 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPD: A Multi-sensory Interactive Perception Dataset for Embodied Intelligent Driving
Nov 08, 2024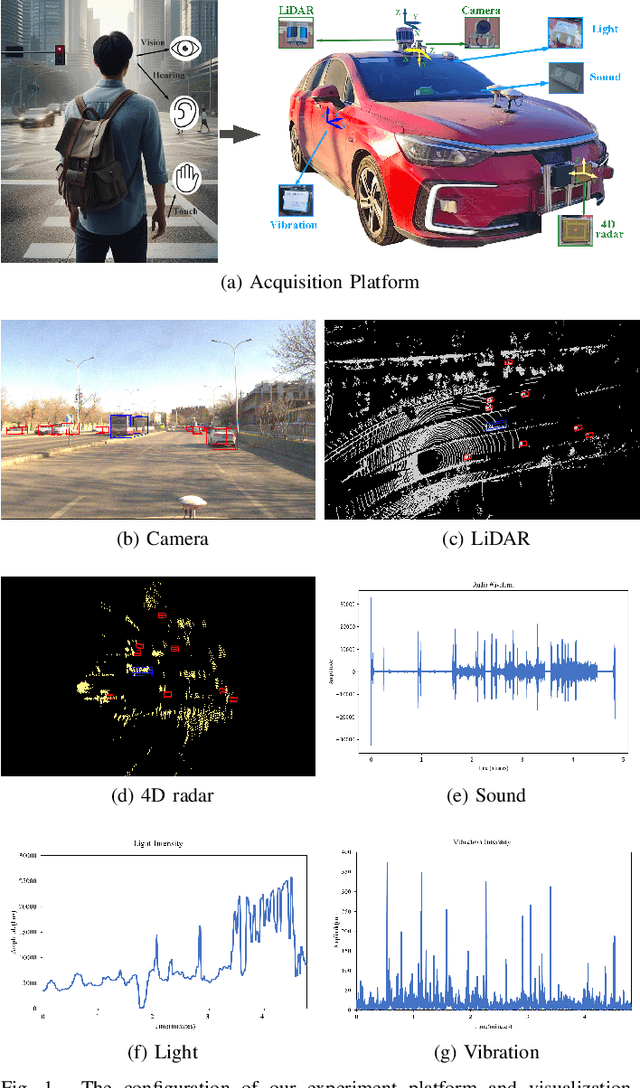
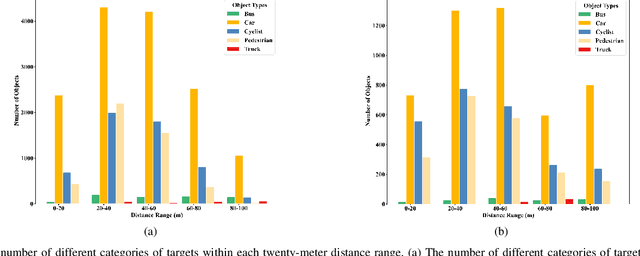
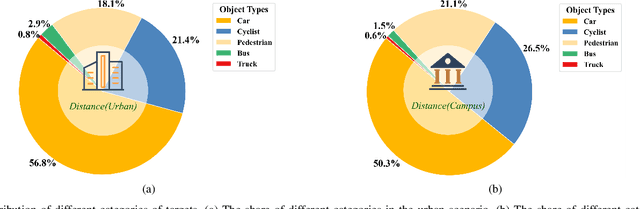
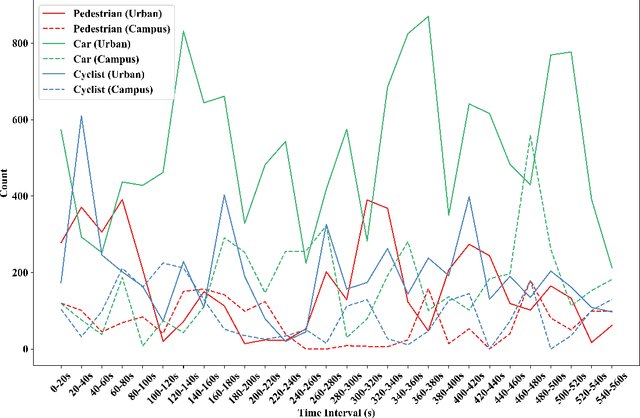
During the process of driving, humans usually rely on multiple senses to gather information and make decisions. Analogously, in order to achieve embodied intelligence in autonomous driving, it is essential to integrate multidimensional sensory information in order to facilitate interaction with the environment. However, the current multi-modal fusion sensing schemes often neglect these additional sensory inputs, hindering the realization of fully autonomous driving. This paper considers multi-sensory information and proposes a multi-modal interactive perception dataset named MIPD, enabling expanding the current autonomous driving algorithm framework, for supporting the research on embodied intelligent driving. In addition to the conventional camera, lidar, and 4D radar data, our dataset incorporates multiple sensor inputs including sound, light intensity, vibration intensity and vehicle speed to enrich the dataset comprehensiveness. Comprising 126 consecutive sequences, many exceeding twenty seconds, MIPD features over 8,500 meticulously synchronized and annotated frames. Moreover, it encompasses many challenging scenarios, covering various road and lighting conditions. The dataset has undergone thorough experimental validation, producing valuable insights for the exploration of next-generation autonomous driving frameworks.
Stereo Event-based Visual-Inertial Odometry
Mar 16, 2023
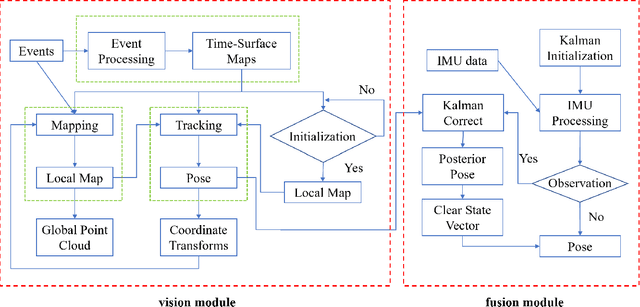
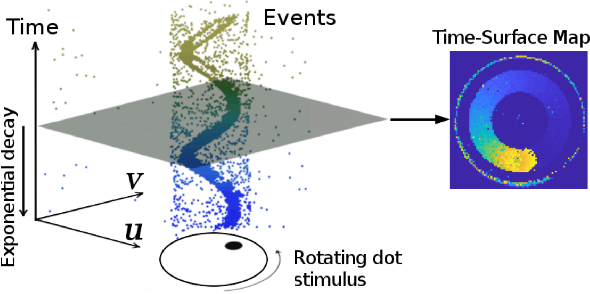

Event-based cameras are new type vision sensors whose pixels work independently and respond asynchronously to brightness change with microsecond resolution, instead of provide stand-ard intensity frames. Compared with traditional cameras, event-based cameras have low latency, no motion blur, and high dynamic range (HDR), which provide possibilities for robots to deal with some challenging scenes. We propose a visual-inertial odometry method for stereo event-cameras based on Kalman filtering. The visual module updates the camera pose relies on the edge alignment of a semi-dense 3D map to a 2D image, and the IMU module updates pose by midpoint method. We evaluate our method on public datasets in natural scenes with general 6-DoF motion and compare the results against ground truth. We show that the proposed pipeline provides improved accuracy over the result of a state-of-the-art visual odometry method for stereo event-cameras, while running in real-time on a standard CPU. To the best of our knowledge, this is the first published visual-inertial odometry algorithm for stereo event-cameras.
Contour Loss for Instance Segmentation via k-step Distance Transformation Image
Feb 22, 2021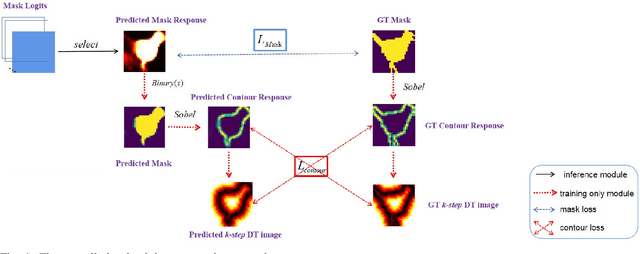
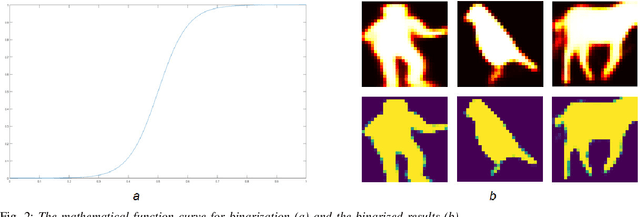


Instance segmentation aims to locate targets in the image and segment each target area at pixel level, which is one of the most important tasks in computer vision. Mask R-CNN is a classic method of instance segmentation, but we find that its predicted masks are unclear and inaccurate near contours. To cope with this problem, we draw on the idea of contour matching based on distance transformation image and propose a novel loss function, called contour loss. Contour loss is designed to specifically optimize the contour parts of the predicted masks, thus can assure more accurate instance segmentation. In order to make the proposed contour loss to be jointly trained under modern neural network frameworks, we design a differentiable k-step distance transformation image calculation module, which can approximately compute truncated distance transformation images of the predicted mask and corresponding ground-truth mask online. The proposed contour loss can be integrated into existing instance segmentation methods such as Mask R-CNN, and combined with their original loss functions without modification of the inference network structures, thus has strong versatility. Experimental results on COCO show that contour loss is effective, which can further improve instance segmentation performances.
Adaptive and Azimuth-Aware Fusion Network of Multimodal Local Features for 3D Object Detection
Oct 10, 2019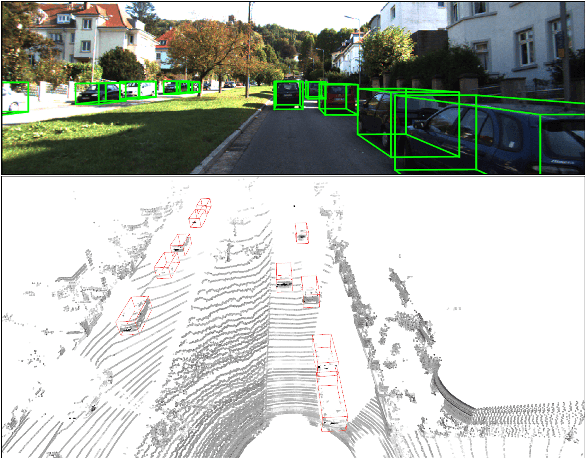

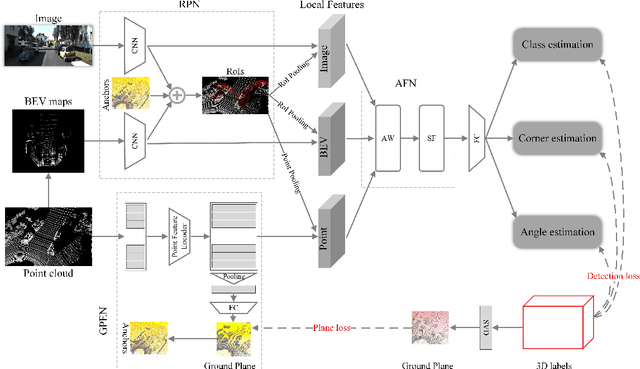

This paper focuses on the construction of stronger local features and the effective fusion of image and LiDAR data. We adopt different modalities of LiDAR data to generate richer features and present an adaptive and azimuth-aware network to aggregate local features from image, bird's eye view maps and point cloud. Our network mainly consists of three subnetworks: ground plane estimation network, region proposal network and adaptive fusion network. The ground plane estimation network extracts features of point cloud and predicts the parameters of a plane which are used for generating abundant 3D anchors. The region proposal network generates features of image and bird's eye view maps to output region proposals. To integrate heterogeneous image and point cloud features, the adaptive fusion network explicitly adjusts the intensity of multiple local features and achieves the orientation consistency between image and LiDAR data by introduce an azimuth-aware fusion module. Experiments are conducted on KITTI dataset and the results validate the advantages of our aggregation of multimodal local features and the adaptive fusion network.
M4CD: A Robust Change Detection Method for Intelligent Visual Surveillance
Feb 14, 2018

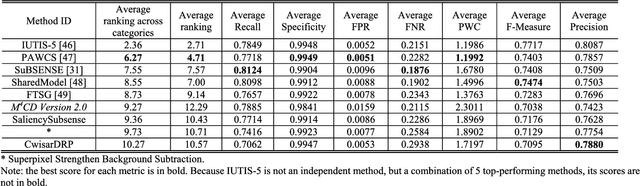

In this paper, we propose a robust change detection method for intelligent visual surveillance. This method, named M4CD, includes three major steps. Firstly, a sample-based background model that integrates color and texture cues is built and updated over time. Secondly, multiple heterogeneous features (including brightness variation, chromaticity variation, and texture variation) are extracted by comparing the input frame with the background model, and a multi-source learning strategy is designed to online estimate the probability distributions for both foreground and background. The three features are approximately conditionally independent, making multi-source learning feasible. Pixel-wise foreground posteriors are then estimated with Bayes rule. Finally, the Markov random field (MRF) optimization and heuristic post-processing techniques are used sequentially to improve accuracy. In particular, a two-layer MRF model is constructed to represent pixel-based and superpixel-based contextual constraints compactly. Experimental results on the CDnet dataset indicate that M4CD is robust under complex environments and ranks among the top methods.
Scene-Specific Pedestrian Detection Based on Parallel Vision
Dec 23, 2017



As a special type of object detection, pedestrian detection in generic scenes has made a significant progress trained with large amounts of labeled training data manually. While the models trained with generic dataset work bad when they are directly used in specific scenes. With special viewpoints, flow light and backgrounds, datasets from specific scenes are much different from the datasets from generic scenes. In order to make the generic scene pedestrian detectors work well in specific scenes, the labeled data from specific scenes are needed to adapt the models to the specific scenes. While labeling the data manually spends much time and money, especially for specific scenes, each time with a new specific scene, large amounts of images must be labeled. What's more, the labeling information is not so accurate in the pixels manually and different people make different labeling information. In this paper, we propose an ACP-based method, with augmented reality's help, we build the virtual world of specific scenes, and make people walking in the virtual scenes where it is possible for them to appear to solve this problem of lacking labeled data and the results show that data from virtual world is helpful to adapt generic pedestrian detectors to specific scenes.
Training and Testing Object Detectors with Virtual Images
Dec 22, 2017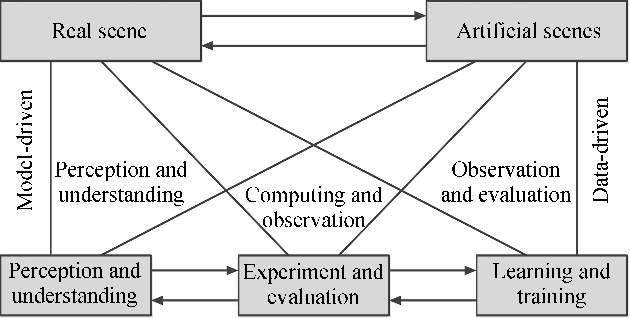



In the area of computer vision, deep learning has produced a variety of state-of-the-art models that rely on massive labeled data. However, collecting and annotating images from the real world has a great demand for labor and money investments and is usually too passive to build datasets with specific characteristics, such as small area of objects and high occlusion level. Under the framework of Parallel Vision, this paper presents a purposeful way to design artificial scenes and automatically generate virtual images with precise annotations. A virtual dataset named ParallelEye is built, which can be used for several computer vision tasks. Then, by training the DPM (Deformable Parts Model) and Faster R-CNN detectors, we prove that the performance of models can be significantly improved by combining ParallelEye with publicly available real-world datasets during the training phase. In addition, we investigate the potential of testing the trained models from a specific aspect using intentionally designed virtual datasets, in order to discover the flaws of trained models. From the experimental results, we conclude that our virtual dataset is viable to train and test the object detectors.
The ParallelEye Dataset: Constructing Large-Scale Artificial Scenes for Traffic Vision Research
Dec 22, 2017
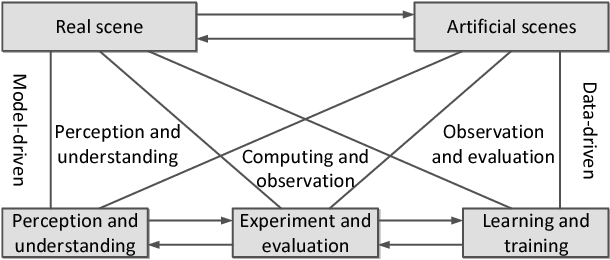


Video image datasets are playing an essential role in design and evaluation of traffic vision algorithms. Nevertheless, a longstanding inconvenience concerning image datasets is that manually collecting and annotating large-scale diversified datasets from real scenes is time-consuming and prone to error. For that virtual datasets have begun to function as a proxy of real datasets. In this paper, we propose to construct large-scale artificial scenes for traffic vision research and generate a new virtual dataset called "ParallelEye". First of all, the street map data is used to build 3D scene model of Zhongguancun Area, Beijing. Then, the computer graphics, virtual reality, and rule modeling technologies are utilized to synthesize large-scale, realistic virtual urban traffic scenes, in which the fidelity and geography match the real world well. Furthermore, the Unity3D platform is used to render the artificial scenes and generate accurate ground-truth labels, e.g., semantic/instance segmentation, object bounding box, object tracking, optical flow, and depth. The environmental conditions in artificial scenes can be controlled completely. As a result, we present a viable implementation pipeline for constructing large-scale artificial scenes for traffic vision research. The experimental results demonstrate that this pipeline is able to generate photorealistic virtual datasets with low modeling time and high accuracy labeling.