 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTOS: A LLM-Driven Multi-topic Opinion Simulation Framework for Exploring Echo Chamber Dynamics
Oct 14, 2025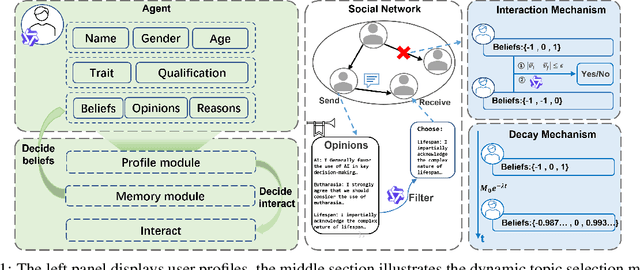
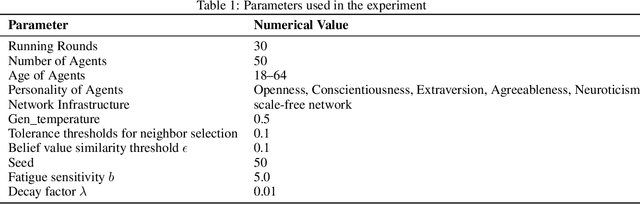
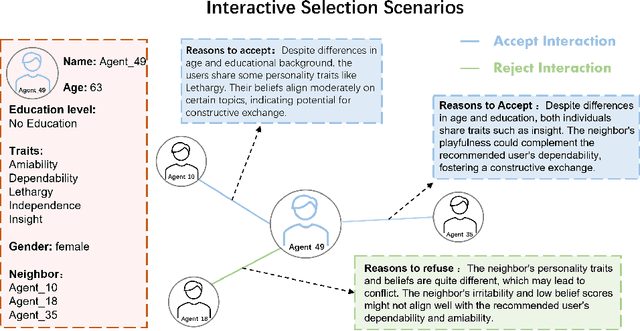
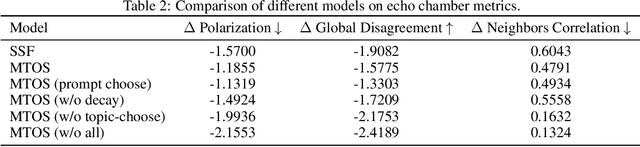
The polarization of opinions, information segregation, and cognitive biases on social media have attracted significant academic attention. In real-world networks, information often spans multiple interrelated topics, posing challenges for opinion evolution and highlighting the need for frameworks that simulate interactions among topics. Existing studies based on large language models (LLMs) focus largely on single topics, limiting the capture of cognitive transfer in multi-topic, cross-domain contexts. Traditional numerical models, meanwhile, simplify complex linguistic attitudes into discrete values, lacking interpretability, behavioral consistency, and the ability to integrate multiple topics. To address these issues, we propose Multi-topic Opinion Simulation (MTOS), a social simulation framework integrating multi-topic contexts with LLMs. MTOS leverages LLMs alongside short-term and long-term memory, incorporates multiple user-selection interaction mechanisms and dynamic topic-selection strategies, and employs a belief decay mechanism to enable perspective updates across topics. We conduct extensive experiments on MTOS, varying topic numbers, correlation types, and performing ablation studies to assess features such as group polarization and local consistency. Results show that multi-topic settings significantly alter polarization trends: positively correlated topics amplify echo chambers, negatively correlated topics inhibit them, and irrelevant topics also mitigate echo chamber effects through resource competition. Compared with numerical models, LLM-based agents realistically simulate dynamic opinion changes, reproduce linguistic features of news texts, and capture complex human reasoning, improving simulation interpretability and system stability.
HASH-RAG: Bridging Deep Hashing with Retriever for Efficient, Fine Retrieval and Augmented Generation
May 22, 2025Retrieval-Augmented Generation (RAG) encounters efficiency challenges when scaling to massive knowledge bases while preserving contextual relevance. We propose Hash-RAG, a framework that integrates deep hashing techniques with systematic optimizations to address these limitations. Our queries directly learn binary hash codes from knowledgebase code, eliminating intermediate feature extraction steps, and significantly reducing storage and computational overhead. Building upon this hash-based efficient retrieval framework, we establish the foundation for fine-grained chunking. Consequently, we design a Prompt-Guided Chunk-to-Context (PGCC) module that leverages retrieved hash-indexed propositions and their original document segments through prompt engineering to enhance the LLM's contextual awareness. Experimental evaluations on NQ, TriviaQA, and HotpotQA datasets demonstrate that our approach achieves a 90% reduction in retrieval time compared to conventional methods while maintaining considerate recall performance. Additionally, The proposed system outperforms retrieval/non-retrieval baselines by 1.4-4.3% in EM scores.
Accelerating Adaptive Retrieval Augmented Generation via Instruction-Driven Representation Reduction of Retrieval Overlaps
May 19, 2025



Retrieval-augmented generation (RAG) has emerged as a pivotal method for expanding the knowledge of large language models. To handle complex queries more effectively, researchers developed Adaptive-RAG (A-RAG) to enhance the generated quality through multiple interactions with external knowledge bases. Despite its effectiveness, A-RAG exacerbates the pre-existing efficiency challenges inherent in RAG, which are attributable to its reliance on multiple iterations of generation. Existing A-RAG approaches process all retrieved contents from scratch. However, they ignore the situation where there is a significant overlap in the content of the retrieval results across rounds. The overlapping content is redundantly represented, which leads to a large proportion of repeated computations, thus affecting the overall efficiency. To address this issue, this paper introduces a model-agnostic approach that can be generally applied to A-RAG methods, which is dedicated to reducing the redundant representation process caused by the overlapping of retrieval results. Specifically, we use cache access and parallel generation to speed up the prefilling and decoding stages respectively. Additionally, we also propose an instruction-driven module to further guide the model to more effectively attend to each part of the content in a more suitable way for LLMs. Experiments show that our approach achieves 2.79 and 2.33 times significant acceleration on average for prefilling and decoding respectively while maintaining equal generation quality.
Can LLM be a Good Path Planner based on Prompt Engineering? Mitigating the Hallucination for Path Planning
Aug 27, 2024Spatial reasoning in Large Language Models (LLMs) is the foundation for embodied intelligence. However, even in simple maze environments, LLMs still encounter challenges in long-term path-planning, primarily influenced by their spatial hallucination and context inconsistency hallucination by long-term reasoning. To address this challenge, this study proposes an innovative model, Spatial-to-Relational Transformation and Curriculum Q-Learning (S2RCQL). To address the spatial hallucination of LLMs, we propose the Spatial-to-Relational approach, which transforms spatial prompts into entity relations and paths representing entity relation chains. This approach fully taps the potential of LLMs in terms of sequential thinking. As a result, we design a path-planning algorithm based on Q-learning to mitigate the context inconsistency hallucination, which enhances the reasoning ability of LLMs. Using the Q-value of state-action as auxiliary information for prompts, we correct the hallucinations of LLMs, thereby guiding LLMs to learn the optimal path. Finally, we propose a reverse curriculum learning technique based on LLMs to further mitigate the context inconsistency hallucination. LLMs can rapidly accumulate successful experiences by reducing task difficulty and leveraging them to tackle more complex tasks. We performed comprehensive experiments based on Baidu's self-developed LLM: ERNIE-Bot 4.0. The results showed that our S2RCQL achieved a 23%--40% improvement in both success and optimality rates compared with advanced prompt engineering.
Compensate Quantization Errors+: Quantized Models Are Inquisitive Learners
Jul 22, 2024



Large Language Models (LLMs) showcase remarkable performance and robust deductive capabilities, yet their expansive size complicates deployment and raises environmental concerns due to substantial resource consumption. The recent development of a quantization technique known as Learnable Singular-value Increment (LSI) has addressed some of these quantization challenges. Leveraging insights from LSI and our extensive research, we have developed innovative methods that enhance the performance of quantized LLMs, particularly in low-bit settings. Our methods consistently deliver state-of-the-art results across various quantization scenarios and offer deep theoretical insights into the quantization process, elucidating the potential of quantized models for widespread application.
Compensate Quantization Errors: Make Weights Hierarchical to Compensate Each Other
Jun 24, 2024Emergent Large Language Models (LLMs) use their extraordinary performance and powerful deduction capacity to discern from traditional language models. However, the expenses of computational resources and storage for these LLMs are stunning, quantization then arises as a trending conversation. To address accuracy decay caused by quantization, two streams of works in post-training quantization methods stand out. One uses other weights to compensate existing quantization error, while the other transfers the quantization difficulty to other parts in the model. Combining both merits, we introduce Learnable Singular value Increment (LSI) as an advanced solution. LSI uses Singular Value Decomposition to extract singular values of the weights and make them learnable to help weights compensate each other conditioned on activation. Incorporating LSI with existing techniques, we achieve state-of-the-art performance in diverse quantization settings, no matter in weight-only, weight-activation or extremely low bit scenarios. By unleashing the potential of LSI, efficient finetuning on quantized model is no longer a prohibitive problem.
Bootstrap 3D Reconstructed Scenes from 3D Gaussian Splatting
Apr 29, 2024



Recent developments in neural rendering techniques have greatly enhanced the rendering of photo-realistic 3D scenes across both academic and commercial fields. The latest method, known as 3D Gaussian Splatting (3D-GS), has set new benchmarks for rendering quality and speed. Nevertheless, the limitations of 3D-GS become pronounced in synthesizing new viewpoints, especially for views that greatly deviate from those seen during training. Additionally, issues such as dilation and aliasing arise when zooming in or out. These challenges can all be traced back to a single underlying issue: insufficient sampling. In our paper, we present a bootstrapping method that significantly addresses this problem. This approach employs a diffusion model to enhance the rendering of novel views using trained 3D-GS, thereby streamlining the training process. Our results indicate that bootstrapping effectively reduces artifacts, as well as clear enhancements on the evaluation metrics. Furthermore, we show that our method is versatile and can be easily integrated, allowing various 3D reconstruction projects to benefit from our approach.
Lossless Acceleration of Large Language Model via Adaptive N-gram Parallel Decoding
Apr 10, 2024



While Large Language Models (LLMs) have shown remarkable abilities, they are hindered by significant resource consumption and considerable latency due to autoregressive processing. In this study, we introduce Adaptive N-gram Parallel Decoding (ANPD), an innovative and lossless approach that accelerates inference by allowing the simultaneous generation of multiple tokens. ANPD incorporates a two-stage approach: it begins with a rapid drafting phase that employs an N-gram module, which adapts based on the current interactive context, followed by a verification phase, during which the original LLM assesses and confirms the proposed tokens. Consequently, ANPD preserves the integrity of the LLM's original output while enhancing processing speed. We further leverage a multi-level architecture for the N-gram module to enhance the precision of the initial draft, consequently reducing inference latency. ANPD eliminates the need for retraining or extra GPU memory, making it an efficient and plug-and-play enhancement. In our experiments, models such as LLaMA and its fine-tuned variants have shown speed improvements up to 3.67x, validating the effectiveness of our proposed ANPD.
Dynamic Resolution Guidance for Facial Expression Recognition
Apr 09, 2024
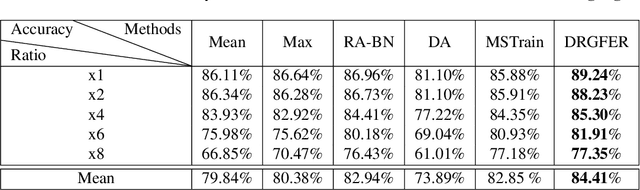
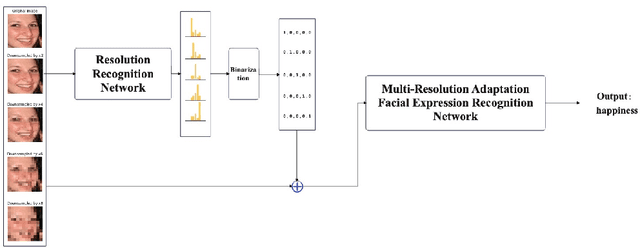
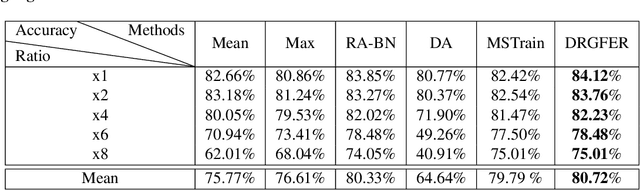
Facial expression recognition (FER) is vital for human-computer interaction and emotion analysis, yet recognizing expressions in low-resolution images remains challenging. This paper introduces a practical method called Dynamic Resolution Guidance for Facial Expression Recognition (DRGFER) to effectively recognize facial expressions in images with varying resolutions without compromising FER model accuracy. Our framework comprises two main components: the Resolution Recognition Network (RRN) and the Multi-Resolution Adaptation Facial Expression Recognition Network (MRAFER). The RRN determines image resolution, outputs a binary vector, and the MRAFER assigns images to suitable facial expression recognition networks based on resolution. We evaluated DRGFER on widely-used datasets RAFDB and FERPlus, demonstrating that our method retains optimal model performance at each resolution and outperforms alternative resolution approaches. The proposed framework exhibits robustness against resolution variations and facial expressions, offering a promising solution for real-world applications.
PMFSNet: Polarized Multi-scale Feature Self-attention Network For Lightweight Medical Image Segmentation
Jan 15, 2024



Current state-of-the-art medical image segmentation methods prioritize accuracy but often at the expense of increased computational demands and larger model sizes. Applying these large-scale models to the relatively limited scale of medical image datasets tends to induce redundant computation, complicating the process without the necessary benefits. This approach not only adds complexity but also presents challenges for the integration and deployment of lightweight models on edge devices. For instance, recent transformer-based models have excelled in 2D and 3D medical image segmentation due to their extensive receptive fields and high parameter count. However, their effectiveness comes with a risk of overfitting when applied to small datasets and often neglects the vital inductive biases of Convolutional Neural Networks (CNNs), essential for local feature representation. In this work, we propose PMFSNet, a novel medical imaging segmentation model that effectively balances global and local feature processing while avoiding the computational redundancy typical in larger models. PMFSNet streamlines the UNet-based hierarchical structure and simplifies the self-attention mechanism's computational complexity, making it suitable for lightweight applications. It incorporates a plug-and-play PMFS block, a multi-scale feature enhancement module based on attention mechanisms, to capture long-term dependencies. Extensive comprehensive results demonstrate that even with a model (less than 1 million parameters), our method achieves superior performance in various segmentation tasks across different data scales. It achieves (IoU) metrics of 84.68%, 82.02%, and 78.82% on public datasets of teeth CT (CBCT), ovarian tumors ultrasound(MMOTU), and skin lesions dermoscopy images (ISIC 2018), respectively. The source code is available at https://github.com/yykzjh/PMFSNet.