 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphWorld: Long-Horizon Planning with World Models for End-to-End Autonomous Driving
Jun 15, 2026End-to-end autonomous driving has made significant progress by unifying perception, prediction, and planning within a single learning framework, achieving strong performance in short-horizon decision making. However, most existing E2E-AD methods remain confined to short-horizon planning and lack the ability to model long-term temporal dependencies, which severely limits their generalization and security in complex and highly interactive driving scenarios. In this work, we propose GraphWorld, an E2E-AD framework that explicitly enhances long-horizon planning through latent world modeling. We introduce an Ego-Centric Interaction Graph, which adaptively models critical neighboring agents based on spatial proximity, and propagates relational context to planning queries via cross-node cross-attention. We present a World-State-Conditioned Planning that learns ego-centric latent world representations by modeling interactions between an ego vehicle and surrounding agents. This latent world state captures key interaction dynamics and safety-relevant semantics, and serves as a conditioning signal to guide long-horizon, safety-aware trajectory planning. Extensive experiments on Bench2Drive, NAVSIMv1/2, and nuScenes demonstrate that GraphWorld significantly reduces collision rates and improves long-horizon planning performance, validating its effectiveness in complex driving environments.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
DGFusion: Dual-guided Fusion for Robust Multi-Modal 3D Object Detection
Nov 13, 2025As a critical task in autonomous driving perception systems, 3D object detection is used to identify and track key objects, such as vehicles and pedestrians. However, detecting distant, small, or occluded objects (hard instances) remains a challenge, which directly compromises the safety of autonomous driving systems. We observe that existing multi-modal 3D object detection methods often follow a single-guided paradigm, failing to account for the differences in information density of hard instances between modalities. In this work, we propose DGFusion, based on the Dual-guided paradigm, which fully inherits the advantages of the Point-guide-Image paradigm and integrates the Image-guide-Point paradigm to address the limitations of the single paradigms. The core of DGFusion, the Difficulty-aware Instance Pair Matcher (DIPM), performs instance-level feature matching based on difficulty to generate easy and hard instance pairs, while the Dual-guided Modules exploit the advantages of both pair types to enable effective multi-modal feature fusion. Experimental results demonstrate that our DGFusion outperforms the baseline methods, with respective improvements of +1.0\% mAP, +0.8\% NDS, and +1.3\% average recall on nuScenes. Extensive experiments demonstrate consistent robustness gains for hard instance detection across ego-distance, size, visibility, and small-scale training scenarios.
Beyond Imitation: Constraint-Aware Trajectory Generation with Flow Matching For End-to-End Autonomous Driving
Oct 30, 2025Planning is a critical component of end-to-end autonomous driving. However, prevailing imitation learning methods often suffer from mode collapse, failing to produce diverse trajectory hypotheses. Meanwhile, existing generative approaches struggle to incorporate crucial safety and physical constraints directly into the generative process, necessitating an additional optimization stage to refine their outputs. To address these limitations, we propose CATG, a novel planning framework that leverages Constrained Flow Matching. Concretely, CATG explicitly models the flow matching process, which inherently mitigates mode collapse and allows for flexible guidance from various conditioning signals. Our primary contribution is the novel imposition of explicit constraints directly within the flow matching process, ensuring that the generated trajectories adhere to vital safety and kinematic rules. Secondly, CATG parameterizes driving aggressiveness as a control signal during generation, enabling precise manipulation of trajectory style. Notably, on the NavSim v2 challenge, CATG achieved 2nd place with an EPDMS score of 51.31 and was honored with the Innovation Award.
CWT-Net: Super-resolution of Histopathology Images Using a Cross-scale Wavelet-based Transformer
Sep 11, 2024Super-resolution (SR) aims to enhance the quality of low-resolution images and has been widely applied in medical imaging. We found that the design principles of most existing methods are influenced by SR tasks based on real-world images and do not take into account the significance of the multi-level structure in pathological images, even if they can achieve respectable objective metric evaluations. In this work, we delve into two super-resolution working paradigms and propose a novel network called CWT-Net, which leverages cross-scale image wavelet transform and Transformer architecture. Our network consists of two branches: one dedicated to learning super-resolution and the other to high-frequency wavelet features. To generate high-resolution histopathology images, the Transformer module shares and fuses features from both branches at various stages. Notably, we have designed a specialized wavelet reconstruction module to effectively enhance the wavelet domain features and enable the network to operate in different modes, allowing for the introduction of additional relevant information from cross-scale images. Our experimental results demonstrate that our model significantly outperforms state-of-the-art methods in both performance and visualization evaluations and can substantially boost the accuracy of image diagnostic networks.
SparseDet: A Simple and Effective Framework for Fully Sparse LiDAR-based 3D Object Detection
Jun 16, 2024



LiDAR-based sparse 3D object detection plays a crucial role in autonomous driving applications due to its computational efficiency advantages. Existing methods either use the features of a single central voxel as an object proxy, or treat an aggregated cluster of foreground points as an object proxy. However, the former lacks the ability to aggregate contextual information, resulting in insufficient information expression in object proxies. The latter relies on multi-stage pipelines and auxiliary tasks, which reduce the inference speed. To maintain the efficiency of the sparse framework while fully aggregating contextual information, in this work, we propose SparseDet which designs sparse queries as object proxies. It introduces two key modules, the Local Multi-scale Feature Aggregation (LMFA) module and the Global Feature Aggregation (GFA) module, aiming to fully capture the contextual information, thereby enhancing the ability of the proxies to represent objects. Where LMFA sub-module achieves feature fusion across different scales for sparse key voxels %which does this through via coordinate transformations and using nearest neighbor relationships to capture object-level details and local contextual information, GFA sub-module uses self-attention mechanisms to selectively aggregate the features of the key voxels across the entire scene for capturing scene-level contextual information. Experiments on nuScenes and KITTI demonstrate the effectiveness of our method. Specifically, on nuScene, SparseDet surpasses the previous best sparse detector VoxelNeXt by 2.2\% mAP with 13.5 FPS, and on KITTI, it surpasses VoxelNeXt by 1.12\% $\mathbf{AP_{3D}}$ on hard level tasks with 17.9 FPS.
ContrastAlign: Toward Robust BEV Feature Alignment via Contrastive Learning for Multi-Modal 3D Object Detection
May 27, 2024



In the field of 3D object detection tasks, fusing heterogeneous features from LiDAR and camera sensors into a unified Bird's Eye View (BEV) representation is a widely adopted paradigm. However, existing methods are often compromised by imprecise sensor calibration, resulting in feature misalignment in LiDAR-camera BEV fusion. Moreover, such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a novel ContrastAlign approach that utilizes contrastive learning to enhance the alignment of heterogeneous modalities, thereby improving the robustness of the fusion process. Specifically, our approach includes the L-Instance module, which directly outputs LiDAR instance features within LiDAR BEV features. Then, we introduce the C-Instance module, which predicts camera instance features through RoI (Region of Interest) pooling on the camera BEV features. We propose the InstanceFusion module, which utilizes contrastive learning to generate similar instance features across heterogeneous modalities. We then use graph matching to calculate the similarity between the neighboring camera instance features and the similarity instance features to complete the alignment of instance features. Our method achieves state-of-the-art performance, with an mAP of 70.3%, surpassing BEVFusion by 1.8% on the nuScenes validation set. Importantly, our method outperforms BEVFusion by 7.3% under conditions with misalignment noise.
GraphBEV: Towards Robust BEV Feature Alignment for Multi-Modal 3D Object Detection
Mar 18, 2024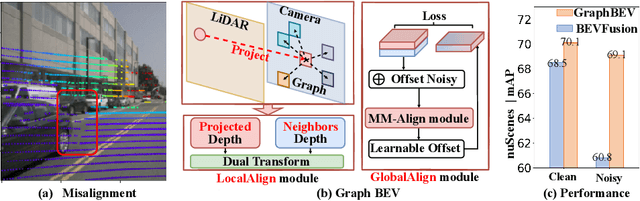
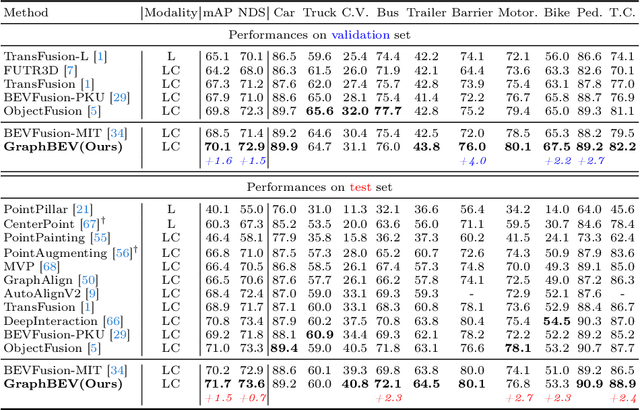
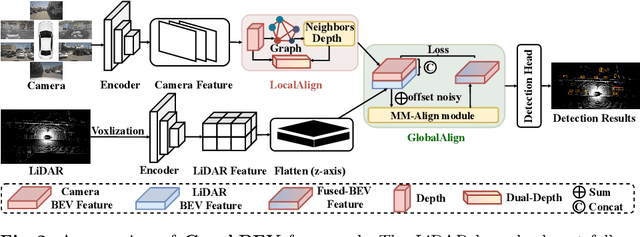
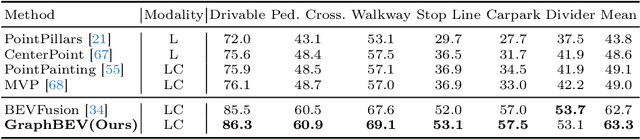
Integrating LiDAR and camera information into Bird's-Eye-View (BEV) representation has emerged as a crucial aspect of 3D object detection in autonomous driving. However, existing methods are susceptible to the inaccurate calibration relationship between LiDAR and the camera sensor. Such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a robust fusion framework called Graph BEV. Addressing errors caused by inaccurate point cloud projection, we introduce a Local Align module that employs neighbor-aware depth features via Graph matching. Additionally, we propose a Global Align module to rectify the misalignment between LiDAR and camera BEV features. Our Graph BEV framework achieves state-of-the-art performance, with an mAP of 70.1\%, surpassing BEV Fusion by 1.6\% on the nuscenes validation set. Importantly, our Graph BEV outperforms BEV Fusion by 8.3\% under conditions with misalignment noise.
Robustness-Aware 3D Object Detection in Autonomous Driving: A Review and Outlook
Jan 12, 2024In the realm of modern autonomous driving, the perception system is indispensable for accurately assessing the state of the surrounding environment, thereby enabling informed prediction and planning. Key to this system is 3D object detection methods, that utilize vehicle-mounted sensors such as LiDAR and cameras to identify the size, category, and location of nearby objects. Despite the surge in 3D object detection methods aimed at enhancing detection precision and efficiency, there is a gap in the literature that systematically examines their resilience against environmental variations, noise, and weather changes. This study emphasizes the importance of robustness, alongside accuracy and latency, in evaluating perception systems under practical scenarios. Our work presents an extensive survey of camera-based, LiDAR-based, and multimodal 3D object detection algorithms, thoroughly evaluating their trade-off between accuracy, latency, and robustness, particularly on datasets like KITTI-C and nuScenes-C to ensure fair comparisons. Among these,multimodal 3D detection approaches exhibit superior robustness and a novel taxonomy is introduced to reorganize its literature for enhanced clarity. This survey aims to offer a more practical perspective on the current capabilities and constraints of 3D object detection algorithms in real-world applications, thus steering future research towards robustness-centric advancements
RoboFusion: Towards Robust Multi-Modal 3D obiect Detection via SAM
Jan 08, 2024



Multi-modal 3D object detectors are dedicated to exploring secure and reliable perception systems for autonomous driving (AD). However, while achieving state-of-the-art (SOTA) performance on clean benchmark datasets, they tend to overlook the complexity and harsh conditions of real-world environments. Meanwhile, with the emergence of visual foundation models (VFMs), opportunities and challenges are presented for improving the robustness and generalization of multi-modal 3D object detection in autonomous driving. Therefore, we propose RoboFusion, a robust framework that leverages VFMs like SAM to tackle out-of-distribution (OOD) noise scenarios. We first adapt the original SAM for autonomous driving scenarios named SAM-AD. To align SAM or SAM-AD with multi-modal methods, we then introduce AD-FPN for upsampling the image features extracted by SAM. We employ wavelet decomposition to denoise the depth-guided images for further noise reduction and weather interference. Lastly, we employ self-attention mechanisms to adaptively reweight the fused features, enhancing informative features while suppressing excess noise. In summary, our RoboFusion gradually reduces noise by leveraging the generalization and robustness of VFMs, thereby enhancing the resilience of multi-modal 3D object detection. Consequently, our RoboFusion achieves state-of-the-art performance in noisy scenarios, as demonstrated by the KITTI-C and nuScenes-C benchmarks.