 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncAD: Towards Safe End-to-end Autonomous Driving via Online Map Uncertainty
Apr 17, 2025End-to-end autonomous driving aims to produce planning trajectories from raw sensors directly. Currently, most approaches integrate perception, prediction, and planning modules into a fully differentiable network, promising great scalability. However, these methods typically rely on deterministic modeling of online maps in the perception module for guiding or constraining vehicle planning, which may incorporate erroneous perception information and further compromise planning safety. To address this issue, we delve into the importance of online map uncertainty for enhancing autonomous driving safety and propose a novel paradigm named UncAD. Specifically, UncAD first estimates the uncertainty of the online map in the perception module. It then leverages the uncertainty to guide motion prediction and planning modules to produce multi-modal trajectories. Finally, to achieve safer autonomous driving, UncAD proposes an uncertainty-collision-aware planning selection strategy according to the online map uncertainty to evaluate and select the best trajectory. In this study, we incorporate UncAD into various state-of-the-art (SOTA) end-to-end methods. Experiments on the nuScenes dataset show that integrating UncAD, with only a 1.9% increase in parameters, can reduce collision rates by up to 26% and drivable area conflict rate by up to 42%. Codes, pre-trained models, and demo videos can be accessed at https://github.com/pengxuanyang/UncAD.
GoalFlow: Goal-Driven Flow Matching for Multimodal Trajectories Generation in End-to-End Autonomous Driving
Mar 07, 2025We propose GoalFlow, an end-to-end autonomous driving method for generating high-quality multimodal trajectories. In autonomous driving scenarios, there is rarely a single suitable trajectory. Recent methods have increasingly focused on modeling multimodal trajectory distributions. However, they suffer from trajectory selection complexity and reduced trajectory quality due to high trajectory divergence and inconsistencies between guidance and scene information. To address these issues, we introduce GoalFlow, a novel method that effectively constrains the generative process to produce high-quality, multimodal trajectories. To resolve the trajectory divergence problem inherent in diffusion-based methods, GoalFlow constrains the generated trajectories by introducing a goal point. GoalFlow establishes a novel scoring mechanism that selects the most appropriate goal point from the candidate points based on scene information. Furthermore, GoalFlow employs an efficient generative method, Flow Matching, to generate multimodal trajectories, and incorporates a refined scoring mechanism to select the optimal trajectory from the candidates. Our experimental results, validated on the Navsim\cite{Dauner2024_navsim}, demonstrate that GoalFlow achieves state-of-the-art performance, delivering robust multimodal trajectories for autonomous driving. GoalFlow achieved PDMS of 90.3, significantly surpassing other methods. Compared with other diffusion-policy-based methods, our approach requires only a single denoising step to obtain excellent performance. The code is available at https://github.com/YvanYin/GoalFlow.
HE-Drive: Human-Like End-to-End Driving with Vision Language Models
Oct 07, 2024In this paper, we propose HE-Drive: the first human-like-centric end-to-end autonomous driving system to generate trajectories that are both temporally consistent and comfortable. Recent studies have shown that imitation learning-based planners and learning-based trajectory scorers can effectively generate and select accuracy trajectories that closely mimic expert demonstrations. However, such trajectory planners and scorers face the dilemma of generating temporally inconsistent and uncomfortable trajectories. To solve the above problems, Our HE-Drive first extracts key 3D spatial representations through sparse perception, which then serves as conditional inputs for a Conditional Denoising Diffusion Probabilistic Models (DDPMs)-based motion planner to generate temporal consistency multi-modal trajectories. A Vision-Language Models (VLMs)-guided trajectory scorer subsequently selects the most comfortable trajectory from these candidates to control the vehicle, ensuring human-like end-to-end driving. Experiments show that HE-Drive not only achieves state-of-the-art performance (i.e., reduces the average collision rate by 71% than VAD) and efficiency (i.e., 1.9X faster than SparseDrive) on the challenging nuScenes and OpenScene datasets but also provides the most comfortable driving experience on real-world data.For more information, visit the project website: https://jmwang0117.github.io/HE-Drive/.
OccRWKV: Rethinking Efficient 3D Semantic Occupancy Prediction with Linear Complexity
Sep 30, 2024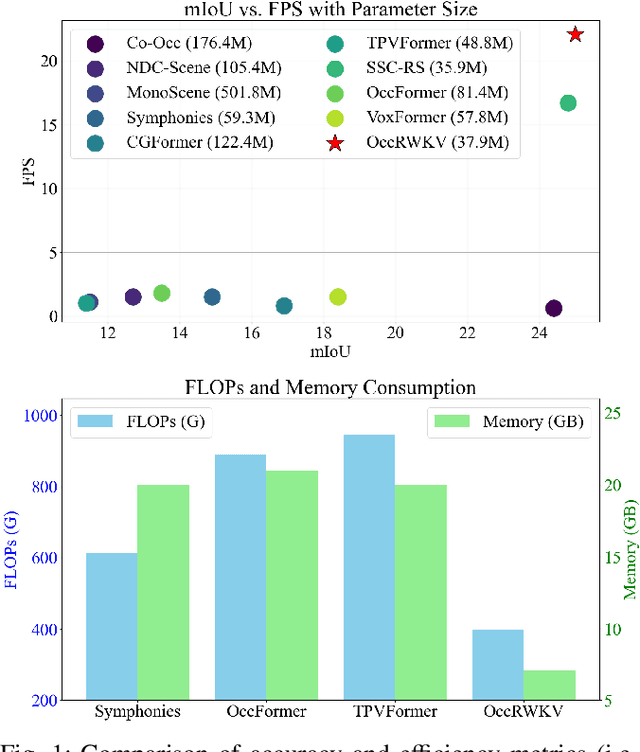
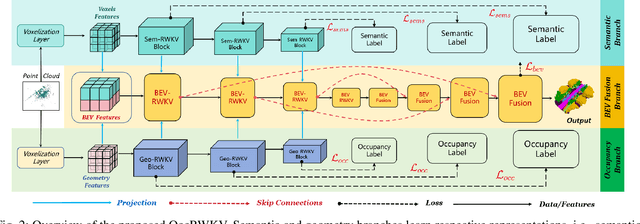
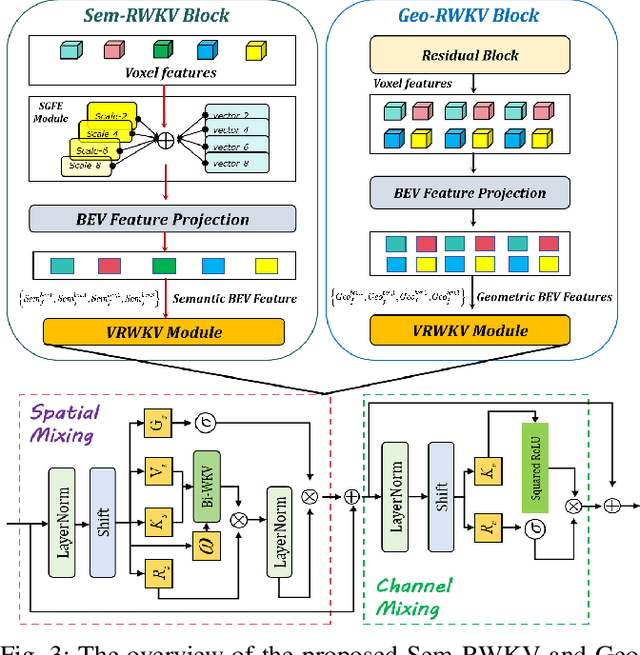
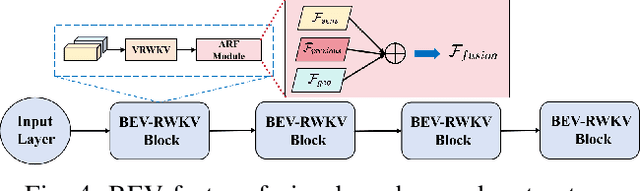
3D semantic occupancy prediction networks have demonstrated remarkable capabilities in reconstructing the geometric and semantic structure of 3D scenes, providing crucial information for robot navigation and autonomous driving systems. However, due to their large overhead from dense network structure designs, existing networks face challenges balancing accuracy and latency.In this paper, we introduce OccRWKV, an efficient semantic occupancy network inspired by Receptance Weighted Key Value (RWKV). OccRWKV separates semantics, occupancy prediction, and feature fusion into distinct branches, each incorporating Sem-RWKV and Geo-RWKV blocks. These blocks are designed to capture long-range dependencies, enabling the network to learn domain-specific representation (i.e., semantics and geometry), which enhances prediction accuracy. Leveraging the sparse nature of real-world 3D occupancy, we reduce computational overhead by projecting features into the bird's-eye view (BEV) space and propose a BEV-RWKV block for efficient feature enhancement and fusion. This enables real-time inference at 22.2 FPS without compromising performance. Experiments demonstrate that OccRWKV outperforms the state-of-the-art methods on the SemanticKITTI dataset, achieving a mIoU of 25.1 while being 20 times faster than the best baseline, Co-Occ, making it suitable for real-time deployment on robots to enhance autonomous navigation efficiency. Code and video are available on our project page: \url{https://jmwang0117.github.io/OccRWKV/}.
PlanAgent: A Multi-modal Large Language Agent for Closed-loop Vehicle Motion Planning
Jun 04, 2024



Vehicle motion planning is an essential component of autonomous driving technology. Current rule-based vehicle motion planning methods perform satisfactorily in common scenarios but struggle to generalize to long-tailed situations. Meanwhile, learning-based methods have yet to achieve superior performance over rule-based approaches in large-scale closed-loop scenarios. To address these issues, we propose PlanAgent, the first mid-to-mid planning system based on a Multi-modal Large Language Model (MLLM). MLLM is used as a cognitive agent to introduce human-like knowledge, interpretability, and common-sense reasoning into the closed-loop planning. Specifically, PlanAgent leverages the power of MLLM through three core modules. First, an Environment Transformation module constructs a Bird's Eye View (BEV) map and a lane-graph-based textual description from the environment as inputs. Second, a Reasoning Engine module introduces a hierarchical chain-of-thought from scene understanding to lateral and longitudinal motion instructions, culminating in planner code generation. Last, a Reflection module is integrated to simulate and evaluate the generated planner for reducing MLLM's uncertainty. PlanAgent is endowed with the common-sense reasoning and generalization capability of MLLM, which empowers it to effectively tackle both common and complex long-tailed scenarios. Our proposed PlanAgent is evaluated on the large-scale and challenging nuPlan benchmarks. A comprehensive set of experiments convincingly demonstrates that PlanAgent outperforms the existing state-of-the-art in the closed-loop motion planning task. Codes will be soon released.