 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMS-Occ: Multi-Stage LiDAR-Camera Fusion for 3D Semantic Occupancy Prediction
Apr 22, 2025Accurate 3D semantic occupancy perception is essential for autonomous driving in complex environments with diverse and irregular objects. While vision-centric methods suffer from geometric inaccuracies, LiDAR-based approaches often lack rich semantic information. To address these limitations, MS-Occ, a novel multi-stage LiDAR-camera fusion framework which includes middle-stage fusion and late-stage fusion, is proposed, integrating LiDAR's geometric fidelity with camera-based semantic richness via hierarchical cross-modal fusion. The framework introduces innovations at two critical stages: (1) In the middle-stage feature fusion, the Gaussian-Geo module leverages Gaussian kernel rendering on sparse LiDAR depth maps to enhance 2D image features with dense geometric priors, and the Semantic-Aware module enriches LiDAR voxels with semantic context via deformable cross-attention; (2) In the late-stage voxel fusion, the Adaptive Fusion (AF) module dynamically balances voxel features across modalities, while the High Classification Confidence Voxel Fusion (HCCVF) module resolves semantic inconsistencies using self-attention-based refinement. Experiments on the nuScenes-OpenOccupancy benchmark show that MS-Occ achieves an Intersection over Union (IoU) of 32.1% and a mean IoU (mIoU) of 25.3%, surpassing the state-of-the-art by +0.7% IoU and +2.4% mIoU. Ablation studies further validate the contribution of each module, with substantial improvements in small-object perception, demonstrating the practical value of MS-Occ for safety-critical autonomous driving scenarios.
Accurate Diagnosis of Respiratory Viruses Using an Explainable Machine Learning with Mid-Infrared Biomolecular Fingerprinting of Nasopharyngeal Secretions
Apr 12, 2025Accurate identification of respiratory viruses (RVs) is critical for outbreak control and public health. This study presents a diagnostic system that combines Attenuated Total Reflectance Fourier Transform Infrared Spectroscopy (ATR-FTIR) from nasopharyngeal secretions with an explainable Rotary Position Embedding-Sparse Attention Transformer (RoPE-SAT) model to accurately identify multiple RVs within 10 minutes. Spectral data (4000-00 cm-1) were collected, and the bio-fingerprint region (1800-900 cm-1) was employed for analysis. Standard normal variate (SNV) normalization and second-order derivation were applied to reduce scattering and baseline drift. Gradient-weighted class activation mapping (Grad-CAM) was employed to generate saliency maps, highlighting spectral regions most relevant to classification and enhancing the interpretability of model outputs. Two independent cohorts from Beijing Youan Hospital, processed with different viral transport media (VTMs) and drying methods, were evaluated, with one including influenza B, SARS-CoV-2, and healthy controls, and the other including mycoplasma, SARS-CoV-2, and healthy controls. The model achieved sensitivity and specificity above 94.40% across both cohorts. By correlating model-selected infrared regions with known biomolecular signatures, we verified that the system effectively recognizes virus-specific spectral fingerprints, including lipids, Amide I, Amide II, Amide III, nucleic acids, and carbohydrates, and leverages their weighted contributions for accurate classification.
Graph-Driven Models for Gas Mixture Identification and Concentration Estimation on Heterogeneous Sensor Array Signals
Dec 18, 2024Accurately identifying gas mixtures and estimating their concentrations are crucial across various industrial applications using gas sensor arrays. However, existing models face challenges in generalizing across heterogeneous datasets, which limits their scalability and practical applicability. To address this problem, this study develops two novel deep-learning models that integrate temporal graph structures for enhanced performance: a Graph-Enhanced Capsule Network (GraphCapsNet) employing dynamic routing for gas mixture classification and a Graph-Enhanced Attention Network (GraphANet) leveraging self-attention for concentration estimation. Both models were validated on datasets from the University of California, Irvine (UCI) Machine Learning Repository and a custom dataset, demonstrating superior performance in gas mixture identification and concentration estimation compared to recent models. In classification tasks, GraphCapsNet achieved over 98.00% accuracy across multiple datasets, while in concentration estimation, GraphANet attained an R2 score exceeding 0.96 across various gas components. Both GraphCapsNet and GraphANet exhibited significantly higher accuracy and stability, positioning them as promising solutions for scalable gas analysis in industrial settings.
CT-Mamba: A Hybrid Convolutional State Space Model for Low-Dose CT Denoising
Nov 12, 2024Low-dose CT (LDCT) significantly reduces the radiation dose received by patients, thereby decreasing potential health risks. However, dose reduction introduces additional noise and artifacts, adversely affecting image quality and clinical diagnosis. Currently, denoising methods based on convolutional neural networks (CNNs) face limitations in long-range modeling capabilities, while Transformer-based denoising methods, although capable of powerful long-range modeling, suffer from high computational complexity. Furthermore, the denoised images predicted by deep learning-based techniques inevitably exhibit differences in noise distribution compared to Normal-dose CT (NDCT) images, which can also impact the final image quality and diagnostic outcomes. In recent years, the feasibility of applying deep learning methods to low-dose CT imaging has been demonstrated, leading to significant achievements. This paper proposes CT-Mamba, a hybrid convolutional State Space Model for LDCT image denoising. The model combines the local feature extraction advantages of CNNs with Mamba's global modeling capability, enabling it to capture both local details and global context. Additionally, a Mamba-driven deep noise power spectrum (NPS) loss function was designed to guide model training, ensuring that the noise texture of the denoised LDCT images closely resembles that of NDCT images, thereby enhancing overall image quality and diagnostic value. Experimental results have demonstrated that CT-Mamba performs excellently in reducing noise in LDCT images, enhancing detail preservation, and optimizing noise texture distribution, while demonstrating statistically similar radiomics features to those of NDCT images (p > 0.05). The proposed CT-Mamba demonstrates outstanding performance in LDCT denoising and holds promise as a representative approach for applying the Mamba framework to LDCT denoising tasks.
On-Site Precise Screening of SARS-CoV-2 Systems Using a Channel-Wise Attention-Based PLS-1D-CNN Model with Limited Infrared Signatures
Oct 26, 2024During the early stages of respiratory virus outbreaks, such as severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the efficient utilize of limited nasopharyngeal swabs for rapid and accurate screening is crucial for public health. In this study, we present a methodology that integrates attenuated total reflection-Fourier transform infrared spectroscopy (ATR-FTIR) with the adaptive iteratively reweighted penalized least squares (airPLS) preprocessing algorithm and a channel-wise attention-based partial least squares one-dimensional convolutional neural network (PLS-1D-CNN) model, enabling accurate screening of infected individuals within 10 minutes. Two cohorts of nasopharyngeal swab samples, comprising 126 and 112 samples from suspected SARS-CoV-2 Omicron variant cases, were collected at Beijing You'an Hospital for verification. Given that ATR-FTIR spectra are highly sensitive to variations in experimental conditions, which can affect their quality, we propose a biomolecular importance (BMI) evaluation method to assess signal quality across different conditions, validated by comparing BMI with PLS-GBM and PLS-RF results. For the ATR-FTIR signals in cohort 2, which exhibited a higher BMI, airPLS was utilized for signal preprocessing, followed by the application of the channel-wise attention-based PLS-1D-CNN model for screening. The experimental results demonstrate that our model outperforms recently reported methods in the field of respiratory virus spectrum detection, achieving a recognition screening accuracy of 96.48%, a sensitivity of 96.24%, a specificity of 97.14%, an F1-score of 96.12%, and an AUC of 0.99. It meets the World Health Organization (WHO) recommended criteria for an acceptable product: sensitivity of 95.00% or greater and specificity of 97.00% or greater for testing prior SARS-CoV-2 infection in moderate to high volume scenarios.
GaitMotion: A Multitask Dataset for Pathological Gait Forecasting
May 09, 2024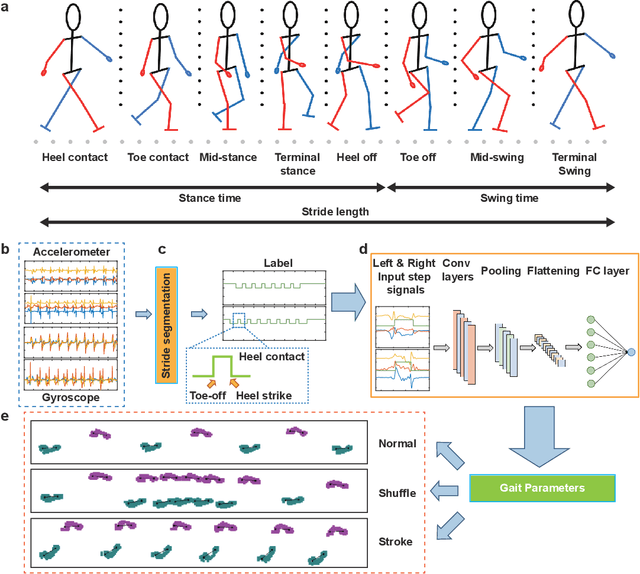

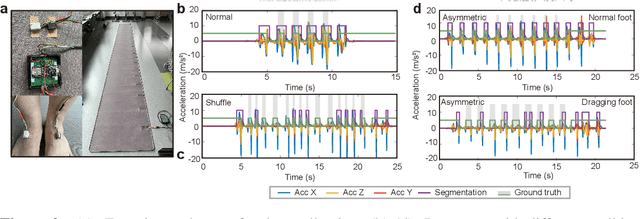

Gait benchmark empowers uncounted encouraging research fields such as gait recognition, humanoid locomotion, etc. Despite the growing focus on gait analysis, the research community is hindered by the limitations of the currently available databases, which mostly consist of videos or images with limited labeling. In this paper, we introduce GaitMotion, a multitask dataset leveraging wearable sensors to capture the patients' real-time movement with pathological gait. This dataset offers extensive ground-truth labeling for multiple tasks, including step/stride segmentation and step/stride length prediction, empowers researchers with a more holistic understanding of gait disturbances linked to neurological impairments. The wearable gait analysis suit captures the gait cycle, pattern, and parameters for both normal and pathological subjects. This data may prove beneficial for healthcare products focused on patient progress monitoring and post-disease recovery, as well as for forensics technologies aimed at person reidentification, and biomechanics research to aid in the development of humanoid robotics. Moreover, the analysis has considered the drift in data distribution across individual subjects. This drift can be attributed to each participant's unique behavioral habits or potential displacement of the sensor. Stride length variance for normal, Parkinson's, and stroke patients are compared to recognize the pathological walking pattern. As the baseline and benchmark, we provide an error of 14.1, 13.3, and 12.2 centimeters of stride length prediction for normal, Parkinson's, and Stroke gaits separately. We also analyzed the gait characteristics for normal and pathological gaits in terms of the gait cycle and gait parameters.
HSD-PAM: High Speed Super Resolution Deep Penetration Photoacoustic Microscopy Imaging Boosted by Dual Branch Fusion Network
Aug 09, 2023Photoacoustic microscopy (PAM) is a novel implementation of photoacoustic imaging (PAI) for visualizing the 3D bio-structure, which is realized by raster scanning of the tissue. However, as three involved critical imaging parameters, imaging speed, lateral resolution, and penetration depth have mutual effect to one the other. The improvement of one parameter results in the degradation of other two parameters, which constrains the overall performance of the PAM system. Here, we propose to break these limitations by hardware and software co-design. Starting with low lateral resolution, low sampling rate AR-PAM imaging which possesses the deep penetration capability, we aim to enhance the lateral resolution and up sampling the images, so that high speed, super resolution, and deep penetration for the PAM system (HSD-PAM) can be achieved. Data-driven based algorithm is a promising approach to solve this issue, thereby a dedicated novel dual branch fusion network is proposed, which includes a high resolution branch and a high speed branch. Since the availability of switchable AR-OR-PAM imaging system, the corresponding low resolution, undersample AR-PAM and high resolution, full sampled OR-PAM image pairs are utilized for training the network. Extensive simulation and in vivo experiments have been conducted to validate the trained model, enhancement results have proved the proposed algorithm achieved the best perceptual and quantitative image quality. As a result, the imaging speed is increased 16 times and the imaging lateral resolution is improved 5 times, while the deep penetration merit of AR-PAM modality is still reserved.
Probing Ring Resonator Sensor Based on Vernier Effect
May 28, 2023The Vernier effect has seen extensive application in optical structures, serving to augment the free spectral range (FSR). A substantial FSR is vital in a myriad of applications including multiplexers, enabling a broad, clear band comparable to the C-band to accommodate a maximum number of channels. Nevertheless, a large FSR often conflicts with bending loss, as it necessitates a smaller resonator radius, thus increase the insertion loss in the bending portion. To facilitate FSR expansion without amplifying bending loss, we employed cascaded and parallel racetrack resonators and ring resonators of varying radius that demonstrate the Vernier effect. In this study, we designed, fabricated, and tested multiple types of racetrack resonators to validate the Vernier effect and its FSR extension capabilities. Our investigations substantiate that the Vernier effect, based on cascaded and series-coupled micro-ring resonator (MRR) sensors, can efficiently mitigate intra-channel cross-talk at higher data rates. This is achieved by providing larger input-to-through suppression, thus paving the way for future applications.
Privacy-preserving Adversarial Facial Features
May 08, 2023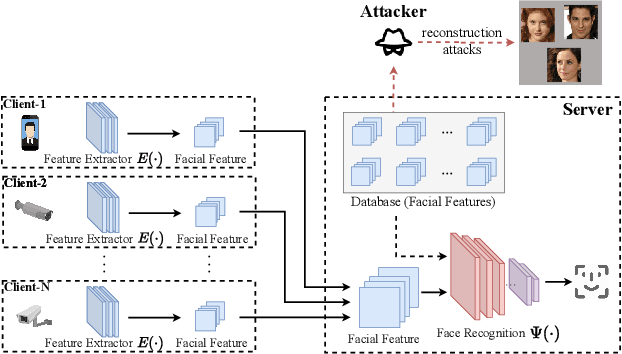

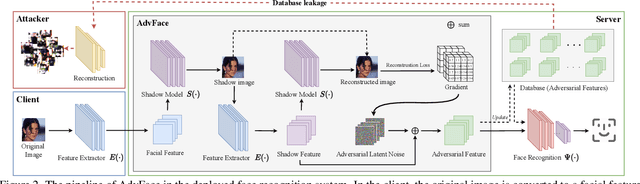

Face recognition service providers protect face privacy by extracting compact and discriminative facial features (representations) from images, and storing the facial features for real-time recognition. However, such features can still be exploited to recover the appearance of the original face by building a reconstruction network. Although several privacy-preserving methods have been proposed, the enhancement of face privacy protection is at the expense of accuracy degradation. In this paper, we propose an adversarial features-based face privacy protection (AdvFace) approach to generate privacy-preserving adversarial features, which can disrupt the mapping from adversarial features to facial images to defend against reconstruction attacks. To this end, we design a shadow model which simulates the attackers' behavior to capture the mapping function from facial features to images and generate adversarial latent noise to disrupt the mapping. The adversarial features rather than the original features are stored in the server's database to prevent leaked features from exposing facial information. Moreover, the AdvFace requires no changes to the face recognition network and can be implemented as a privacy-enhancing plugin in deployed face recognition systems. Extensive experimental results demonstrate that AdvFace outperforms the state-of-the-art face privacy-preserving methods in defending against reconstruction attacks while maintaining face recognition accuracy.
Adaptive Base-class Suppression and Prior Guidance Network for One-Shot Object Detection
Mar 24, 2023



One-shot object detection (OSOD) aims to detect all object instances towards the given category specified by a query image. Most existing studies in OSOD endeavor to explore effective cross-image correlation and alleviate the semantic feature misalignment, however, ignoring the phenomenon of the model bias towards the base classes and the generalization degradation on the novel classes. Observing this, we propose a novel framework, namely Base-class Suppression and Prior Guidance (BSPG) network to overcome the problem. Specifically, the objects of base categories can be explicitly detected by a base-class predictor and adaptively eliminated by our base-class suppression module. Moreover, a prior guidance module is designed to calculate the correlation of high-level features in a non-parametric manner, producing a class-agnostic prior map to provide the target features with rich semantic cues and guide the subsequent detection process. Equipped with the proposed two modules, we endow the model with a strong discriminative ability to distinguish the target objects from distractors belonging to the base classes. Extensive experiments show that our method outperforms the previous techniques by a large margin and achieves new state-of-the-art performance under various evaluation settings.