 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Resolution Guidance for Facial Expression Recognition
Apr 09, 2024
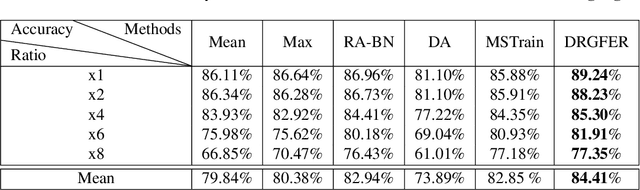
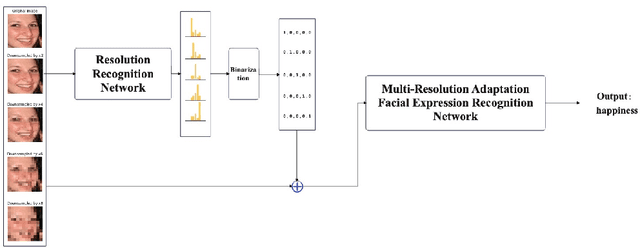
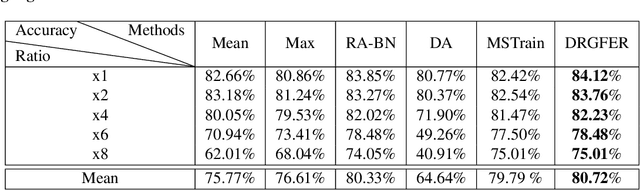
Facial expression recognition (FER) is vital for human-computer interaction and emotion analysis, yet recognizing expressions in low-resolution images remains challenging. This paper introduces a practical method called Dynamic Resolution Guidance for Facial Expression Recognition (DRGFER) to effectively recognize facial expressions in images with varying resolutions without compromising FER model accuracy. Our framework comprises two main components: the Resolution Recognition Network (RRN) and the Multi-Resolution Adaptation Facial Expression Recognition Network (MRAFER). The RRN determines image resolution, outputs a binary vector, and the MRAFER assigns images to suitable facial expression recognition networks based on resolution. We evaluated DRGFER on widely-used datasets RAFDB and FERPlus, demonstrating that our method retains optimal model performance at each resolution and outperforms alternative resolution approaches. The proposed framework exhibits robustness against resolution variations and facial expressions, offering a promising solution for real-world applications.
PMFSNet: Polarized Multi-scale Feature Self-attention Network For Lightweight Medical Image Segmentation
Jan 15, 2024



Current state-of-the-art medical image segmentation methods prioritize accuracy but often at the expense of increased computational demands and larger model sizes. Applying these large-scale models to the relatively limited scale of medical image datasets tends to induce redundant computation, complicating the process without the necessary benefits. This approach not only adds complexity but also presents challenges for the integration and deployment of lightweight models on edge devices. For instance, recent transformer-based models have excelled in 2D and 3D medical image segmentation due to their extensive receptive fields and high parameter count. However, their effectiveness comes with a risk of overfitting when applied to small datasets and often neglects the vital inductive biases of Convolutional Neural Networks (CNNs), essential for local feature representation. In this work, we propose PMFSNet, a novel medical imaging segmentation model that effectively balances global and local feature processing while avoiding the computational redundancy typical in larger models. PMFSNet streamlines the UNet-based hierarchical structure and simplifies the self-attention mechanism's computational complexity, making it suitable for lightweight applications. It incorporates a plug-and-play PMFS block, a multi-scale feature enhancement module based on attention mechanisms, to capture long-term dependencies. Extensive comprehensive results demonstrate that even with a model (less than 1 million parameters), our method achieves superior performance in various segmentation tasks across different data scales. It achieves (IoU) metrics of 84.68%, 82.02%, and 78.82% on public datasets of teeth CT (CBCT), ovarian tumors ultrasound(MMOTU), and skin lesions dermoscopy images (ISIC 2018), respectively. The source code is available at https://github.com/yykzjh/PMFSNet.
Multi Loss-based Feature Fusion and Top Two Voting Ensemble Decision Strategy for Facial Expression Recognition in the Wild
Nov 06, 2023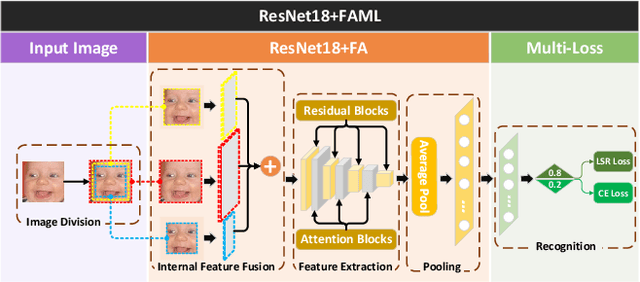
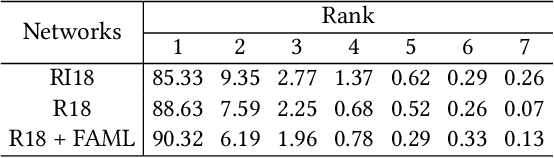
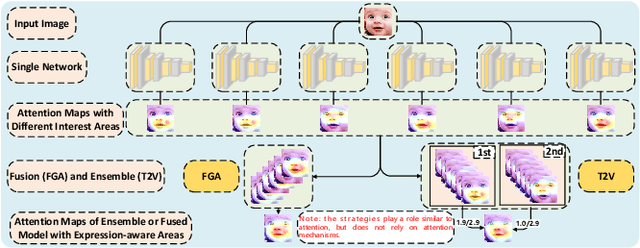
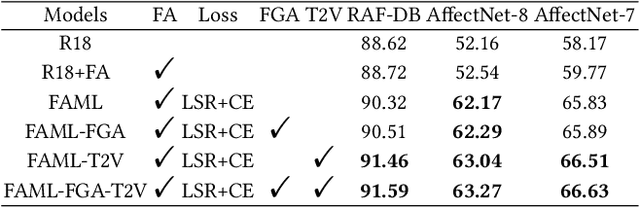
Facial expression recognition (FER) in the wild is a challenging task affected by the image quality and has attracted broad interest in computer vision. There is no research using feature fusion and ensemble strategy for FER simultaneously. Different from previous studies, this paper applies both internal feature fusion for a single model and feature fusion among multiple networks, as well as the ensemble strategy. This paper proposes one novel single model named R18+FAML, as well as one ensemble model named R18+FAML-FGA-T2V to improve the performance of the FER in the wild. Based on the structure of ResNet18 (R18), R18+FAML combines internal Feature fusion and three Attention blocks using Multiple Loss functions (FAML) to improve the diversity of the feature extraction. To improve the performance of R18+FAML, we propose a Feature fusion among networks based on the Genetic Algorithm (FGA), which can fuse the convolution kernels for feature extraction of multiple networks. On the basis of R18+FAML and FGA, we propose one ensemble strategy, i.e., the Top Two Voting (T2V) to support the classification of FER, which can consider more classification information comprehensively. Combining the above strategies, R18+FAML-FGA-T2V can focus on the main expression-aware areas. Extensive experiments demonstrate that our single model R18+FAML and the ensemble model R18+FAML-FGA-T2V achieve the accuracies of $\left( 90.32, 62.17, 65.83 \right)\%$ and $\left( 91.59, 63.27, 66.63 \right)\%$ on three challenging unbalanced FER datasets RAF-DB, AffectNet-8 and AffectNet-7 respectively, both outperforming the state-of-the-art results.
Uncover Common Facial Expressions in Terracotta Warriors: A Deep Learning Approach
May 11, 2021


Can advanced deep learning technologies be applied to analyze some ancient humanistic arts? Can deep learning technologies be directly applied to special scenes such as facial expression analysis of Terracotta Warriors? The big challenging is that the facial features of the Terracotta Warriors are very different from today's people. We found that it is very poor to directly use the models that have been trained on other classic facial expression datasets to analyze the facial expressions of the Terracotta Warriors. At the same time, the lack of public high-quality facial expression data of the Terracotta Warriors also limits the use of deep learning technologies. Therefore, we firstly use Generative Adversarial Networks (GANs) to generate enough high-quality facial expression data for subsequent training and recognition. We also verify the effectiveness of this approach. For the first time, this paper uses deep learning technologies to find common facial expressions of general and postured Terracotta Warriors. These results will provide an updated technical means for the research of art of the Terracotta Warriors and shine lights on the research of other ancient arts.