 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV-Track VLA: Embodied Aerial Tracking via Vision-Language-Action Models
Apr 02, 2026Embodied visual tracking is crucial for Unmanned Aerial Vehicles (UAVs) executing complex real-world tasks. In dynamic urban scenarios with complex semantic requirements, Vision-Language-Action (VLA) models show great promise due to their cross-modal fusion and continuous action generation capabilities. To benchmark multimodal tracking in such environments, we construct a dedicated evaluation benchmark and a large-scale dataset encompassing over 890K frames, 176 tasks, and 85 diverse objects. Furthermore, to address temporal feature redundancy and the lack of spatial geometric priors in existing VLA models, we propose an improved VLA tracking model, UAV-Track VLA. Built upon the $π_{0.5}$ architecture, our model introduces a temporal compression net to efficiently capture inter-frame dynamics. Additionally, a parallel dual-branch decoder comprising a spatial-aware auxiliary grounding head and a flow matching action expert is designed to decouple cross-modal features and generate fine-grained continuous actions. Systematic experiments in the CARLA simulator validate the superior end-to-end performance of our method. Notably, in challenging long-distance pedestrian tracking tasks, UAV-Track VLA achieves a 61.76\% success rate and 269.65 average tracking frames, significantly outperforming existing baselines. Furthermore, it demonstrates robust zero-shot generalization in unseen environments and reduces single-step inference latency by 33.4\% (to 0.0571s) compared to the original $π_{0.5}$, enabling highly efficient, real-time UAV control. Data samples and demonstration videos are available at: https://github.com/Hub-Tian/UAV-Track\_VLA.
ExpressMind: A Multimodal Pretrained Large Language Model for Expressway Operation
Mar 17, 2026The current expressway operation relies on rule-based and isolated models, which limits the ability to jointly analyze knowledge across different systems. Meanwhile, Large Language Models (LLMs) are increasingly applied in intelligent transportation, advancing traffic models from algorithmic to cognitive intelligence. However, general LLMs are unable to effectively understand the regulations and causal relationships of events in unconventional scenarios in the expressway field. Therefore, this paper constructs a pre-trained multimodal large language model (MLLM) for expressways, ExpressMind, which serves as the cognitive core for intelligent expressway operations. This paper constructs the industry's first full-stack expressway dataset, encompassing traffic knowledge texts, emergency reasoning chains, and annotated video events to overcome data scarcity. This paper proposes a dual-layer LLM pre-training paradigm based on self-supervised training and unsupervised learning. Additionally, this study introduces a Graph-Augmented RAG framework to dynamically index the expressway knowledge base. To enhance reasoning for expressway incident response strategies, we develop a RL-aligned Chain-of-Thought (RL-CoT) mechanism that enforces consistency between model reasoning and expert problem-solving heuristics for incident handling. Finally, ExpressMind integrates a cross-modal encoder to align the dynamic feature sequences under the visual and textual channels, enabling it to understand traffic scenes in both video and image modalities. Extensive experiments on our newly released multi-modal expressway benchmark demonstrate that ExpressMind comprehensively outperforms existing baselines in event detection, safety response generation, and complex traffic analysis. The code and data are available at: https://wanderhee.github.io/ExpressMind/.
OpenCOOD-Air: Prompting Heterogeneous Ground-Air Collaborative Perception with Spatial Conversion and Offset Prediction
Mar 14, 2026While Vehicle-to-Vehicle (V2V) collaboration extends sensing ranges through multi-agent data sharing, its reliability remains severely constrained by ground-level occlusions and the limited perspective of chassis-mounted sensors, which often result in critical perception blind spots. We propose OpenCOOD-Air, a novel framework that integrates UAVs as extensible platforms into V2V collaborative perception to overcome these constraints. To mitigate gradient interference from ground-air domain gaps and data sparsity, we adopt a transfer learning strategy to fine-tune UAV weights from pre-trained V2V models. To prevent the spatial information loss inherent in this transition, we formulate ground-air collaborative perception as a heterogeneous integration task with explicit altitude supervision and introduce a Cross-Domain Spatial Converter (CDSC) and a Spatial Offset Prediction Transformer (SOPT). Furthermore, we present the OPV2V-Air benchmark to validate the transition from V2V to Vehicle-to-Vehicle-to-UAV. Compared to state-of-the-art methods, our approach improves 2D and 3D AP@0.7 by 4% and 7%, respectively.
AIR-VLA: Vision-Language-Action Systems for Aerial Manipulation
Jan 29, 2026While Vision-Language-Action (VLA) models have achieved remarkable success in ground-based embodied intelligence, their application to Aerial Manipulation Systems (AMS) remains a largely unexplored frontier. The inherent characteristics of AMS, including floating-base dynamics, strong coupling between the UAV and the manipulator, and the multi-step, long-horizon nature of operational tasks, pose severe challenges to existing VLA paradigms designed for static or 2D mobile bases. To bridge this gap, we propose AIR-VLA, the first VLA benchmark specifically tailored for aerial manipulation. We construct a physics-based simulation environment and release a high-quality multimodal dataset comprising 3000 manually teleoperated demonstrations, covering base manipulation, object & spatial understanding, semantic reasoning, and long-horizon planning. Leveraging this platform, we systematically evaluate mainstream VLA models and state-of-the-art VLM models. Our experiments not only validate the feasibility of transferring VLA paradigms to aerial systems but also, through multi-dimensional metrics tailored to aerial tasks, reveal the capabilities and boundaries of current models regarding UAV mobility, manipulator control, and high-level planning. AIR-VLA establishes a standardized testbed and data foundation for future research in general-purpose aerial robotics. The resource of AIR-VLA will be available at https://anonymous.4open.science/r/AIR-VLA-dataset-B5CC/.
CogRail: Benchmarking VLMs in Cognitive Intrusion Perception for Intelligent Railway Transportation Systems
Jan 14, 2026Accurate and early perception of potential intrusion targets is essential for ensuring the safety of railway transportation systems. However, most existing systems focus narrowly on object classification within fixed visual scopes and apply rule-based heuristics to determine intrusion status, often overlooking targets that pose latent intrusion risks. Anticipating such risks requires the cognition of spatial context and temporal dynamics for the object of interest (OOI), which presents challenges for conventional visual models. To facilitate deep intrusion perception, we introduce a novel benchmark, CogRail, which integrates curated open-source datasets with cognitively driven question-answer annotations to support spatio-temporal reasoning and prediction. Building upon this benchmark, we conduct a systematic evaluation of state-of-the-art visual-language models (VLMs) using multimodal prompts to identify their strengths and limitations in this domain. Furthermore, we fine-tune VLMs for better performance and propose a joint fine-tuning framework that integrates three core tasks, position perception, movement prediction, and threat analysis, facilitating effective adaptation of general-purpose foundation models into specialized models tailored for cognitive intrusion perception. Extensive experiments reveal that current large-scale multimodal models struggle with the complex spatial-temporal reasoning required by the cognitive intrusion perception task, underscoring the limitations of existing foundation models in this safety-critical domain. In contrast, our proposed joint fine-tuning framework significantly enhances model performance by enabling targeted adaptation to domain-specific reasoning demands, highlighting the advantages of structured multi-task learning in improving both accuracy and interpretability. Code will be available at https://github.com/Hub-Tian/CogRail.
AstroReview: An LLM-driven Multi-Agent Framework for Telescope Proposal Peer Review and Refinement
Dec 31, 2025Competitive access to modern observatories has intensified as proposal volumes outpace available telescope time, making timely, consistent, and transparent peer review a critical bottleneck for the advancement of astronomy. Automating parts of this process is therefore both scientifically significant and operationally necessary to ensure fair allocation and reproducible decisions at scale. We present AstroReview, an open-source, agent-based framework that automates proposal review in three stages: (i) novelty and scientific merit, (ii) feasibility and expected yield, and (iii) meta-review and reliability verification. Task isolation and explicit reasoning traces curb hallucinations and improve transparency. Without any domain specific fine tuning, AstroReview used in our experiments only for the last stage, correctly identifies genuinely accepted proposals with an accuracy of 87%. The AstroReview in Action module replicates the review and refinement loop; with its integrated Proposal Authoring Agent, the acceptance rate of revised drafts increases by 66% after two iterations, showing that iterative feedback combined with automated meta-review and reliability verification delivers measurable quality gains. Together, these results point to a practical path toward scalable, auditable, and higher throughput proposal review for resource limited facilities.
A Comprehensive Survey on Underwater Acoustic Target Positioning and Tracking: Progress, Challenges, and Perspectives
Jun 17, 2025Underwater target tracking technology plays a pivotal role in marine resource exploration, environmental monitoring, and national defense security. Given that acoustic waves represent an effective medium for long-distance transmission in aquatic environments, underwater acoustic target tracking has become a prominent research area of underwater communications and networking. Existing literature reviews often offer a narrow perspective or inadequately address the paradigm shifts driven by emerging technologies like deep learning and reinforcement learning. To address these gaps, this work presents a systematic survey of this field and introduces an innovative multidimensional taxonomy framework based on target scale, sensor perception modes, and sensor collaboration patterns. Within this framework, we comprehensively survey the literature (more than 180 publications) over the period 2016-2025, spanning from the theoretical foundations to diverse algorithmic approaches in underwater acoustic target tracking. Particularly, we emphasize the transformative potential and recent advancements of machine learning techniques, including deep learning and reinforcement learning, in enhancing the performance and adaptability of underwater tracking systems. Finally, this survey concludes by identifying key challenges in the field and proposing future avenues based on emerging technologies such as federated learning, blockchain, embodied intelligence, and large models.
Breaking Bad Molecules: Are MLLMs Ready for Structure-Level Molecular Detoxification?
Jun 12, 2025Toxicity remains a leading cause of early-stage drug development failure. Despite advances in molecular design and property prediction, the task of molecular toxicity repair - generating structurally valid molecular alternatives with reduced toxicity - has not yet been systematically defined or benchmarked. To fill this gap, we introduce ToxiMol, the first benchmark task for general-purpose Multimodal Large Language Models (MLLMs) focused on molecular toxicity repair. We construct a standardized dataset covering 11 primary tasks and 560 representative toxic molecules spanning diverse mechanisms and granularities. We design a prompt annotation pipeline with mechanism-aware and task-adaptive capabilities, informed by expert toxicological knowledge. In parallel, we propose an automated evaluation framework, ToxiEval, which integrates toxicity endpoint prediction, synthetic accessibility, drug-likeness, and structural similarity into a high-throughput evaluation chain for repair success. We systematically assess nearly 30 mainstream general-purpose MLLMs and design multiple ablation studies to analyze key factors such as evaluation criteria, candidate diversity, and failure attribution. Experimental results show that although current MLLMs still face significant challenges on this task, they begin to demonstrate promising capabilities in toxicity understanding, semantic constraint adherence, and structure-aware molecule editing.
LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
May 06, 2025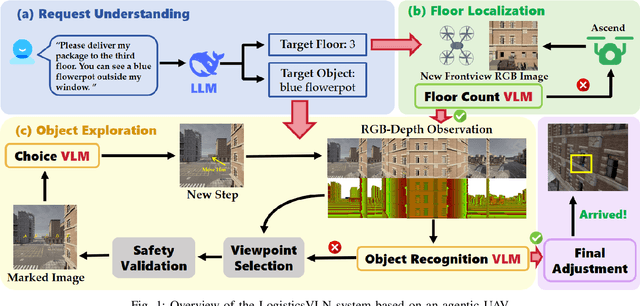
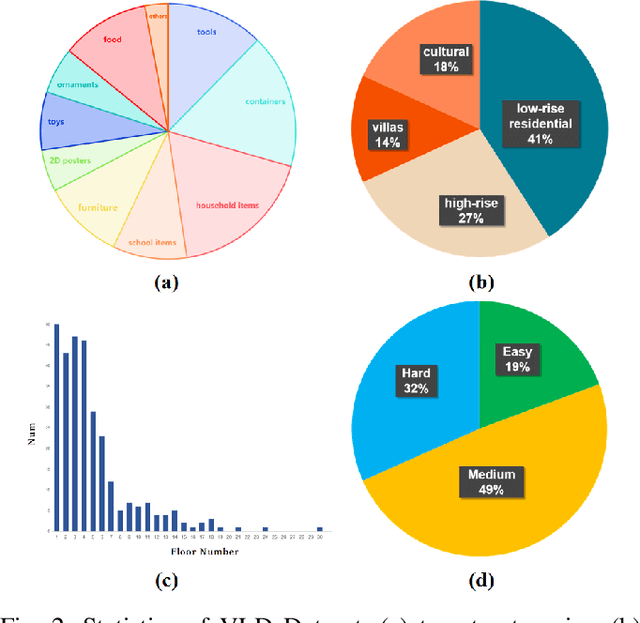

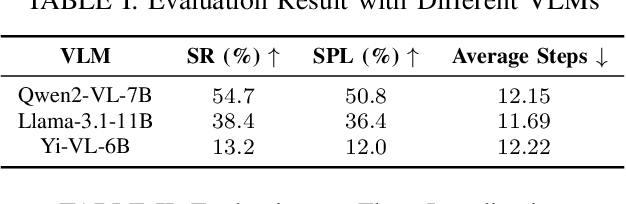
The growing demand for intelligent logistics, particularly fine-grained terminal delivery, underscores the need for autonomous UAV (Unmanned Aerial Vehicle)-based delivery systems. However, most existing last-mile delivery studies rely on ground robots, while current UAV-based Vision-Language Navigation (VLN) tasks primarily focus on coarse-grained, long-range goals, making them unsuitable for precise terminal delivery. To bridge this gap, we propose LogisticsVLN, a scalable aerial delivery system built on multimodal large language models (MLLMs) for autonomous terminal delivery. LogisticsVLN integrates lightweight Large Language Models (LLMs) and Visual-Language Models (VLMs) in a modular pipeline for request understanding, floor localization, object detection, and action-decision making. To support research and evaluation in this new setting, we construct the Vision-Language Delivery (VLD) dataset within the CARLA simulator. Experimental results on the VLD dataset showcase the feasibility of the LogisticsVLN system. In addition, we conduct subtask-level evaluations of each module of our system, offering valuable insights for improving the robustness and real-world deployment of foundation model-based vision-language delivery systems.
CoordField: Coordination Field for Agentic UAV Task Allocation In Low-altitude Urban Scenarios
Apr 30, 2025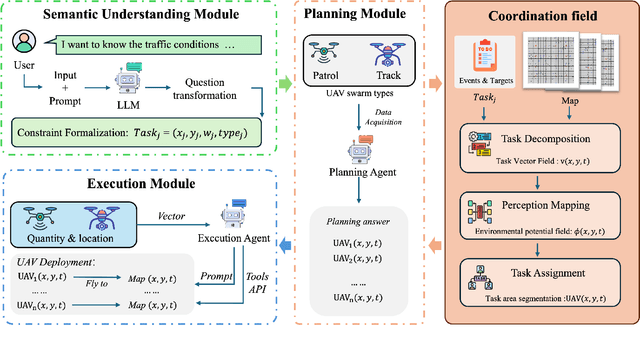
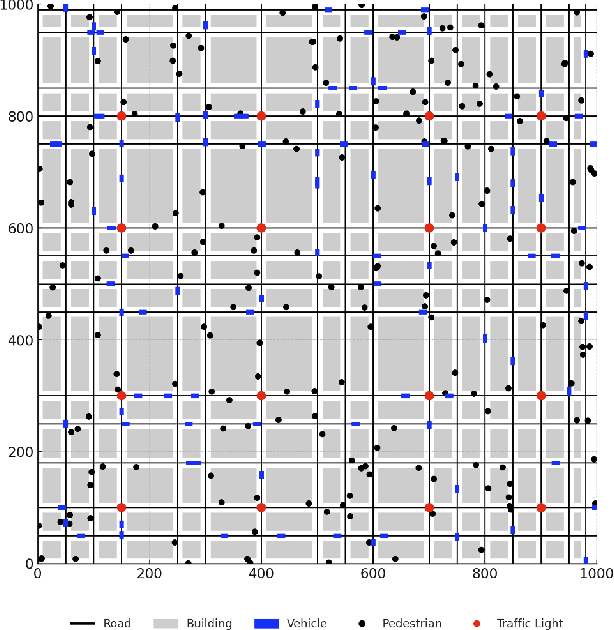
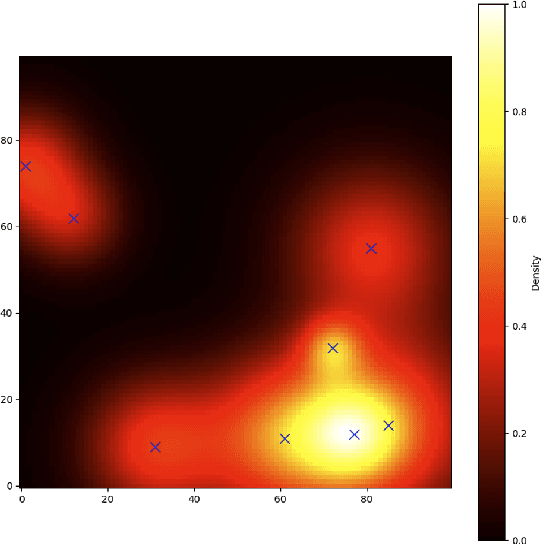
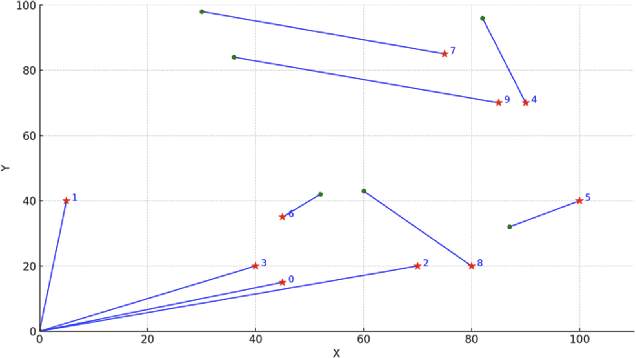
With the increasing demand for heterogeneous Unmanned Aerial Vehicle (UAV) swarms to perform complex tasks in urban environments, system design now faces major challenges, including efficient semantic understanding, flexible task planning, and the ability to dynamically adjust coordination strategies in response to evolving environmental conditions and continuously changing task requirements. To address the limitations of existing approaches, this paper proposes coordination field agentic system for coordinating heterogeneous UAV swarms in complex urban scenarios. In this system, large language models (LLMs) is responsible for interpreting high-level human instructions and converting them into executable commands for the UAV swarms, such as patrol and target tracking. Subsequently, a Coordination field mechanism is proposed to guide UAV motion and task selection, enabling decentralized and adaptive allocation of emergent tasks. A total of 50 rounds of comparative testing were conducted across different models in a 2D simulation space to evaluate their performance. Experimental results demonstrate that the proposed system achieves superior performance in terms of task coverage, response time, and adaptability to dynamic changes.