 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGFusion: Dual-guided Fusion for Robust Multi-Modal 3D Object Detection
Nov 13, 2025As a critical task in autonomous driving perception systems, 3D object detection is used to identify and track key objects, such as vehicles and pedestrians. However, detecting distant, small, or occluded objects (hard instances) remains a challenge, which directly compromises the safety of autonomous driving systems. We observe that existing multi-modal 3D object detection methods often follow a single-guided paradigm, failing to account for the differences in information density of hard instances between modalities. In this work, we propose DGFusion, based on the Dual-guided paradigm, which fully inherits the advantages of the Point-guide-Image paradigm and integrates the Image-guide-Point paradigm to address the limitations of the single paradigms. The core of DGFusion, the Difficulty-aware Instance Pair Matcher (DIPM), performs instance-level feature matching based on difficulty to generate easy and hard instance pairs, while the Dual-guided Modules exploit the advantages of both pair types to enable effective multi-modal feature fusion. Experimental results demonstrate that our DGFusion outperforms the baseline methods, with respective improvements of +1.0\% mAP, +0.8\% NDS, and +1.3\% average recall on nuScenes. Extensive experiments demonstrate consistent robustness gains for hard instance detection across ego-distance, size, visibility, and small-scale training scenarios.
Beyond Imitation: Constraint-Aware Trajectory Generation with Flow Matching For End-to-End Autonomous Driving
Oct 30, 2025Planning is a critical component of end-to-end autonomous driving. However, prevailing imitation learning methods often suffer from mode collapse, failing to produce diverse trajectory hypotheses. Meanwhile, existing generative approaches struggle to incorporate crucial safety and physical constraints directly into the generative process, necessitating an additional optimization stage to refine their outputs. To address these limitations, we propose CATG, a novel planning framework that leverages Constrained Flow Matching. Concretely, CATG explicitly models the flow matching process, which inherently mitigates mode collapse and allows for flexible guidance from various conditioning signals. Our primary contribution is the novel imposition of explicit constraints directly within the flow matching process, ensuring that the generated trajectories adhere to vital safety and kinematic rules. Secondly, CATG parameterizes driving aggressiveness as a control signal during generation, enabling precise manipulation of trajectory style. Notably, on the NavSim v2 challenge, CATG achieved 2nd place with an EPDMS score of 51.31 and was honored with the Innovation Award.
Towards Real-World Rumor Detection: Anomaly Detection Framework with Graph Supervised Contrastive Learning
Aug 10, 2025Current rumor detection methods based on propagation structure learning predominately treat rumor detection as a class-balanced classification task on limited labeled data. However, real-world social media data exhibits an imbalanced distribution with a minority of rumors among massive regular posts. To address the data scarcity and imbalance issues, we construct two large-scale conversation datasets from Weibo and Twitter and analyze the domain distributions. We find obvious differences between rumor and non-rumor distributions, with non-rumors mostly in entertainment domains while rumors concentrate in news, indicating the conformity of rumor detection to an anomaly detection paradigm. Correspondingly, we propose the Anomaly Detection framework with Graph Supervised Contrastive Learning (AD-GSCL). It heuristically treats unlabeled data as non-rumors and adapts graph contrastive learning for rumor detection. Extensive experiments demonstrate AD-GSCL's superiority under class-balanced, imbalanced, and few-shot conditions. Our findings provide valuable insights for real-world rumor detection featuring imbalanced data distributions.
* This paper is accepted by COLING2025
Propagation Tree Is Not Deep: Adaptive Graph Contrastive Learning Approach for Rumor Detection
Aug 10, 2025Rumor detection on social media has become increasingly important. Most existing graph-based models presume rumor propagation trees (RPTs) have deep structures and learn sequential stance features along branches. However, through statistical analysis on real-world datasets, we find RPTs exhibit wide structures, with most nodes being shallow 1-level replies. To focus learning on intensive substructures, we propose Rumor Adaptive Graph Contrastive Learning (RAGCL) method with adaptive view augmentation guided by node centralities. We summarize three principles for RPT augmentation: 1) exempt root nodes, 2) retain deep reply nodes, 3) preserve lower-level nodes in deep sections. We employ node dropping, attribute masking and edge dropping with probabilities from centrality-based importance scores to generate views. A graph contrastive objective then learns robust rumor representations. Extensive experiments on four benchmark datasets demonstrate RAGCL outperforms state-of-the-art methods. Our work reveals the wide-structure nature of RPTs and contributes an effective graph contrastive learning approach tailored for rumor detection through principled adaptive augmentation. The proposed principles and augmentation techniques can potentially benefit other applications involving tree-structured graphs.
* This paper is accepted by AAAI2024
Enhancing Rumor Detection Methods with Propagation Structure Infused Language Model
Aug 10, 2025Pretrained Language Models (PLMs) have excelled in various Natural Language Processing tasks, benefiting from large-scale pretraining and self-attention mechanism's ability to capture long-range dependencies. However, their performance on social media application tasks like rumor detection remains suboptimal. We attribute this to mismatches between pretraining corpora and social texts, inadequate handling of unique social symbols, and pretraining tasks ill-suited for modeling user engagements implicit in propagation structures. To address these issues, we propose a continue pretraining strategy called Post Engagement Prediction (PEP) to infuse information from propagation structures into PLMs. PEP makes models to predict root, branch, and parent relations between posts, capturing interactions of stance and sentiment crucial for rumor detection. We also curate and release large-scale Twitter corpus: TwitterCorpus (269GB text), and two unlabeled claim conversation datasets with propagation structures (UTwitter and UWeibo). Utilizing these resources and PEP strategy, we train a Twitter-tailored PLM called SoLM. Extensive experiments demonstrate PEP significantly boosts rumor detection performance across universal and social media PLMs, even in few-shot scenarios. On benchmark datasets, PEP enhances baseline models by 1.0-3.7\% accuracy, even enabling it to outperform current state-of-the-art methods on multiple datasets. SoLM alone, without high-level modules, also achieves competitive results, highlighting the strategy's effectiveness in learning discriminative post interaction features.
* This paper is accepted by COLING2025
Two Tasks, One Goal: Uniting Motion and Planning for Excellent End To End Autonomous Driving Performance
Apr 17, 2025End-to-end autonomous driving has made impressive progress in recent years. Former end-to-end autonomous driving approaches often decouple planning and motion tasks, treating them as separate modules. This separation overlooks the potential benefits that planning can gain from learning out-of-distribution data encountered in motion tasks. However, unifying these tasks poses significant challenges, such as constructing shared contextual representations and handling the unobservability of other vehicles' states. To address these challenges, we propose TTOG, a novel two-stage trajectory generation framework. In the first stage, a diverse set of trajectory candidates is generated, while the second stage focuses on refining these candidates through vehicle state information. To mitigate the issue of unavailable surrounding vehicle states, TTOG employs a self-vehicle data-trained state estimator, subsequently extended to other vehicles. Furthermore, we introduce ECSA (equivariant context-sharing scene adapter) to enhance the generalization of scene representations across different agents. Experimental results demonstrate that TTOG achieves state-of-the-art performance across both planning and motion tasks. Notably, on the challenging open-loop nuScenes dataset, TTOG reduces the L2 distance by 36.06\%. Furthermore, on the closed-loop Bench2Drive dataset, our approach achieves a 22\% improvement in the driving score (DS), significantly outperforming existing baselines.
Don't Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving
Mar 05, 2025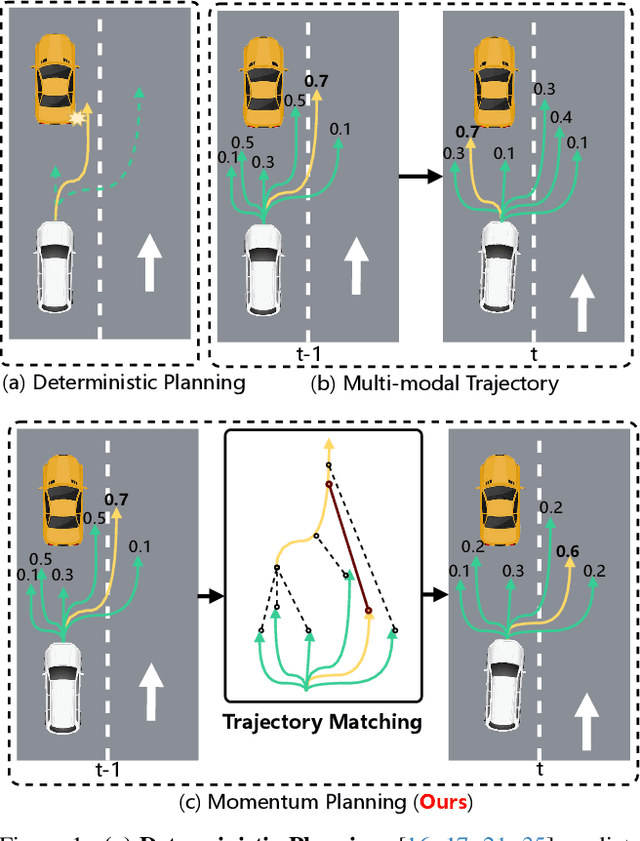


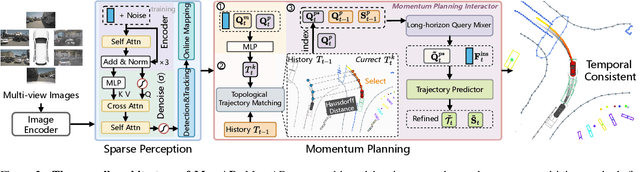
End-to-end autonomous driving frameworks enable seamless integration of perception and planning but often rely on one-shot trajectory prediction, which may lead to unstable control and vulnerability to occlusions in single-frame perception. To address this, we propose the Momentum-Aware Driving (MomAD) framework, which introduces trajectory momentum and perception momentum to stabilize and refine trajectory predictions. MomAD comprises two core components: (1) Topological Trajectory Matching (TTM) employs Hausdorff Distance to select the optimal planning query that aligns with prior paths to ensure coherence;(2) Momentum Planning Interactor (MPI) cross-attends the selected planning query with historical queries to expand static and dynamic perception files. This enriched query, in turn, helps regenerate long-horizon trajectory and reduce collision risks. To mitigate noise arising from dynamic environments and detection errors, we introduce robust instance denoising during training, enabling the planning model to focus on critical signals and improve its robustness. We also propose a novel Trajectory Prediction Consistency (TPC) metric to quantitatively assess planning stability. Experiments on the nuScenes dataset demonstrate that MomAD achieves superior long-term consistency (>=3s) compared to SOTA methods. Moreover, evaluations on the curated Turning-nuScenes shows that MomAD reduces the collision rate by 26% and improves TPC by 0.97m (33.45%) over a 6s prediction horizon, while closedloop on Bench2Drive demonstrates an up to 16.3% improvement in success rate.
SVTRv2: CTC Beats Encoder-Decoder Models in Scene Text Recognition
Nov 24, 2024Connectionist temporal classification (CTC)-based scene text recognition (STR) methods, e.g., SVTR, are widely employed in OCR applications, mainly due to their simple architecture, which only contains a visual model and a CTC-aligned linear classifier, and therefore fast inference. However, they generally have worse accuracy than encoder-decoder-based methods (EDTRs), particularly in challenging scenarios. In this paper, we propose SVTRv2, a CTC model that beats leading EDTRs in both accuracy and inference speed. SVTRv2 introduces novel upgrades to handle text irregularity and utilize linguistic context, which endows it with the capability to deal with challenging and diverse text instances. First, a multi-size resizing (MSR) strategy is proposed to adaptively resize the text and maintain its readability. Meanwhile, we introduce a feature rearrangement module (FRM) to ensure that visual features accommodate the alignment requirement of CTC well, thus alleviating the alignment puzzle. Second, we propose a semantic guidance module (SGM). It integrates linguistic context into the visual model, allowing it to leverage language information for improved accuracy. Moreover, SGM can be omitted at the inference stage and would not increase the inference cost. We evaluate SVTRv2 in both standard and recent challenging benchmarks, where SVTRv2 is fairly compared with 24 mainstream STR models across multiple scenarios, including different types of text irregularity, languages, and long text. The results indicate that SVTRv2 surpasses all the EDTRs across the scenarios in terms of accuracy and speed. Code is available at https://github.com/Topdu/OpenOCR.
CWT-Net: Super-resolution of Histopathology Images Using a Cross-scale Wavelet-based Transformer
Sep 11, 2024Super-resolution (SR) aims to enhance the quality of low-resolution images and has been widely applied in medical imaging. We found that the design principles of most existing methods are influenced by SR tasks based on real-world images and do not take into account the significance of the multi-level structure in pathological images, even if they can achieve respectable objective metric evaluations. In this work, we delve into two super-resolution working paradigms and propose a novel network called CWT-Net, which leverages cross-scale image wavelet transform and Transformer architecture. Our network consists of two branches: one dedicated to learning super-resolution and the other to high-frequency wavelet features. To generate high-resolution histopathology images, the Transformer module shares and fuses features from both branches at various stages. Notably, we have designed a specialized wavelet reconstruction module to effectively enhance the wavelet domain features and enable the network to operate in different modes, allowing for the introduction of additional relevant information from cross-scale images. Our experimental results demonstrate that our model significantly outperforms state-of-the-art methods in both performance and visualization evaluations and can substantially boost the accuracy of image diagnostic networks.
Out of Length Text Recognition with Sub-String Matching
Jul 17, 2024



Scene Text Recognition (STR) methods have demonstrated robust performance in word-level text recognition. However, in applications the text image is sometimes long due to detected with multiple horizontal words. It triggers the requirement to build long text recognition models from readily available short word-level text datasets, which has been less studied previously. In this paper, we term this the Out of Length (OOL) text recognition. We establish a new Long Text Benchmark (LTB) to facilitate the assessment of different methods in long text recognition. Meanwhile, we propose a novel method called OOL Text Recognition with sub-String Matching (SMTR). SMTR comprises two cross-attention-based modules: one encodes a sub-string containing multiple characters into next and previous queries, and the other employs the queries to attend to the image features, matching the sub-string and simultaneously recognizing its next and previous character. SMTR can recognize text of arbitrary length by iterating the process above. To avoid being trapped in recognizing highly similar sub-strings, we introduce a regularization training to compel SMTR to effectively discover subtle differences between similar sub-strings for precise matching. In addition, we propose an inference augmentation to alleviate confusion caused by identical sub-strings and improve the overall recognition efficiency. Extensive experimental results reveal that SMTR, even when trained exclusively on short text, outperforms existing methods in public short text benchmarks and exhibits a clear advantage on LTB. Code: \url{https://github.com/Topdu/OpenOCR}.