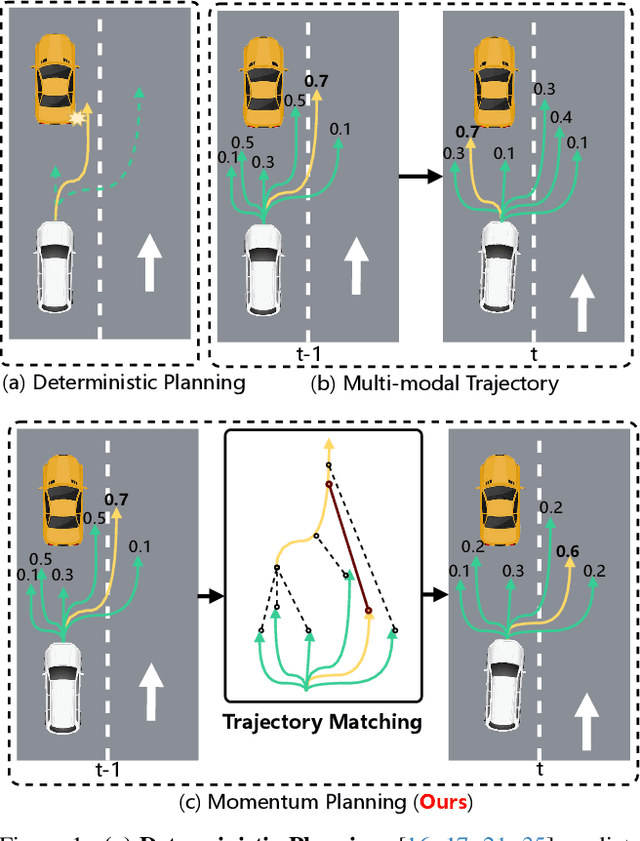


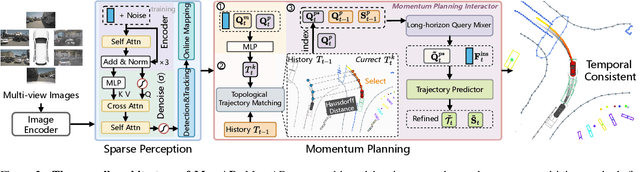
End-to-end autonomous driving frameworks enable seamless integration of perception and planning but often rely on one-shot trajectory prediction, which may lead to unstable control and vulnerability to occlusions in single-frame perception. To address this, we propose the Momentum-Aware Driving (MomAD) framework, which introduces trajectory momentum and perception momentum to stabilize and refine trajectory predictions. MomAD comprises two core components: (1) Topological Trajectory Matching (TTM) employs Hausdorff Distance to select the optimal planning query that aligns with prior paths to ensure coherence;(2) Momentum Planning Interactor (MPI) cross-attends the selected planning query with historical queries to expand static and dynamic perception files. This enriched query, in turn, helps regenerate long-horizon trajectory and reduce collision risks. To mitigate noise arising from dynamic environments and detection errors, we introduce robust instance denoising during training, enabling the planning model to focus on critical signals and improve its robustness. We also propose a novel Trajectory Prediction Consistency (TPC) metric to quantitatively assess planning stability. Experiments on the nuScenes dataset demonstrate that MomAD achieves superior long-term consistency (>=3s) compared to SOTA methods. Moreover, evaluations on the curated Turning-nuScenes shows that MomAD reduces the collision rate by 26% and improves TPC by 0.97m (33.45%) over a 6s prediction horizon, while closedloop on Bench2Drive demonstrates an up to 16.3% improvement in success rate.
DOME: Taming Diffusion Model into High-Fidelity Controllable Occupancy World Model
Oct 14, 2024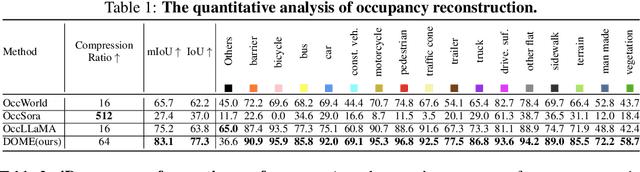

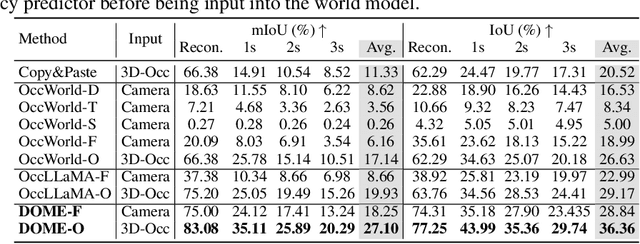
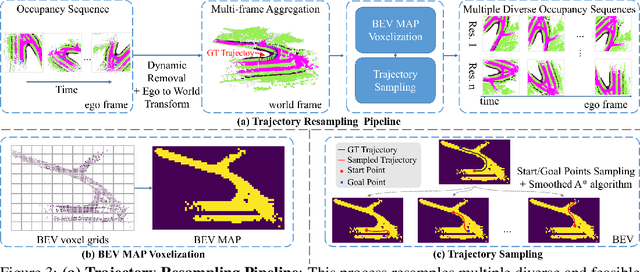
We propose DOME, a diffusion-based world model that predicts future occupancy frames based on past occupancy observations. The ability of this world model to capture the evolution of the environment is crucial for planning in autonomous driving. Compared to 2D video-based world models, the occupancy world model utilizes a native 3D representation, which features easily obtainable annotations and is modality-agnostic. This flexibility has the potential to facilitate the development of more advanced world models. Existing occupancy world models either suffer from detail loss due to discrete tokenization or rely on simplistic diffusion architectures, leading to inefficiencies and difficulties in predicting future occupancy with controllability. Our DOME exhibits two key features:(1) High-Fidelity and Long-Duration Generation. We adopt a spatial-temporal diffusion transformer to predict future occupancy frames based on historical context. This architecture efficiently captures spatial-temporal information, enabling high-fidelity details and the ability to generate predictions over long durations. (2)Fine-grained Controllability. We address the challenge of controllability in predictions by introducing a trajectory resampling method, which significantly enhances the model's ability to generate controlled predictions. Extensive experiments on the widely used nuScenes dataset demonstrate that our method surpasses existing baselines in both qualitative and quantitative evaluations, establishing a new state-of-the-art performance on nuScenes. Specifically, our approach surpasses the baseline by 10.5% in mIoU and 21.2% in IoU for occupancy reconstruction and by 36.0% in mIoU and 24.6% in IoU for 4D occupancy forecasting.
HE-Drive: Human-Like End-to-End Driving with Vision Language Models
Oct 07, 2024In this paper, we propose HE-Drive: the first human-like-centric end-to-end autonomous driving system to generate trajectories that are both temporally consistent and comfortable. Recent studies have shown that imitation learning-based planners and learning-based trajectory scorers can effectively generate and select accuracy trajectories that closely mimic expert demonstrations. However, such trajectory planners and scorers face the dilemma of generating temporally inconsistent and uncomfortable trajectories. To solve the above problems, Our HE-Drive first extracts key 3D spatial representations through sparse perception, which then serves as conditional inputs for a Conditional Denoising Diffusion Probabilistic Models (DDPMs)-based motion planner to generate temporal consistency multi-modal trajectories. A Vision-Language Models (VLMs)-guided trajectory scorer subsequently selects the most comfortable trajectory from these candidates to control the vehicle, ensuring human-like end-to-end driving. Experiments show that HE-Drive not only achieves state-of-the-art performance (i.e., reduces the average collision rate by 71% than VAD) and efficiency (i.e., 1.9X faster than SparseDrive) on the challenging nuScenes and OpenScene datasets but also provides the most comfortable driving experience on real-world data.For more information, visit the project website: https://jmwang0117.github.io/HE-Drive/.
HE-Nav: A High-Performance and Efficient Navigation System for Aerial-Ground Robots in Cluttered Environments
Oct 07, 2024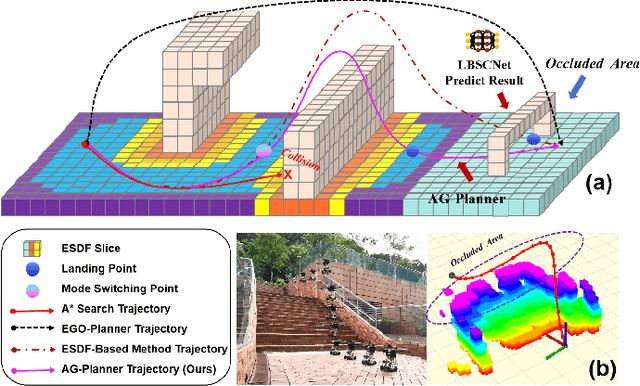
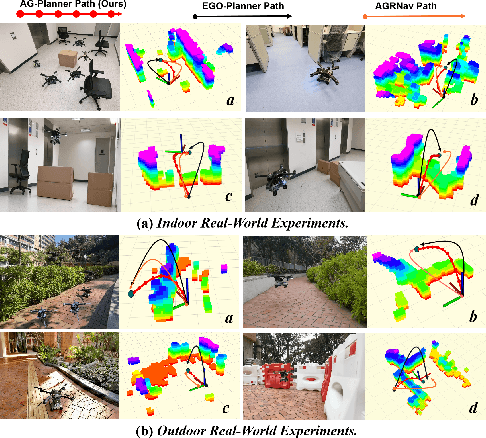
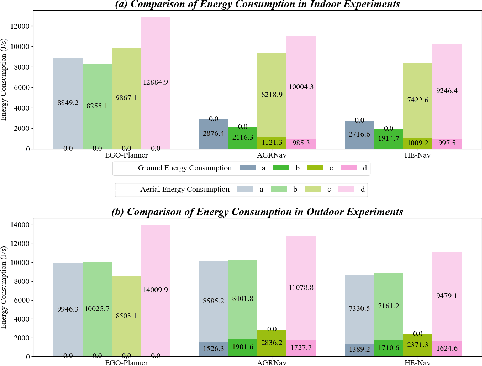
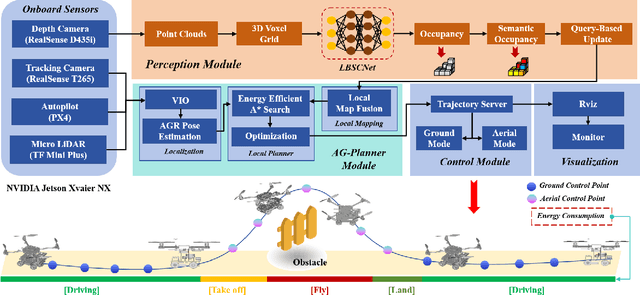
Existing AGR navigation systems have advanced in lightly occluded scenarios (e.g., buildings) by employing 3D semantic scene completion networks for voxel occupancy prediction and constructing Euclidean Signed Distance Field (ESDF) maps for collision-free path planning. However, these systems exhibit suboptimal performance and efficiency in cluttered environments with severe occlusions (e.g., dense forests or tall walls), due to limitations arising from perception networks' low prediction accuracy and path planners' high computational overhead. In this paper, we present HE-Nav, the first high-performance and efficient navigation system tailored for AGRs operating in cluttered environments. The perception module utilizes a lightweight semantic scene completion network (LBSCNet), guided by a bird's eye view (BEV) feature fusion and enhanced by an exquisitely designed SCB-Fusion module and attention mechanism. This enables real-time and efficient obstacle prediction in cluttered areas, generating a complete local map. Building upon this completed map, our novel AG-Planner employs the energy-efficient kinodynamic A* search algorithm to guarantee planning is energy-saving. Subsequent trajectory optimization processes yield safe, smooth, dynamically feasible and ESDF-free aerial-ground hybrid paths. Extensive experiments demonstrate that HE-Nav achieved 7x energy savings in real-world situations while maintaining planning success rates of 98% in simulation scenarios. Code and video are available on our project page: https://jmwang0117.github.io/HE-Nav/.
OccRWKV: Rethinking Efficient 3D Semantic Occupancy Prediction with Linear Complexity
Sep 30, 2024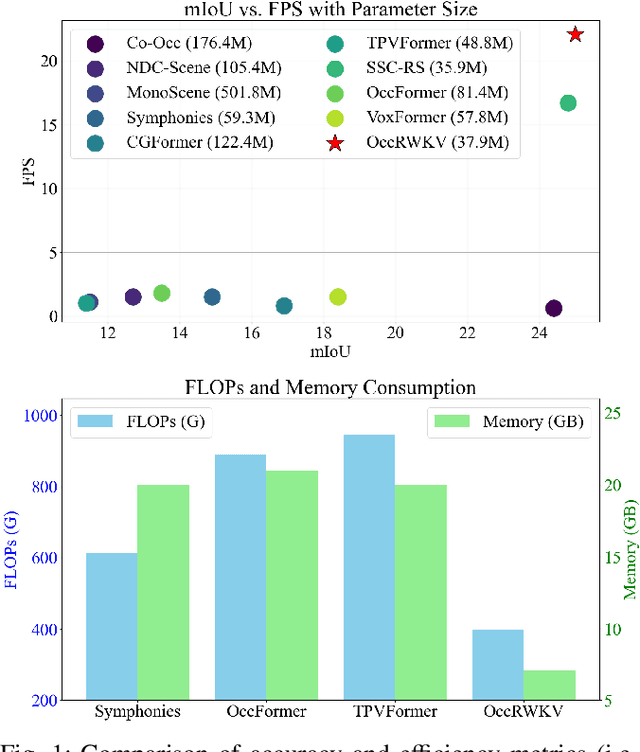
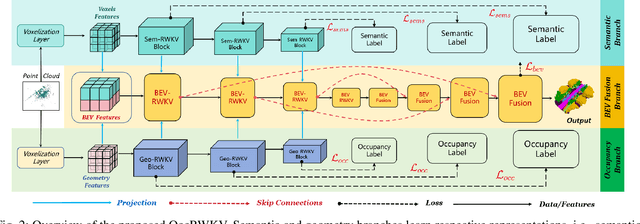
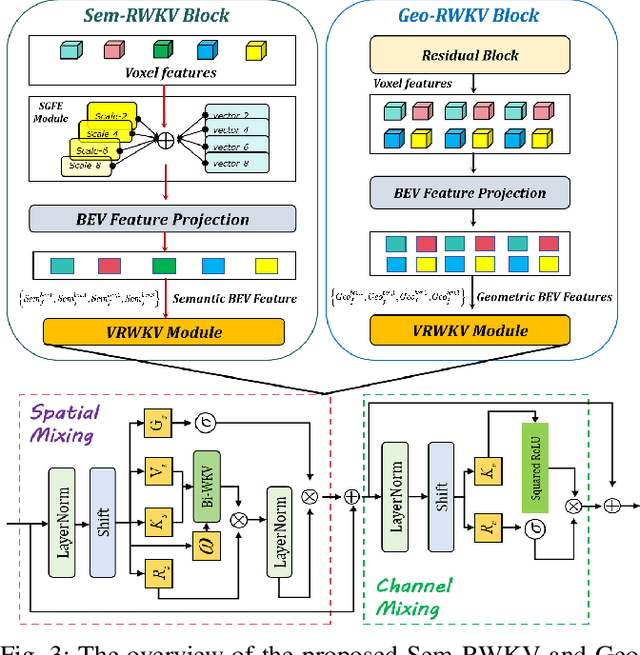
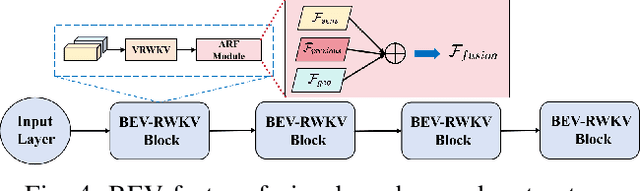
3D semantic occupancy prediction networks have demonstrated remarkable capabilities in reconstructing the geometric and semantic structure of 3D scenes, providing crucial information for robot navigation and autonomous driving systems. However, due to their large overhead from dense network structure designs, existing networks face challenges balancing accuracy and latency.In this paper, we introduce OccRWKV, an efficient semantic occupancy network inspired by Receptance Weighted Key Value (RWKV). OccRWKV separates semantics, occupancy prediction, and feature fusion into distinct branches, each incorporating Sem-RWKV and Geo-RWKV blocks. These blocks are designed to capture long-range dependencies, enabling the network to learn domain-specific representation (i.e., semantics and geometry), which enhances prediction accuracy. Leveraging the sparse nature of real-world 3D occupancy, we reduce computational overhead by projecting features into the bird's-eye view (BEV) space and propose a BEV-RWKV block for efficient feature enhancement and fusion. This enables real-time inference at 22.2 FPS without compromising performance. Experiments demonstrate that OccRWKV outperforms the state-of-the-art methods on the SemanticKITTI dataset, achieving a mIoU of 25.1 while being 20 times faster than the best baseline, Co-Occ, making it suitable for real-time deployment on robots to enhance autonomous navigation efficiency. Code and video are available on our project page: \url{https://jmwang0117.github.io/OccRWKV/}.
OMEGA: Efficient Occlusion-Aware Navigation for Air-Ground Robot in Dynamic Environments via State Space Model
Aug 20, 2024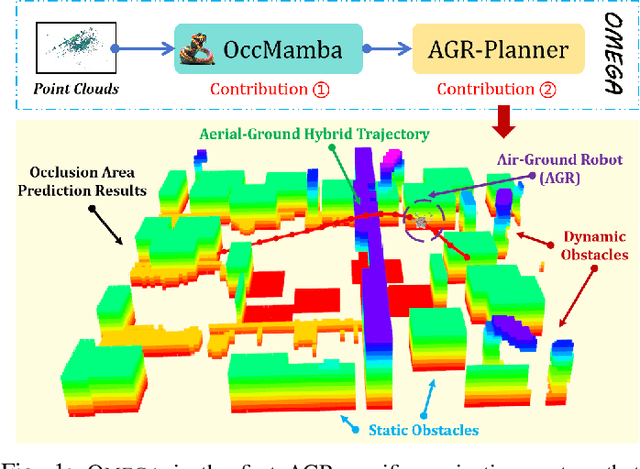
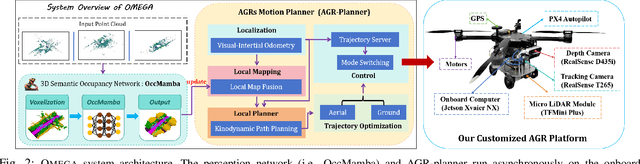
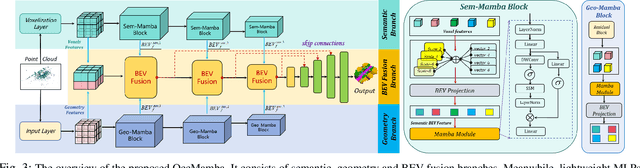
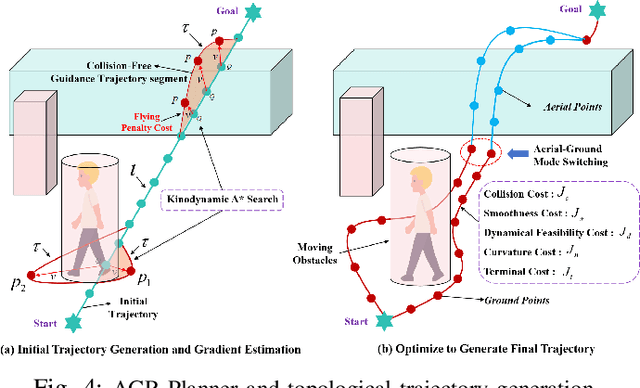
Air-ground robots (AGRs) are widely used in surveillance and disaster response due to their exceptional mobility and versatility (i.e., flying and driving). Current AGR navigation systems perform well in static occlusion-prone environments (e.g., indoors) by using 3D semantic occupancy networks to predict occlusions for complete local mapping and then computing Euclidean Signed Distance Field (ESDF) for path planning. However, these systems face challenges in dynamic, severe occlusion scenes (e.g., crowds) due to limitations in perception networks' low prediction accuracy and path planners' high computation overhead. In this paper, we propose OMEGA, which contains OccMamba with an Efficient AGR-Planner to address the above-mentioned problems. OccMamba adopts a novel architecture that separates semantic and occupancy prediction into independent branches, incorporating two mamba blocks within these branches. These blocks efficiently extract semantic and geometric features in 3D environments with linear complexity, ensuring that the network can learn long-distance dependencies to improve prediction accuracy. Semantic and geometric features are combined within the Bird's Eye View (BEV) space to minimise computational overhead during feature fusion. The resulting semantic occupancy map is then seamlessly integrated into the local map, providing occlusion awareness of the dynamic environment. Our AGR-Planner utilizes this local map and employs kinodynamic A* search and gradient-based trajectory optimization to guarantee planning is ESDF-free and energy-efficient. Extensive experiments demonstrate that OccMamba outperforms the state-of-the-art 3D semantic occupancy network with 25.0% mIoU. End-to-end navigation experiments in dynamic scenes verify OMEGA's efficiency, achieving a 96% average planning success rate. Code and video are available at https://jmwang0117.github.io/OMEGA/.
Hybrid-Parallel: Achieving High Performance and Energy Efficient Distributed Inference on Robots
May 29, 2024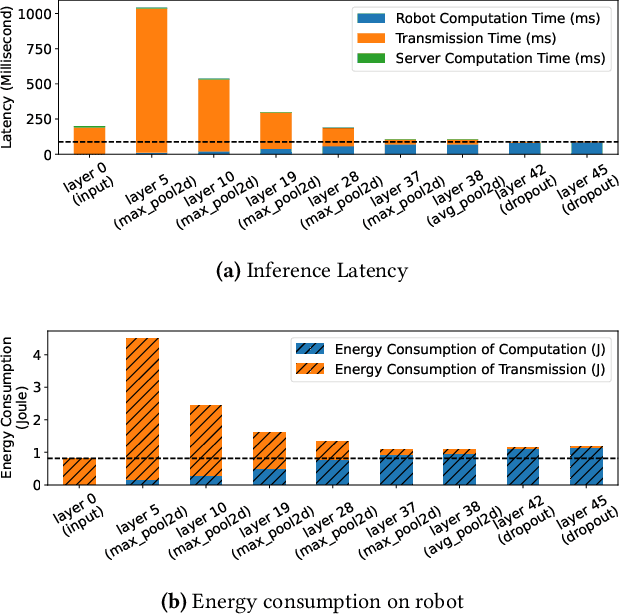
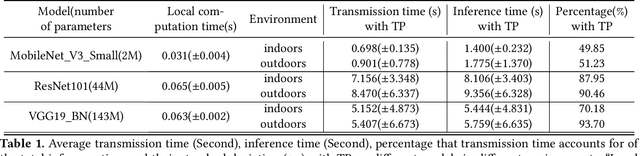
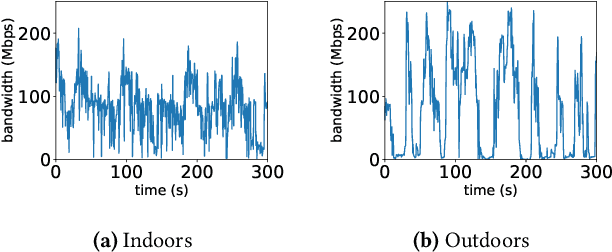
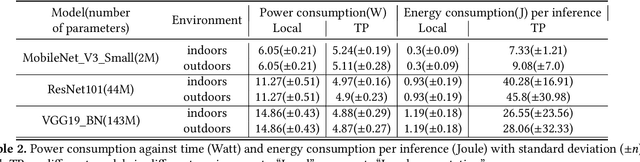
The rapid advancements in machine learning techniques have led to significant achievements in various real-world robotic tasks. These tasks heavily rely on fast and energy-efficient inference of deep neural network (DNN) models when deployed on robots. To enhance inference performance, distributed inference has emerged as a promising approach, parallelizing inference across multiple powerful GPU devices in modern data centers using techniques such as data parallelism, tensor parallelism, and pipeline parallelism. However, when deployed on real-world robots, existing parallel methods fail to provide low inference latency and meet the energy requirements due to the limited bandwidth of robotic IoT. We present Hybrid-Parallel, a high-performance distributed inference system optimized for robotic IoT. Hybrid-Parallel employs a fine-grained approach to parallelize inference at the granularity of local operators within DNN layers (i.e., operators that can be computed independently with the partial input, such as the convolution kernel in the convolution layer). By doing so, Hybrid-Parallel enables different operators of different layers to be computed and transmitted concurrently, and overlap the computation and transmission phases within the same inference task. The evaluation demonstrate that Hybrid-Parallel reduces inference time by 14.9% ~41.1% and energy consumption per inference by up to 35.3% compared to the state-of-the-art baselines.
AGRNav: Efficient and Energy-Saving Autonomous Navigation for Air-Ground Robots in Occlusion-Prone Environments
Mar 18, 2024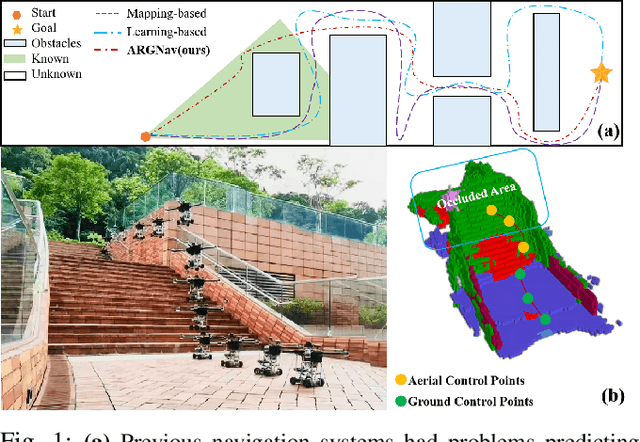
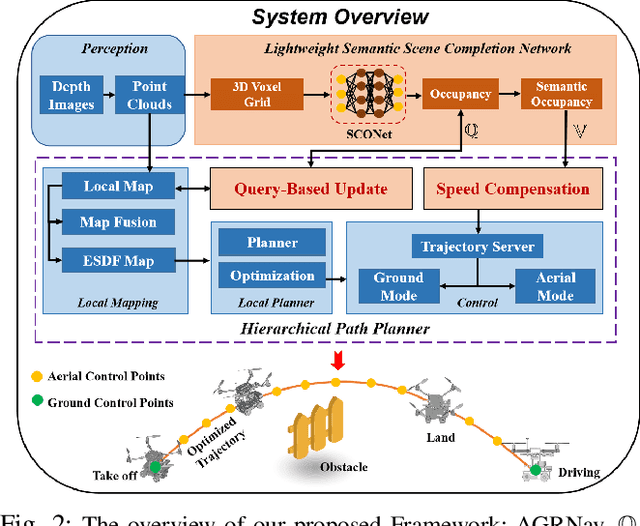
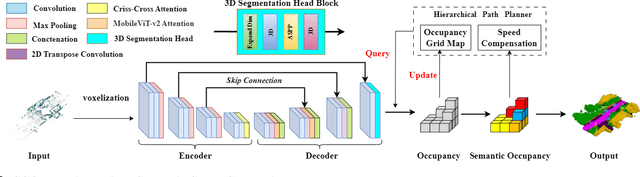
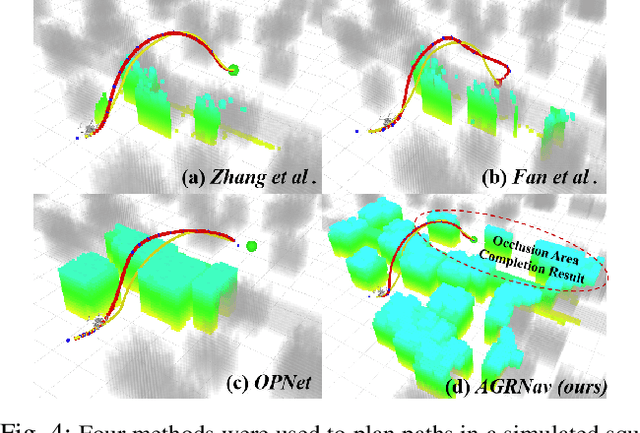
The exceptional mobility and long endurance of air-ground robots are raising interest in their usage to navigate complex environments (e.g., forests and large buildings). However, such environments often contain occluded and unknown regions, and without accurate prediction of unobserved obstacles, the movement of the air-ground robot often suffers a suboptimal trajectory under existing mapping-based and learning-based navigation methods. In this work, we present AGRNav, a novel framework designed to search for safe and energy-saving air-ground hybrid paths. AGRNav contains a lightweight semantic scene completion network (SCONet) with self-attention to enable accurate obstacle predictions by capturing contextual information and occlusion area features. The framework subsequently employs a query-based method for low-latency updates of prediction results to the grid map. Finally, based on the updated map, the hierarchical path planner efficiently searches for energy-saving paths for navigation. We validate AGRNav's performance through benchmarks in both simulated and real-world environments, demonstrating its superiority over classical and state-of-the-art methods. The open-source code is available at https://github.com/jmwang0117/AGRNav.