 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
May 18, 2025The development of artificial intelligence demands that models incrementally update knowledge by Continual Learning (CL) to adapt to open-world environments. To meet privacy and security requirements, Continual Unlearning (CU) emerges as an important problem, aiming to sequentially forget particular knowledge acquired during the CL phase. However, existing unlearning methods primarily focus on single-shot joint forgetting and face significant limitations when applied to CU. First, most existing methods require access to the retained dataset for re-training or fine-tuning, violating the inherent constraint in CL that historical data cannot be revisited. Second, these methods often suffer from a poor trade-off between system efficiency and model fidelity, making them vulnerable to being overwhelmed or degraded by adversaries through deliberately frequent requests. In this paper, we identify that the limitations of existing unlearning methods stem fundamentally from their reliance on gradient-based updates. To bridge the research gap at its root, we propose a novel gradient-free method for CU, named Analytic Continual Unlearning (ACU), for efficient and exact forgetting with historical data privacy preservation. In response to each unlearning request, our ACU recursively derives an analytical (i.e., closed-form) solution in an interpretable manner using the least squares method. Theoretical and experimental evaluations validate the superiority of our ACU on unlearning effectiveness, model fidelity, and system efficiency.
Semantic Shift Estimation via Dual-Projection and Classifier Reconstruction for Exemplar-Free Class-Incremental Learning
Mar 07, 2025


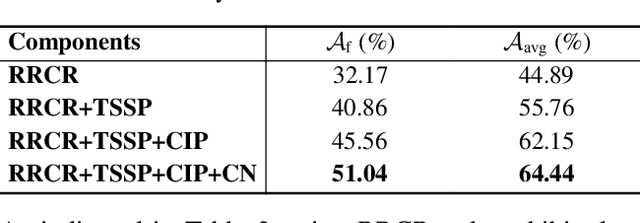
Exemplar-Free Class-Incremental Learning (EFCIL) aims to sequentially learn from distinct categories without retaining exemplars but easily suffers from catastrophic forgetting of learned knowledge. While existing EFCIL methods leverage knowledge distillation to alleviate forgetting, they still face two critical challenges: semantic shift and decision bias. Specifically, the embeddings of old tasks shift in the embedding space after learning new tasks, and the classifier becomes biased towards new tasks due to training solely with new data, thereby hindering the balance between old and new knowledge. To address these issues, we propose the Dual-Projection Shift Estimation and Classifier Reconstruction (DPCR) approach for EFCIL. DPCR effectively estimates semantic shift through a dual-projection, which combines a learnable transformation with a row-space projection to capture both task-wise and category-wise shifts. Furthermore, to mitigate decision bias, DPCR employs ridge regression to reformulate classifier training as a reconstruction process. This reconstruction exploits previous information encoded in covariance and prototype of each class after calibration with estimated shift, thereby reducing decision bias. Extensive experiments demonstrate that, across various datasets, DPCR effectively balances old and new tasks, outperforming state-of-the-art EFCIL methods.
SegACIL: Solving the Stability-Plasticity Dilemma in Class-Incremental Semantic Segmentation
Dec 14, 2024While deep learning has made remarkable progress in recent years, models continue to struggle with catastrophic forgetting when processing continuously incoming data. This issue is particularly critical in continual learning, where the balance between retaining prior knowledge and adapting to new information-known as the stability-plasticity dilemma-remains a significant challenge. In this paper, we propose SegACIL, a novel continual learning method for semantic segmentation based on a linear closed-form solution. Unlike traditional methods that require multiple epochs for training, SegACIL only requires a single epoch, significantly reducing computational costs. Furthermore, we provide a theoretical analysis demonstrating that SegACIL achieves performance on par with joint learning, effectively retaining knowledge from previous data which makes it to keep both stability and plasticity at the same time. Extensive experiments on the Pascal VOC2012 dataset show that SegACIL achieves superior performance in the sequential, disjoint, and overlap settings, offering a robust solution to the challenges of class-incremental semantic segmentation. Code is available at https://github.com/qwrawq/SegACIL.
AIR: Analytic Imbalance Rectifier for Continual Learning
Aug 19, 2024Continual learning enables AI models to learn new data sequentially without retraining in real-world scenarios. Most existing methods assume the training data are balanced, aiming to reduce the catastrophic forgetting problem that models tend to forget previously generated data. However, data imbalance and the mixture of new and old data in real-world scenarios lead the model to ignore categories with fewer training samples. To solve this problem, we propose an analytic imbalance rectifier algorithm (AIR), a novel online exemplar-free continual learning method with an analytic (i.e., closed-form) solution for data-imbalanced class-incremental learning (CIL) and generalized CIL scenarios in real-world continual learning. AIR introduces an analytic re-weighting module (ARM) that calculates a re-weighting factor for each class for the loss function to balance the contribution of each category to the overall loss and solve the problem of imbalanced training data. AIR uses the least squares technique to give a non-discriminatory optimal classifier and its iterative update method in continual learning. Experimental results on multiple datasets show that AIR significantly outperforms existing methods in long-tailed and generalized CIL scenarios. The source code is available at https://github.com/fang-d/AIR.
Online Analytic Exemplar-Free Continual Learning with Large Models for Imbalanced Autonomous Driving Task
May 28, 2024



In the field of autonomous driving, even a meticulously trained model can encounter failures when faced with unfamiliar sceanrios. One of these scenarios can be formulated as an online continual learning (OCL) problem. That is, data come in an online fashion, and models are updated according to these streaming data. Two major OCL challenges are catastrophic forgetting and data imbalance. To address these challenges, in this paper, we propose an Analytic Exemplar-Free Online Continual Learning (AEF-OCL). The AEF-OCL leverages analytic continual learning principles and employs ridge regression as a classifier for features extracted by a large backbone network. It solves the OCL problem by recursively calculating the analytical solution, ensuring an equalization between the continual learning and its joint-learning counterpart, and works without the need to save any used samples (i.e., exemplar-free). Additionally, we introduce a Pseudo-Features Generator (PFG) module that recursively estimates the deviation of real features. The PFG generates offset pseudo-features following a normal distribution, thereby addressing the data imbalance issue. Experimental results demonstrate that despite being an exemplar-free strategy, our method outperforms various methods on the autonomous driving SODA10M dataset. Source code is available at https://github.com/ZHUANGHP/Analytic-continual-learning.
Analytic Federated Learning
May 25, 2024
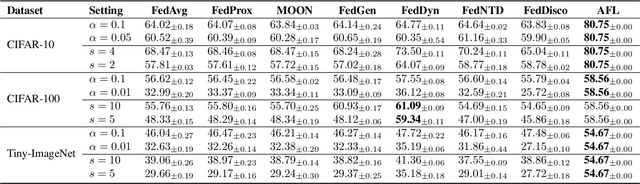


In this paper, we introduce analytic federated learning (AFL), a new training paradigm that brings analytical (i.e., closed-form) solutions to the federated learning (FL) community. Our AFL draws inspiration from analytic learning -- a gradient-free technique that trains neural networks with analytical solutions in one epoch. In the local client training stage, the AFL facilitates a one-epoch training, eliminating the necessity for multi-epoch updates. In the aggregation stage, we derive an absolute aggregation (AA) law. This AA law allows a single-round aggregation, removing the need for multiple aggregation rounds. More importantly, the AFL exhibits a \textit{weight-invariant} property, meaning that regardless of how the full dataset is distributed among clients, the aggregated result remains identical. This could spawn various potentials, such as data heterogeneity invariance, client-number invariance, absolute convergence, and being hyperparameter-free (our AFL is the first hyperparameter-free method in FL history). We conduct experiments across various FL settings including extremely non-IID ones, and scenarios with a large number of clients (e.g., $\ge 1000$). In all these settings, our AFL constantly performs competitively while existing FL techniques encounter various obstacles. Code is available at \url{https://github.com/ZHUANGHP/Analytic-federated-learning}
G-ACIL: Analytic Learning for Exemplar-Free Generalized Class Incremental Learning
Mar 23, 2024



Class incremental learning (CIL) trains a network on sequential tasks with separated categories but suffers from catastrophic forgetting, where models quickly lose previously learned knowledge when acquiring new tasks. The generalized CIL (GCIL) aims to address the CIL problem in a more real-world scenario, where incoming data have mixed data categories and unknown sample size distribution, leading to intensified forgetting. Existing attempts for the GCIL either have poor performance, or invade data privacy by saving historical exemplars. To address this, in this paper, we propose an exemplar-free generalized analytic class incremental learning (G-ACIL). The G-ACIL adopts analytic learning (a gradient-free training technique), and delivers an analytical solution (i.e., closed-form) to the GCIL scenario. This solution is derived via decomposing the incoming data into exposed and unexposed classes, allowing an equivalence between the incremental learning and its joint training, i.e., the weight-invariant property. Such an equivalence is theoretically validated through matrix analysis tools, and hence contributes interpretability in GCIL. It is also empirically evidenced by experiments on various datasets and settings of GCIL. The results show that the G-ACIL exhibits leading performance with high robustness compared with existing competitive GCIL methods. Codes will be ready at https://github.com/ZHUANGHP/Analytic-continual-learning.
REAL: Representation Enhanced Analytic Learning for Exemplar-free Class-incremental Learning
Mar 20, 2024



Exemplar-free class-incremental learning (EFCIL) aims to mitigate catastrophic forgetting in class-incremental learning without available historical data. Compared with its counterpart (replay-based CIL) that stores historical samples, the EFCIL suffers more from forgetting issues under the exemplar-free constraint. In this paper, inspired by the recently developed analytic learning (AL) based CIL, we propose a representation enhanced analytic learning (REAL) for EFCIL. The REAL constructs a dual-stream base pretraining (DS-BPT) and a representation enhancing distillation (RED) process to enhance the representation of the extractor. The DS-BPT pretrains model in streams of both supervised learning and self-supervised contrastive learning (SSCL) for base knowledge extraction. The RED process distills the supervised knowledge to the SSCL pretrained backbone and facilitates a subsequent AL-basd CIL that converts the CIL to a recursive least-square problem. Our method addresses the issue of insufficient discriminability in representations of unseen data caused by a frozen backbone in the existing AL-based CIL. Empirical results on various datasets including CIFAR-100, ImageNet-100 and ImageNet-1k, demonstrate that our REAL outperforms the state-of-the-arts in EFCIL, and achieves comparable or even more superior performance compared with the replay-based methods.
Learning many-body Hamiltonians with Heisenberg-limited scaling
Oct 06, 2022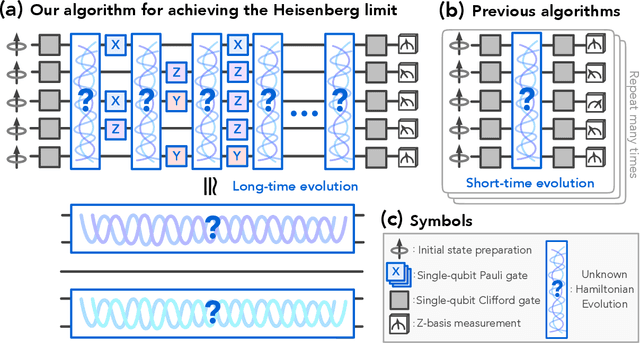
Learning a many-body Hamiltonian from its dynamics is a fundamental problem in physics. In this work, we propose the first algorithm to achieve the Heisenberg limit for learning an interacting $N$-qubit local Hamiltonian. After a total evolution time of $\mathcal{O}(\epsilon^{-1})$, the proposed algorithm can efficiently estimate any parameter in the $N$-qubit Hamiltonian to $\epsilon$-error with high probability. The proposed algorithm is robust against state preparation and measurement error, does not require eigenstates or thermal states, and only uses $\mathrm{polylog}(\epsilon^{-1})$ experiments. In contrast, the best previous algorithms, such as recent works using gradient-based optimization or polynomial interpolation, require a total evolution time of $\mathcal{O}(\epsilon^{-2})$ and $\mathcal{O}(\epsilon^{-2})$ experiments. Our algorithm uses ideas from quantum simulation to decouple the unknown $N$-qubit Hamiltonian $H$ into noninteracting patches, and learns $H$ using a quantum-enhanced divide-and-conquer approach. We prove a matching lower bound to establish the asymptotic optimality of our algorithm.