 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Guided Scene Text Recognition
Paper and Code
Jan 31, 2024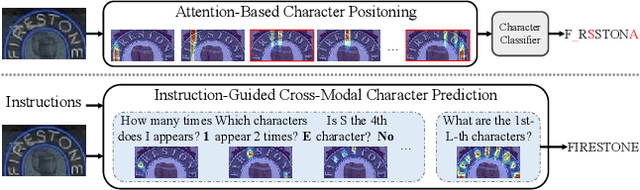


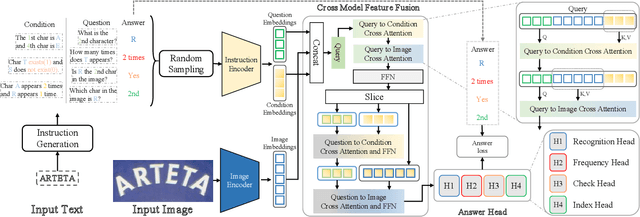
Multi-modal models have shown appealing performance in visual tasks recently, as instruction-guided training has evoked the ability to understand fine-grained visual content. However, current methods cannot be trivially applied to scene text recognition (STR) due to the gap between natural and text images. In this paper, we introduce a novel paradigm that formulates STR as an instruction learning problem, and propose instruction-guided scene text recognition (IGTR) to achieve effective cross-modal learning. IGTR first generates rich and diverse instruction triplets of <condition,question,answer>, serving as guidance for nuanced text image understanding. Then, we devise an architecture with dedicated cross-modal feature fusion module, and multi-task answer head to effectively fuse the required instruction and image features for answering questions. Built upon these designs, IGTR facilitates accurate text recognition by comprehending character attributes. Experiments on English and Chinese benchmarks show that IGTR outperforms existing models by significant margins. Furthermore, by adjusting the instructions, IGTR enables various recognition schemes. These include zero-shot prediction, where the model is trained based on instructions not explicitly targeting character recognition, and the recognition of rarely appearing and morphologically similar characters, which were previous challenges for existing models.