 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKD-CVG: A Knowledge-Driven Approach for Creative Video Generation
Apr 23, 2026Creative Generation (CG) leverages generative models to automatically produce advertising content that highlights product features, and it has been a significant focus of recent research. However, while CG has advanced considerably, most efforts have concentrated on generating advertising text and images, leaving Creative Video Generation (CVG) relatively underexplored. This gap is largely due to two major challenges faced by Text-to-Video (T2V) models: (a) \textbf{ambiguous semantic alignment}, where models struggle to accurately correlate product selling points with creative video content, and (b) \textbf{inadequate motion adaptability}, resulting in unrealistic movements and distortions. To address these challenges, we develop a comprehensive Advertising Creative Knowledge Base (ACKB) as a foundational resource and propose a knowledge-driven approach (KD-CVG) to overcome the knowledge limitations of existing models. KD-CVG consists of two primary modules: Semantic-Aware Retrieval (SAR) and Multimodal Knowledge Reference (MKR). SAR utilizes the semantic awareness of graph attention networks and reinforcement learning feedback to enhance the model's comprehension of the connections between selling points and creative videos. Building on this, MKR incorporates semantic and motion priors into the T2V model to address existing knowledge gaps. Extensive experiments have demonstrated KD-CVG's superior performance in achieving semantic alignment and motion adaptability, validating its effectiveness over other state-of-the-art methods. The code and dataset will be open source at https://kdcvg.github.io/KDCVG/.
RePainter: Empowering E-commerce Object Removal via Spatial-matting Reinforcement Learning
Oct 09, 2025In web data, product images are central to boosting user engagement and advertising efficacy on e-commerce platforms, yet the intrusive elements such as watermarks and promotional text remain major obstacles to delivering clear and appealing product visuals. Although diffusion-based inpainting methods have advanced, they still face challenges in commercial settings due to unreliable object removal and limited domain-specific adaptation. To tackle these challenges, we propose Repainter, a reinforcement learning framework that integrates spatial-matting trajectory refinement with Group Relative Policy Optimization (GRPO). Our approach modulates attention mechanisms to emphasize background context, generating higher-reward samples and reducing unwanted object insertion. We also introduce a composite reward mechanism that balances global, local, and semantic constraints, effectively reducing visual artifacts and reward hacking. Additionally, we contribute EcomPaint-100K, a high-quality, large-scale e-commerce inpainting dataset, and a standardized benchmark EcomPaint-Bench for fair evaluation. Extensive experiments demonstrate that Repainter significantly outperforms state-of-the-art methods, especially in challenging scenes with intricate compositions. We will release our code and weights upon acceptance.
Learning from Observer Gaze:Zero-Shot Attention Prediction Oriented by Human-Object Interaction Recognition
May 16, 2024



Most existing attention prediction research focuses on salient instances like humans and objects. However, the more complex interaction-oriented attention, arising from the comprehension of interactions between instances by human observers, remains largely unexplored. This is equally crucial for advancing human-machine interaction and human-centered artificial intelligence. To bridge this gap, we first collect a novel gaze fixation dataset named IG, comprising 530,000 fixation points across 740 diverse interaction categories, capturing visual attention during human observers cognitive processes of interactions. Subsequently, we introduce the zero-shot interaction-oriented attention prediction task ZeroIA, which challenges models to predict visual cues for interactions not encountered during training. Thirdly, we present the Interactive Attention model IA, designed to emulate human observers cognitive processes to tackle the ZeroIA problem. Extensive experiments demonstrate that the proposed IA outperforms other state-of-the-art approaches in both ZeroIA and fully supervised settings. Lastly, we endeavor to apply interaction-oriented attention to the interaction recognition task itself. Further experimental results demonstrate the promising potential to enhance the performance and interpretability of existing state-of-the-art HOI models by incorporating real human attention data from IG and attention labels generated by IA.
Taming Uncertainty in Sparse-view Generalizable NeRF via Indirect Diffusion Guidance
Feb 06, 2024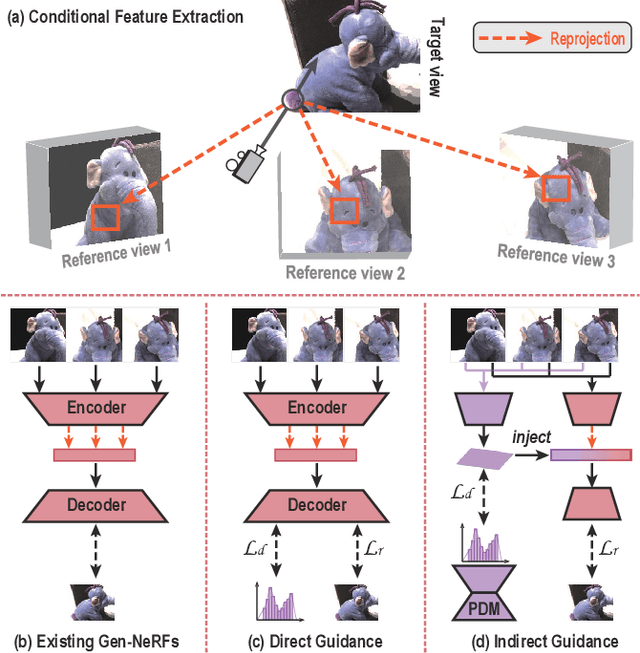
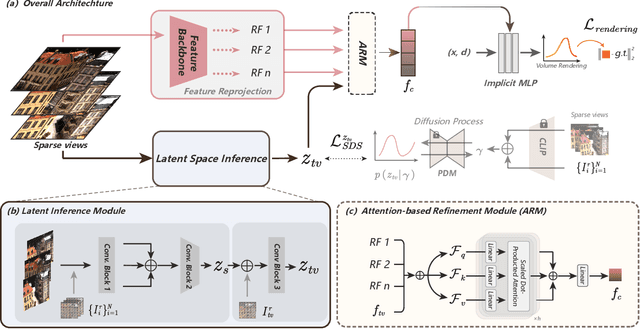
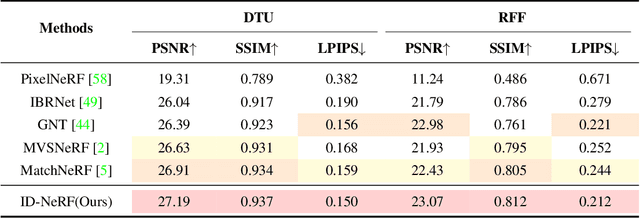
Neural Radiance Fields (NeRF) have demonstrated effectiveness in synthesizing novel views. However, their reliance on dense inputs and scene-specific optimization has limited their broader applicability. Generalizable NeRFs (Gen-NeRF), while intended to address this, often produce blurring artifacts in unobserved regions with sparse inputs, which are full of uncertainty. In this paper, we aim to diminish the uncertainty in Gen-NeRF for plausible renderings. We assume that NeRF's inability to effectively mitigate this uncertainty stems from its inherent lack of generative capacity. Therefore, we innovatively propose an Indirect Diffusion-guided NeRF framework, termed ID-NeRF, to address this uncertainty from a generative perspective by leveraging a distilled diffusion prior as guidance. Specifically, to avoid model confusion caused by directly regularizing with inconsistent samplings as in previous methods, our approach introduces a strategy to indirectly inject the inherently missing imagination into the learned implicit function through a diffusion-guided latent space. Empirical evaluation across various benchmarks demonstrates the superior performance of our approach in handling uncertainty with sparse inputs.
Parallel Medical Imaging: A New Data-Knowledge-Driven Evolutionary Framework for Medical Image Analysis
Mar 12, 2019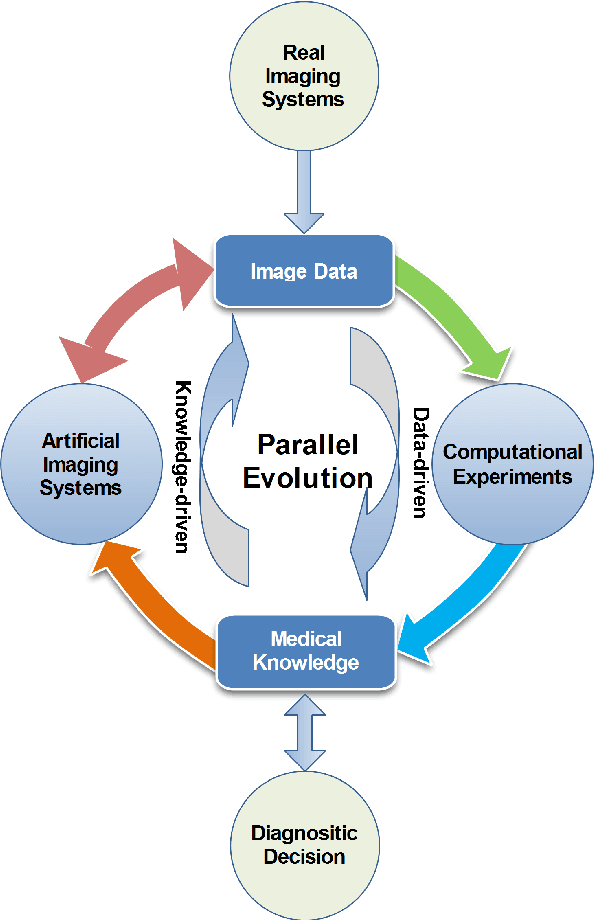
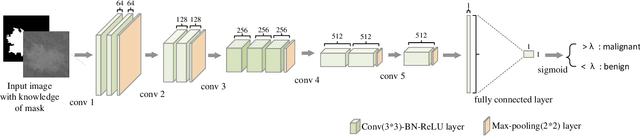
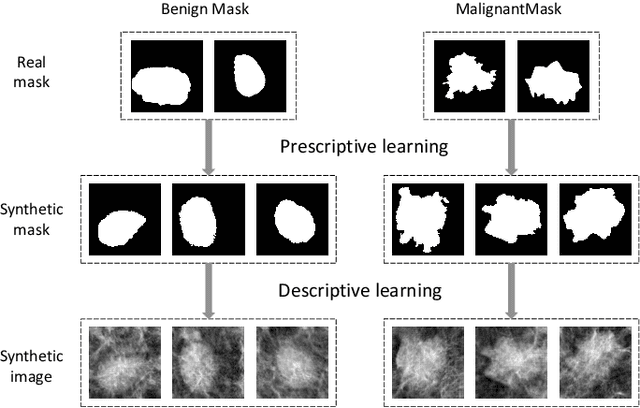
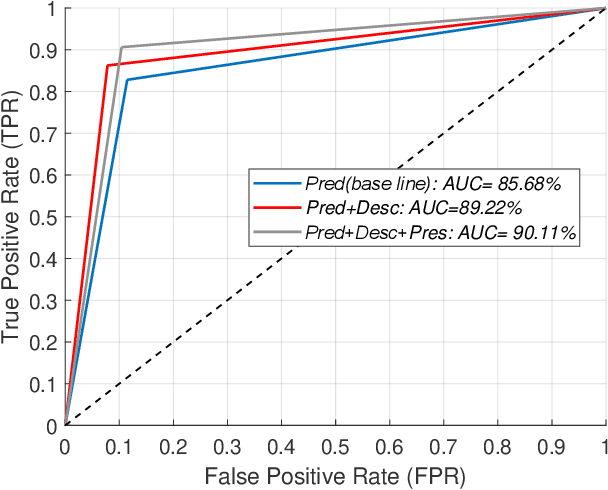
There has been much progress in data-driven artificial intelligence technology for medical image analysis in last decades. However, it still remains a challenge due to its distinctive complexity of acquiring and annotating image data, extracting medical domain knowledge, and explaining the diagnostic decision for medical image analysis. In this paper, we propose a data-knowledge-driven evolutionary framework termed as Parallel Medical Imaging (PMI) for medical image analysis based on the methodology of interactive ACP-based parallel intelligence. In the PMI framework, computational experiments with predictive learning in a data-driven way are conducted to extract medical knowledge for diagnostic decision support. Artificial imaging systems are introduced to select and prescriptively generate medical image data in a knowledge-driven way to utilize medical domain knowledge. Through the parallel evolutionary optimization, our proposed PMI framework can boost the generalization ability and alleviate the limitation of medical interpretation for diagnostic decision. A GANs-based PMI framework for case studies of mammogram analysis is demonstrated in this work.
M4CD: A Robust Change Detection Method for Intelligent Visual Surveillance
Feb 14, 2018

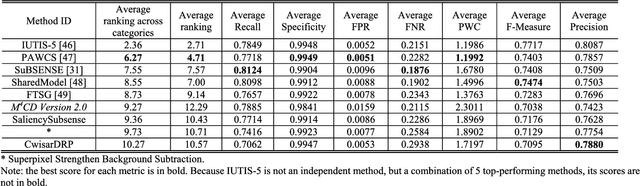

In this paper, we propose a robust change detection method for intelligent visual surveillance. This method, named M4CD, includes three major steps. Firstly, a sample-based background model that integrates color and texture cues is built and updated over time. Secondly, multiple heterogeneous features (including brightness variation, chromaticity variation, and texture variation) are extracted by comparing the input frame with the background model, and a multi-source learning strategy is designed to online estimate the probability distributions for both foreground and background. The three features are approximately conditionally independent, making multi-source learning feasible. Pixel-wise foreground posteriors are then estimated with Bayes rule. Finally, the Markov random field (MRF) optimization and heuristic post-processing techniques are used sequentially to improve accuracy. In particular, a two-layer MRF model is constructed to represent pixel-based and superpixel-based contextual constraints compactly. Experimental results on the CDnet dataset indicate that M4CD is robust under complex environments and ranks among the top methods.
Simultaneous Facial Landmark Detection, Pose and Deformation Estimation under Facial Occlusion
Sep 23, 2017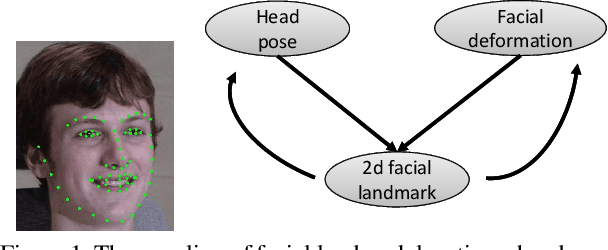
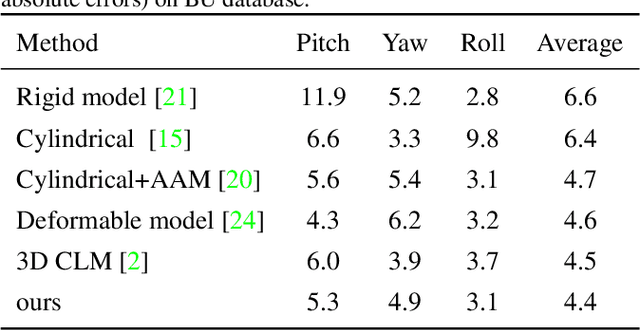

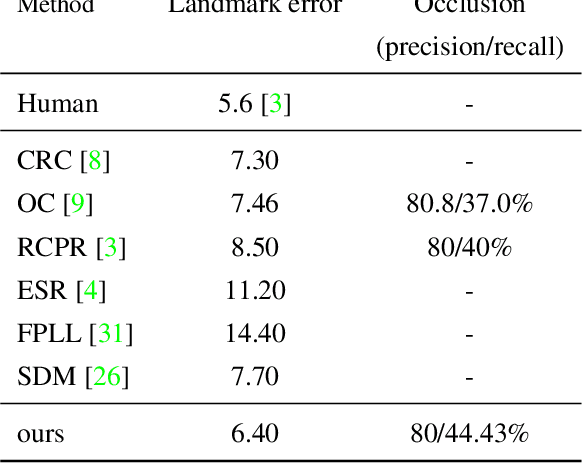
Facial landmark detection, head pose estimation, and facial deformation analysis are typical facial behavior analysis tasks in computer vision. The existing methods usually perform each task independently and sequentially, ignoring their interactions. To tackle this problem, we propose a unified framework for simultaneous facial landmark detection, head pose estimation, and facial deformation analysis, and the proposed model is robust to facial occlusion. Following a cascade procedure augmented with model-based head pose estimation, we iteratively update the facial landmark locations, facial occlusion, head pose and facial de- formation until convergence. The experimental results on benchmark databases demonstrate the effectiveness of the proposed method for simultaneous facial landmark detection, head pose and facial deformation estimation, even if the images are under facial occlusion.