 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE.M.Ground: A Temporal Grounding Vid-LLM with Holistic Event Perception and Matching
Feb 05, 2026Despite recent advances in Video Large Language Models (Vid-LLMs), Temporal Video Grounding (TVG), which aims to precisely localize time segments corresponding to query events, remains a significant challenge. Existing methods often match start and end frames by comparing frame features with two separate tokens, relying heavily on exact timestamps. However, this approach fails to capture the event's semantic continuity and integrity, leading to ambiguities. To address this, we propose E.M.Ground, a novel Vid-LLM for TVG that focuses on holistic and coherent event perception. E.M.Ground introduces three key innovations: (i) a special <event> token that aggregates information from all frames of a query event, preserving semantic continuity for accurate event matching; (ii) Savitzky-Golay smoothing to reduce noise in token-to-frame similarities across timestamps, improving prediction accuracy; (iii) multi-grained frame feature aggregation to enhance matching reliability and temporal understanding, compensating for compression-induced information loss. Extensive experiments on benchmark datasets show that E.M.Ground consistently outperforms state-of-the-art Vid-LLMs by significant margins.
MMPG: MoE-based Adaptive Multi-Perspective Graph Fusion for Protein Representation Learning
Jan 15, 2026Graph Neural Networks (GNNs) have been widely adopted for Protein Representation Learning (PRL), as residue interaction networks can be naturally represented as graphs. Current GNN-based PRL methods typically rely on single-perspective graph construction strategies, which capture partial properties of residue interactions, resulting in incomplete protein representations. To address this limitation, we propose MMPG, a framework that constructs protein graphs from multiple perspectives and adaptively fuses them via Mixture of Experts (MoE) for PRL. MMPG constructs graphs from physical, chemical, and geometric perspectives to characterize different properties of residue interactions. To capture both perspective-specific features and their synergies, we develop an MoE module, which dynamically routes perspectives to specialized experts, where experts learn intrinsic features and cross-perspective interactions. We quantitatively verify that MoE automatically specializes experts in modeling distinct levels of interaction from individual representations, to pairwise inter-perspective synergies, and ultimately to a global consensus across all perspectives. Through integrating this multi-level information, MMPG produces superior protein representations and achieves advanced performance on four different downstream protein tasks.
Semantic Shift Estimation via Dual-Projection and Classifier Reconstruction for Exemplar-Free Class-Incremental Learning
Mar 07, 2025


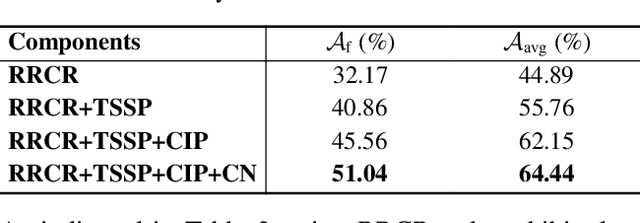
Exemplar-Free Class-Incremental Learning (EFCIL) aims to sequentially learn from distinct categories without retaining exemplars but easily suffers from catastrophic forgetting of learned knowledge. While existing EFCIL methods leverage knowledge distillation to alleviate forgetting, they still face two critical challenges: semantic shift and decision bias. Specifically, the embeddings of old tasks shift in the embedding space after learning new tasks, and the classifier becomes biased towards new tasks due to training solely with new data, thereby hindering the balance between old and new knowledge. To address these issues, we propose the Dual-Projection Shift Estimation and Classifier Reconstruction (DPCR) approach for EFCIL. DPCR effectively estimates semantic shift through a dual-projection, which combines a learnable transformation with a row-space projection to capture both task-wise and category-wise shifts. Furthermore, to mitigate decision bias, DPCR employs ridge regression to reformulate classifier training as a reconstruction process. This reconstruction exploits previous information encoded in covariance and prototype of each class after calibration with estimated shift, thereby reducing decision bias. Extensive experiments demonstrate that, across various datasets, DPCR effectively balances old and new tasks, outperforming state-of-the-art EFCIL methods.
Analytic Continual Test-Time Adaptation for Multi-Modality Corruption
Oct 29, 2024Test-Time Adaptation (TTA) aims to help pre-trained model bridge the gap between source and target datasets using only the pre-trained model and unlabelled test data. A key objective of TTA is to address domain shifts in test data caused by corruption, such as weather changes, noise, or sensor malfunctions. Multi-Modal Continual Test-Time Adaptation (MM-CTTA), an extension of TTA with better real-world applications, further allows pre-trained models to handle multi-modal inputs and adapt to continuously-changing target domains. MM-CTTA typically faces challenges including error accumulation, catastrophic forgetting, and reliability bias, with few existing approaches effectively addressing these issues in multi-modal corruption scenarios. In this paper, we propose a novel approach, Multi-modality Dynamic Analytic Adapter (MDAA), for MM-CTTA tasks. We innovatively introduce analytic learning into TTA, using the Analytic Classifiers (ACs) to prevent model forgetting. Additionally, we develop Dynamic Selection Mechanism (DSM) and Soft Pseudo-label Strategy (SPS), which enable MDAA to dynamically filter reliable samples and integrate information from different modalities. Extensive experiments demonstrate that MDAA achieves state-of-the-art performance on MM-CTTA tasks while ensuring reliable model adaptation.
Preamble Design for Joint Frame Synchronization, Frequency Offset Estimation, and Channel Estimation in Upstream Burst-mode Detection of Coherent PONs
Sep 22, 2024Coherent optics has demonstrated significant potential as a viable solution for achieving 100 Gb/s and higher speeds in single-wavelength passive optical networks (PON). However, upstream burst-mode coherent detection is a major challenge when adopting coherent optics in access networks. To accelerate digital signal processing (DSP) convergence with a minimal preamble length, we propose a novel burst-mode preamble design based on a constant amplitude zero auto-correlation sequence. This design facilitates comprehensive estimation of linear channel effects in the frequency domain, including polarization state rotation, differential group delay, chromatic dispersion, and polarization-dependent loss, providing overall system response information for channel equalization pre-convergence. Additionally, this preamble utilizes the same training unit to jointly achieve three key DSP functions: frame synchronization, frequency offset estimation, and channel estimation. This integration contributes to a significant reduction in the preamble length. The feasibility of the proposed preamble with a length of 272 symbols and corresponding DSP was experimentally verified in a 15 Gbaud coherent system using dual-polarization 16 quadrature amplitude modulation. The experimental results based on this scheme showed a superior performance of the convergence acceleration.
Advancing Cross-domain Discriminability in Continual Learning of Vison-Language Models
Jun 27, 2024



Continual learning (CL) with Vision-Language Models (VLMs) has overcome the constraints of traditional CL, which only focuses on previously encountered classes. During the CL of VLMs, we need not only to prevent the catastrophic forgetting on incrementally learned knowledge but also to preserve the zero-shot ability of VLMs. However, existing methods require additional reference datasets to maintain such zero-shot ability and rely on domain-identity hints to classify images across different domains. In this study, we propose Regression-based Analytic Incremental Learning (RAIL), which utilizes a recursive ridge regression-based adapter to learn from a sequence of domains in a non-forgetting manner and decouple the cross-domain correlations by projecting features to a higher-dimensional space. Cooperating with a training-free fusion module, RAIL absolutely preserves the VLM's zero-shot ability on unseen domains without any reference data. Additionally, we introduce Cross-domain Task-Agnostic Incremental Learning (X-TAIL) setting. In this setting, a CL learner is required to incrementally learn from multiple domains and classify test images from both seen and unseen domains without any domain-identity hint. We theoretically prove RAIL's absolute memorization on incrementally learned domains. Experiment results affirm RAIL's state-of-the-art performance in both X-TAIL and existing Multi-domain Task-Incremental Learning settings. The code will be released upon acceptance.
Multicarrier Modulation-Based Digital Radio-over-Fibre System Achieving Unequal Bit Protection with Over 10 dB SNR Gain
Jul 04, 2023


We propose a multicarrier modulation-based digital radio-over-fibre system achieving unequal bit protection by bit and power allocation for subcarriers. A theoretical SNR gain of 16.1 dB is obtained in the AWGN channel and the simulation results show a 13.5 dB gain in the bandwidth-limited case.
TACR: A Table-alignment-based Cell-selection and Reasoning Model for Hybrid Question-Answering
May 24, 2023Hybrid Question-Answering (HQA), which targets reasoning over tables and passages linked from table cells, has witnessed significant research in recent years. A common challenge in HQA and other passage-table QA datasets is that it is generally unrealistic to iterate over all table rows, columns, and linked passages to retrieve evidence. Such a challenge made it difficult for previous studies to show their reasoning ability in retrieving answers. To bridge this gap, we propose a novel Table-alignment-based Cell-selection and Reasoning model (TACR) for hybrid text and table QA, evaluated on the HybridQA and WikiTableQuestions datasets. In evidence retrieval, we design a table-question-alignment enhanced cell-selection method to retrieve fine-grained evidence. In answer reasoning, we incorporate a QA module that treats the row containing selected cells as context. Experimental results over the HybridQA and WikiTableQuestions (WTQ) datasets show that TACR achieves state-of-the-art results on cell selection and outperforms fine-grained evidence retrieval baselines on HybridQA, while achieving competitive performance on WTQ. We also conducted a detailed analysis to demonstrate that being able to align questions to tables in the cell-selection stage can result in important gains from experiments of over 90\% table row and column selection accuracy, meanwhile also improving output explainability.
Too Much Information Kills Information: A Clustering Perspective
Sep 16, 2020
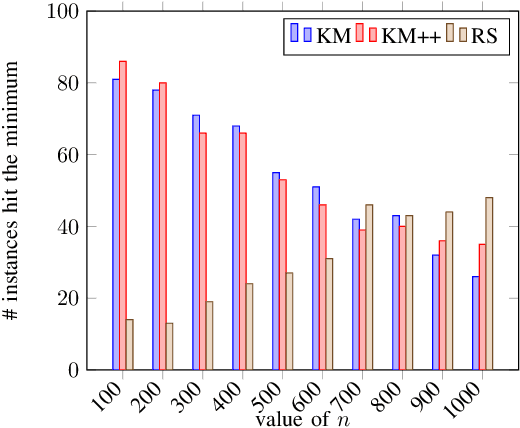
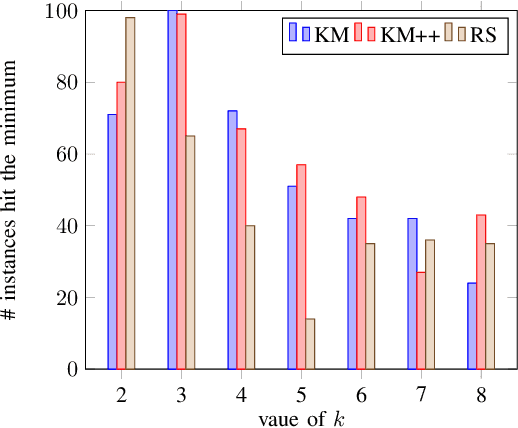
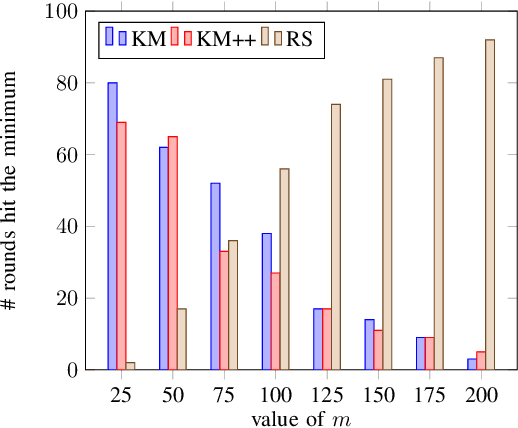
Clustering is one of the most fundamental tools in the artificial intelligence area, particularly in the pattern recognition and learning theory. In this paper, we propose a simple, but novel approach for variance-based k-clustering tasks, included in which is the widely known k-means clustering. The proposed approach picks a sampling subset from the given dataset and makes decisions based on the data information in the subset only. With certain assumptions, the resulting clustering is provably good to estimate the optimum of the variance-based objective with high probability. Extensive experiments on synthetic datasets and real-world datasets show that to obtain competitive results compared with k-means method (Llyod 1982) and k-means++ method (Arthur and Vassilvitskii 2007), we only need 7% information of the dataset. If we have up to 15% information of the dataset, then our algorithm outperforms both the k-means method and k-means++ method in at least 80% of the clustering tasks, in terms of the quality of clustering. Also, an extended algorithm based on the same idea guarantees a balanced k-clustering result.