 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-step Multi-view Clustering With Adaptive Low-rank Anchor-graph Learning
Sep 18, 2025In light of their capability to capture structural information while reducing computing complexity, anchor graph-based multi-view clustering (AGMC) methods have attracted considerable attention in large-scale clustering problems. Nevertheless, existing AGMC methods still face the following two issues: 1) They directly embedded diverse anchor graphs into a consensus anchor graph (CAG), and hence ignore redundant information and numerous noises contained in these anchor graphs, leading to a decrease in clustering effectiveness; 2) They drop effectiveness and efficiency due to independent post-processing to acquire clustering indicators. To overcome the aforementioned issues, we deliver a novel one-step multi-view clustering method with adaptive low-rank anchor-graph learning (OMCAL). To construct a high-quality CAG, OMCAL provides a nuclear norm-based adaptive CAG learning model against information redundancy and noise interference. Then, to boost clustering effectiveness and efficiency substantially, we incorporate category indicator acquisition and CAG learning into a unified framework. Numerous studies conducted on ordinary and large-scale datasets indicate that OMCAL outperforms existing state-of-the-art methods in terms of clustering effectiveness and efficiency.
Accurate Diagnosis of Respiratory Viruses Using an Explainable Machine Learning with Mid-Infrared Biomolecular Fingerprinting of Nasopharyngeal Secretions
Apr 12, 2025Accurate identification of respiratory viruses (RVs) is critical for outbreak control and public health. This study presents a diagnostic system that combines Attenuated Total Reflectance Fourier Transform Infrared Spectroscopy (ATR-FTIR) from nasopharyngeal secretions with an explainable Rotary Position Embedding-Sparse Attention Transformer (RoPE-SAT) model to accurately identify multiple RVs within 10 minutes. Spectral data (4000-00 cm-1) were collected, and the bio-fingerprint region (1800-900 cm-1) was employed for analysis. Standard normal variate (SNV) normalization and second-order derivation were applied to reduce scattering and baseline drift. Gradient-weighted class activation mapping (Grad-CAM) was employed to generate saliency maps, highlighting spectral regions most relevant to classification and enhancing the interpretability of model outputs. Two independent cohorts from Beijing Youan Hospital, processed with different viral transport media (VTMs) and drying methods, were evaluated, with one including influenza B, SARS-CoV-2, and healthy controls, and the other including mycoplasma, SARS-CoV-2, and healthy controls. The model achieved sensitivity and specificity above 94.40% across both cohorts. By correlating model-selected infrared regions with known biomolecular signatures, we verified that the system effectively recognizes virus-specific spectral fingerprints, including lipids, Amide I, Amide II, Amide III, nucleic acids, and carbohydrates, and leverages their weighted contributions for accurate classification.
Graph-Driven Models for Gas Mixture Identification and Concentration Estimation on Heterogeneous Sensor Array Signals
Dec 18, 2024Accurately identifying gas mixtures and estimating their concentrations are crucial across various industrial applications using gas sensor arrays. However, existing models face challenges in generalizing across heterogeneous datasets, which limits their scalability and practical applicability. To address this problem, this study develops two novel deep-learning models that integrate temporal graph structures for enhanced performance: a Graph-Enhanced Capsule Network (GraphCapsNet) employing dynamic routing for gas mixture classification and a Graph-Enhanced Attention Network (GraphANet) leveraging self-attention for concentration estimation. Both models were validated on datasets from the University of California, Irvine (UCI) Machine Learning Repository and a custom dataset, demonstrating superior performance in gas mixture identification and concentration estimation compared to recent models. In classification tasks, GraphCapsNet achieved over 98.00% accuracy across multiple datasets, while in concentration estimation, GraphANet attained an R2 score exceeding 0.96 across various gas components. Both GraphCapsNet and GraphANet exhibited significantly higher accuracy and stability, positioning them as promising solutions for scalable gas analysis in industrial settings.
Analytic Continual Test-Time Adaptation for Multi-Modality Corruption
Oct 29, 2024Test-Time Adaptation (TTA) aims to help pre-trained model bridge the gap between source and target datasets using only the pre-trained model and unlabelled test data. A key objective of TTA is to address domain shifts in test data caused by corruption, such as weather changes, noise, or sensor malfunctions. Multi-Modal Continual Test-Time Adaptation (MM-CTTA), an extension of TTA with better real-world applications, further allows pre-trained models to handle multi-modal inputs and adapt to continuously-changing target domains. MM-CTTA typically faces challenges including error accumulation, catastrophic forgetting, and reliability bias, with few existing approaches effectively addressing these issues in multi-modal corruption scenarios. In this paper, we propose a novel approach, Multi-modality Dynamic Analytic Adapter (MDAA), for MM-CTTA tasks. We innovatively introduce analytic learning into TTA, using the Analytic Classifiers (ACs) to prevent model forgetting. Additionally, we develop Dynamic Selection Mechanism (DSM) and Soft Pseudo-label Strategy (SPS), which enable MDAA to dynamically filter reliable samples and integrate information from different modalities. Extensive experiments demonstrate that MDAA achieves state-of-the-art performance on MM-CTTA tasks while ensuring reliable model adaptation.
On-Site Precise Screening of SARS-CoV-2 Systems Using a Channel-Wise Attention-Based PLS-1D-CNN Model with Limited Infrared Signatures
Oct 26, 2024



During the early stages of respiratory virus outbreaks, such as severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the efficient utilize of limited nasopharyngeal swabs for rapid and accurate screening is crucial for public health. In this study, we present a methodology that integrates attenuated total reflection-Fourier transform infrared spectroscopy (ATR-FTIR) with the adaptive iteratively reweighted penalized least squares (airPLS) preprocessing algorithm and a channel-wise attention-based partial least squares one-dimensional convolutional neural network (PLS-1D-CNN) model, enabling accurate screening of infected individuals within 10 minutes. Two cohorts of nasopharyngeal swab samples, comprising 126 and 112 samples from suspected SARS-CoV-2 Omicron variant cases, were collected at Beijing You'an Hospital for verification. Given that ATR-FTIR spectra are highly sensitive to variations in experimental conditions, which can affect their quality, we propose a biomolecular importance (BMI) evaluation method to assess signal quality across different conditions, validated by comparing BMI with PLS-GBM and PLS-RF results. For the ATR-FTIR signals in cohort 2, which exhibited a higher BMI, airPLS was utilized for signal preprocessing, followed by the application of the channel-wise attention-based PLS-1D-CNN model for screening. The experimental results demonstrate that our model outperforms recently reported methods in the field of respiratory virus spectrum detection, achieving a recognition screening accuracy of 96.48%, a sensitivity of 96.24%, a specificity of 97.14%, an F1-score of 96.12%, and an AUC of 0.99. It meets the World Health Organization (WHO) recommended criteria for an acceptable product: sensitivity of 95.00% or greater and specificity of 97.00% or greater for testing prior SARS-CoV-2 infection in moderate to high volume scenarios.
FACT: Feature Adaptive Continual-learning Tracker for Multiple Object Tracking
Sep 12, 2024



Multiple object tracking (MOT) involves identifying multiple targets and assigning them corresponding IDs within a video sequence, where occlusions are often encountered. Recent methods address occlusions using appearance cues through online learning techniques to improve adaptivity or offline learning techniques to utilize temporal information from videos. However, most existing online learning-based MOT methods are unable to learn from all past tracking information to improve adaptivity on long-term occlusions while maintaining real-time tracking speed. On the other hand, temporal information-based offline learning methods maintain a long-term memory to store past tracking information, but this approach restricts them to use only local past information during tracking. To address these challenges, we propose a new MOT framework called the Feature Adaptive Continual-learning Tracker (FACT), which enables real-time tracking and feature learning for targets by utilizing all past tracking information. We demonstrate that the framework can be integrated with various state-of-the-art feature-based trackers, thereby improving their tracking ability. Specifically, we develop the feature adaptive continual-learning (FAC) module, a neural network that can be trained online to learn features adaptively using all past tracking information during tracking. Moreover, we also introduce a two-stage association module specifically designed for the proposed continual learning-based tracking. Extensive experiment results demonstrate that the proposed method achieves state-of-the-art online tracking performance on MOT17 and MOT20 benchmarks. The code will be released upon acceptance.
Box-Free Model Watermarks Are Prone to Black-Box Removal Attacks
May 16, 2024


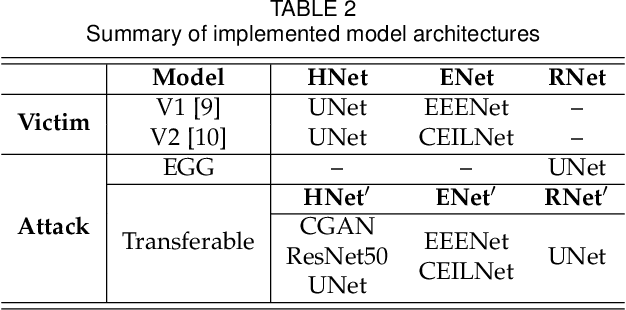
Box-free model watermarking is an emerging technique to safeguard the intellectual property of deep learning models, particularly those for low-level image processing tasks. Existing works have verified and improved its effectiveness in several aspects. However, in this paper, we reveal that box-free model watermarking is prone to removal attacks, even under the real-world threat model such that the protected model and the watermark extractor are in black boxes. Under this setting, we carry out three studies. 1) We develop an extractor-gradient-guided (EGG) remover and show its effectiveness when the extractor uses ReLU activation only. 2) More generally, for an unknown extractor, we leverage adversarial attacks and design the EGG remover based on the estimated gradients. 3) Under the most stringent condition that the extractor is inaccessible, we design a transferable remover based on a set of private proxy models. In all cases, the proposed removers can successfully remove embedded watermarks while preserving the quality of the processed images, and we also demonstrate that the EGG remover can even replace the watermarks. Extensive experimental results verify the effectiveness and generalizability of the proposed attacks, revealing the vulnerabilities of the existing box-free methods and calling for further research.
DS-AL: A Dual-Stream Analytic Learning for Exemplar-Free Class-Incremental Learning
Mar 26, 2024



Class-incremental learning (CIL) under an exemplar-free constraint has presented a significant challenge. Existing methods adhering to this constraint are prone to catastrophic forgetting, far more so than replay-based techniques that retain access to past samples. In this paper, to solve the exemplar-free CIL problem, we propose a Dual-Stream Analytic Learning (DS-AL) approach. The DS-AL contains a main stream offering an analytical (i.e., closed-form) linear solution, and a compensation stream improving the inherent under-fitting limitation due to adopting linear mapping. The main stream redefines the CIL problem into a Concatenated Recursive Least Squares (C-RLS) task, allowing an equivalence between the CIL and its joint-learning counterpart. The compensation stream is governed by a Dual-Activation Compensation (DAC) module. This module re-activates the embedding with a different activation function from the main stream one, and seeks fitting compensation by projecting the embedding to the null space of the main stream's linear mapping. Empirical results demonstrate that the DS-AL, despite being an exemplar-free technique, delivers performance comparable with or better than that of replay-based methods across various datasets, including CIFAR-100, ImageNet-100 and ImageNet-Full. Additionally, the C-RLS' equivalent property allows the DS-AL to execute CIL in a phase-invariant manner. This is evidenced by a never-before-seen 500-phase CIL ImageNet task, which performs on a level identical to a 5-phase one. Our codes are available at https://github.com/ZHUANGHP/Analytic-continual-learning.
ACIL: Analytic Class-Incremental Learning with Absolute Memorization and Privacy Protection
May 30, 2022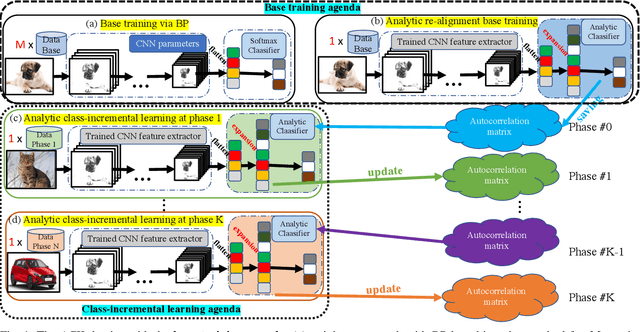
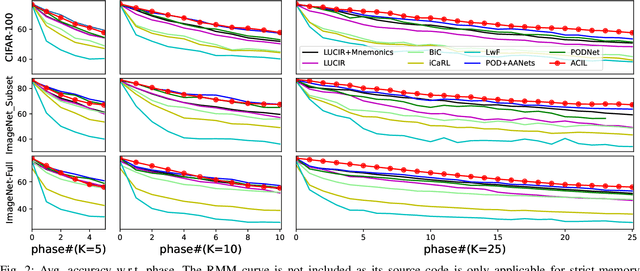
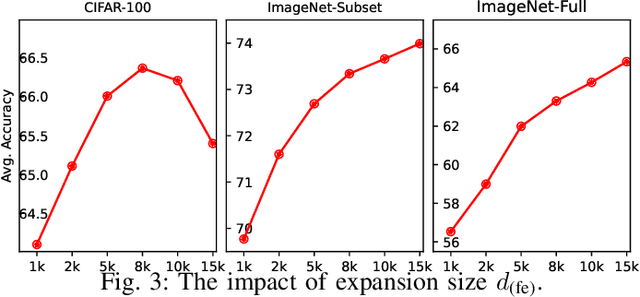
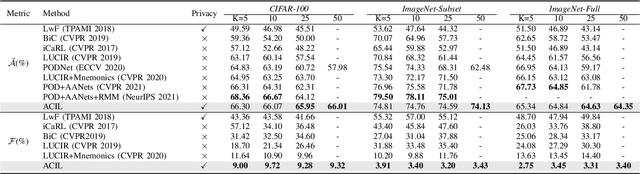
Class-incremental learning (CIL) learns a classification model with training data of different classes arising progressively. Existing CIL either suffers from serious accuracy loss due to catastrophic forgetting, or invades data privacy by revisiting used exemplars. Inspired by linear learning formulations, we propose an analytic class-incremental learning (ACIL) with absolute memorization of past knowledge while avoiding breaching of data privacy (i.e., without storing historical data). The absolute memorization is demonstrated in the sense that class-incremental learning using ACIL given present data would give identical results to that from its joint-learning counterpart which consumes both present and historical samples. This equality is theoretically validated. Data privacy is ensured since no historical data are involved during the learning process. Empirical validations demonstrate ACIL's competitive accuracy performance with near-identical results for various incremental task settings (e.g., 5-50 phases). This also allows ACIL to outperform the state-of-the-art methods for large-phase scenarios (e.g., 25 and 50 phases).
Deterministic Bridge Regression for Compressive Classification
Mar 18, 2022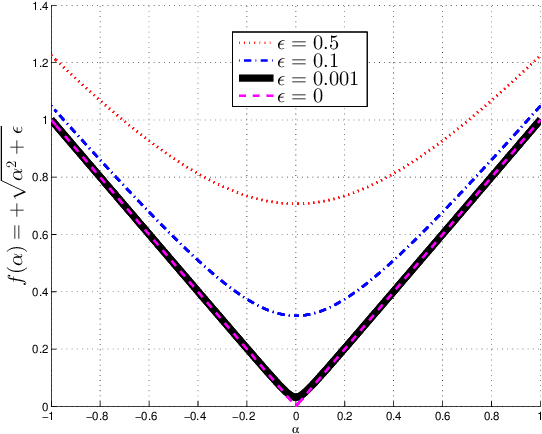

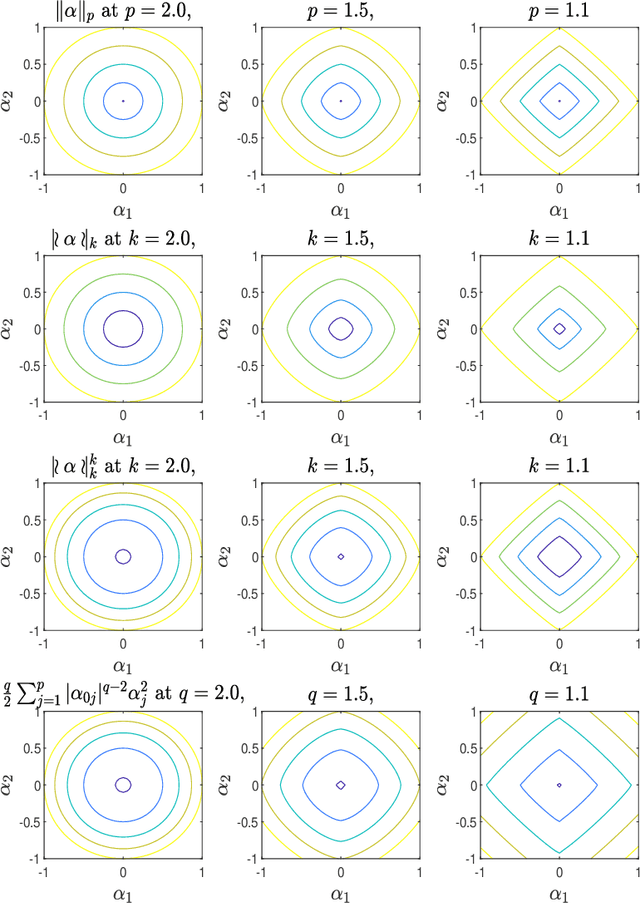
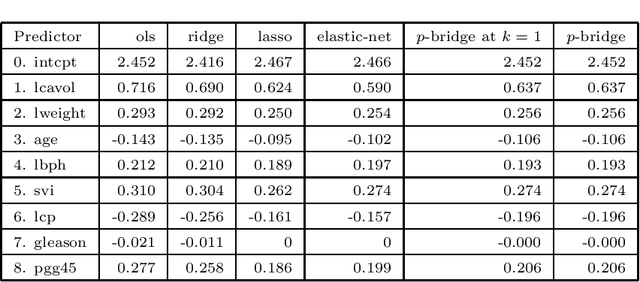
Pattern classification with compact representation is an important component in machine intelligence. In this work, an analytic bridge solution is proposed for compressive classification. The proposal has been based upon solving a penalized error formulation utilizing an approximated $\ell_p$-norm. The solution comes in a primal form for over-determined systems and in a dual form for under-determined systems. While the primal form is suitable for problems of low dimension with large data samples, the dual form is suitable for problems of high dimension but with a small number of data samples. The solution has also been extended for problems with multiple classification outputs. Numerical studies based on simulated and real-world data validated the effectiveness of the proposed solution.