 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Triplane Transformers as Occupancy World Models
Mar 10, 2025Recent years have seen significant advances in world models, which primarily focus on learning fine-grained correlations between an agent's motion trajectory and the resulting changes in its surrounding environment. However, existing methods often struggle to capture such fine-grained correlations and achieve real-time predictions. To address this, we propose a new 4D occupancy world model for autonomous driving, termed T$^3$Former. T$^3$Former begins by pre-training a compact triplane representation that efficiently compresses the 3D semantically occupied environment. Next, T$^3$Former extracts multi-scale temporal motion features from the historical triplane and employs an autoregressive approach to iteratively predict the next triplane changes. Finally, T$^3$Former combines the triplane changes with the previous ones to decode them into future occupancy results and ego-motion trajectories. Experimental results demonstrate the superiority of T$^3$Former, achieving 1.44$\times$ faster inference speed (26 FPS), while improving the mean IoU to 36.09 and reducing the mean absolute planning error to 1.0 meters.
LEAP: Enhancing Vision-Based Occupancy Networks with Lightweight Spatio-Temporal Correlation
Feb 21, 2025Vision-based occupancy networks provide an end-to-end solution for reconstructing the surrounding environment using semantic occupied voxels derived from multi-view images. This technique relies on effectively learning the correlation between pixel-level visual information and voxels. Despite recent advancements, occupancy results still suffer from limited accuracy due to occlusions and sparse visual cues. To address this, we propose a Lightweight Spatio-Temporal Correlation (LEAP)} method, which significantly enhances the performance of existing occupancy networks with minimal computational overhead. LEAP can be seamlessly integrated into various baseline networks, enabling a plug-and-play application. LEAP operates in three stages: 1) it tokenizes information from recent baseline and motion features into a shared, compact latent space; 2) it establishes full correlation through a tri-stream fusion architecture; 3) it generates occupancy results that strengthen the baseline's output. Extensive experiments demonstrate the efficiency and effectiveness of our method, outperforming the latest baseline models. The source code and several demos are available in the supplementary material.
HouseLLM: LLM-Assisted Two-Phase Text-to-Floorplan Generation
Nov 20, 2024This paper proposes a two-phase text-to-floorplan generation method, which guides a Large Language Model (LLM) to generate an initial layout (Layout-LLM) and refines them into the final floorplans through conditional diffusion model. We incorporate a Chain-of-Thought approach to prompt the LLM based on user text specifications, enabling a more user-friendly and intuitive house layout design. This method allows users to describe their needs in natural language, enhancing accessibility and providing clearer geometric constraints. The final floorplans generated by Layout-LLM through conditional diffusion refinement are more accurate and better meet user requirements. Experimental results demonstrate that our approach achieves state-of-the-art performance across all metrics, validating its effectiveness in practical home design applications. We plan to release our code for public use.
Partitioning Message Passing for Graph Fraud Detection
Nov 16, 2024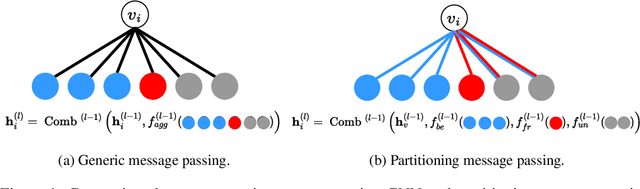
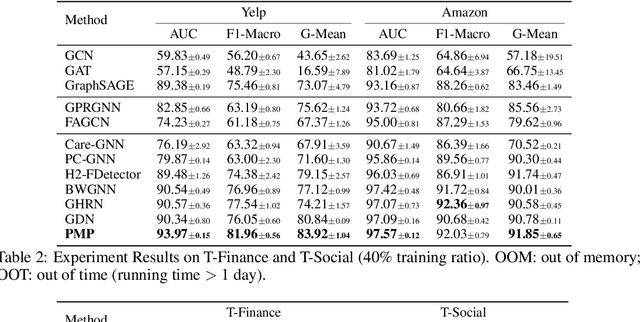
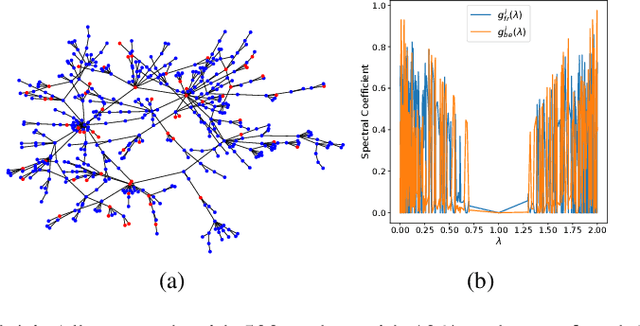
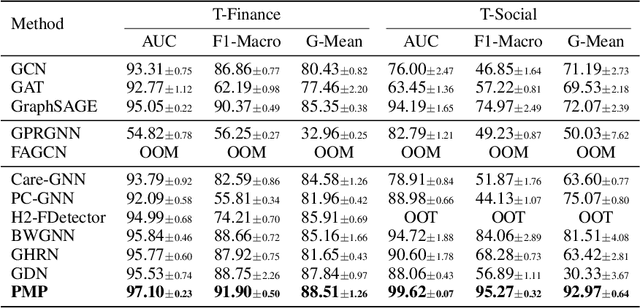
Label imbalance and homophily-heterophily mixture are the fundamental problems encountered when applying Graph Neural Networks (GNNs) to Graph Fraud Detection (GFD) tasks. Existing GNN-based GFD models are designed to augment graph structure to accommodate the inductive bias of GNNs towards homophily, by excluding heterophilic neighbors during message passing. In our work, we argue that the key to applying GNNs for GFD is not to exclude but to {\em distinguish} neighbors with different labels. Grounded in this perspective, we introduce Partitioning Message Passing (PMP), an intuitive yet effective message passing paradigm expressly crafted for GFD. Specifically, in the neighbor aggregation stage of PMP, neighbors with different classes are aggregated with distinct node-specific aggregation functions. By this means, the center node can adaptively adjust the information aggregated from its heterophilic and homophilic neighbors, thus avoiding the model gradient being dominated by benign nodes which occupy the majority of the population. We theoretically establish a connection between the spatial formulation of PMP and spectral analysis to characterize that PMP operates an adaptive node-specific spectral graph filter, which demonstrates the capability of PMP to handle heterophily-homophily mixed graphs. Extensive experimental results show that PMP can significantly boost the performance on GFD tasks.
Appformer: A Novel Framework for Mobile App Usage Prediction Leveraging Progressive Multi-Modal Data Fusion and Feature Extraction
Jul 28, 2024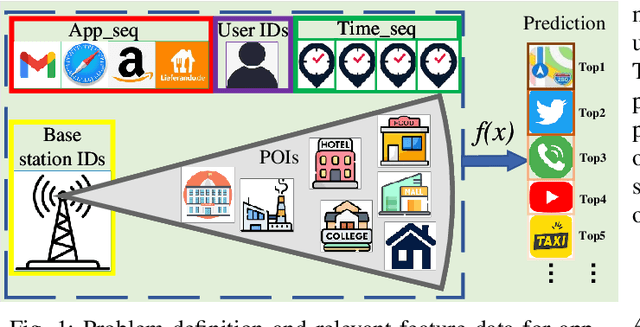
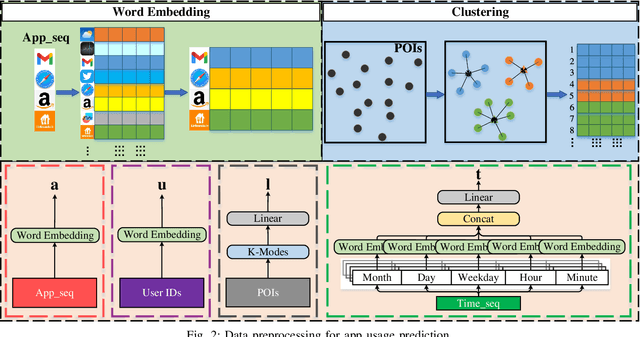
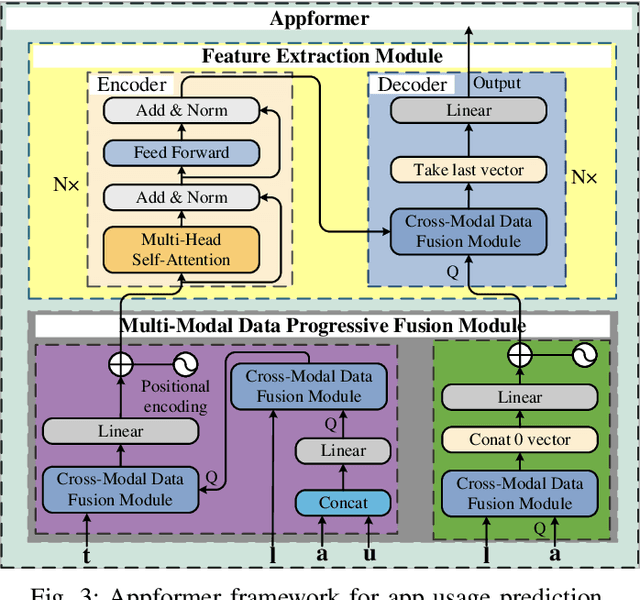
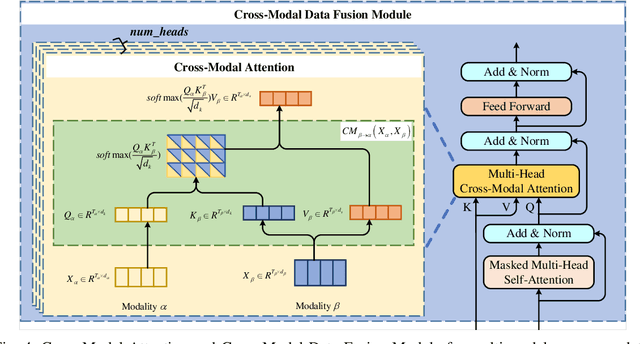
This article presents Appformer, a novel mobile application prediction framework inspired by the efficiency of Transformer-like architectures in processing sequential data through self-attention mechanisms. Combining a Multi-Modal Data Progressive Fusion Module with a sophisticated Feature Extraction Module, Appformer leverages the synergies of multi-modal data fusion and data mining techniques while maintaining user privacy. The framework employs Points of Interest (POIs) associated with base stations, optimizing them through comprehensive comparative experiments to identify the most effective clustering method. These refined inputs are seamlessly integrated into the initial phases of cross-modal data fusion, where temporal units are encoded via word embeddings and subsequently merged in later stages. The Feature Extraction Module, employing Transformer-like architectures specialized for time series analysis, adeptly distils comprehensive features. It meticulously fine-tunes the outputs from the fusion module, facilitating the extraction of high-calibre, multi-modal features, thus guaranteeing a robust and efficient extraction process. Extensive experimental validation confirms Appformer's effectiveness, attaining state-of-the-art (SOTA) metrics in mobile app usage prediction, thereby signifying a notable progression in this field.
IE-NeRF: Inpainting Enhanced Neural Radiance Fields in the Wild
Jul 15, 2024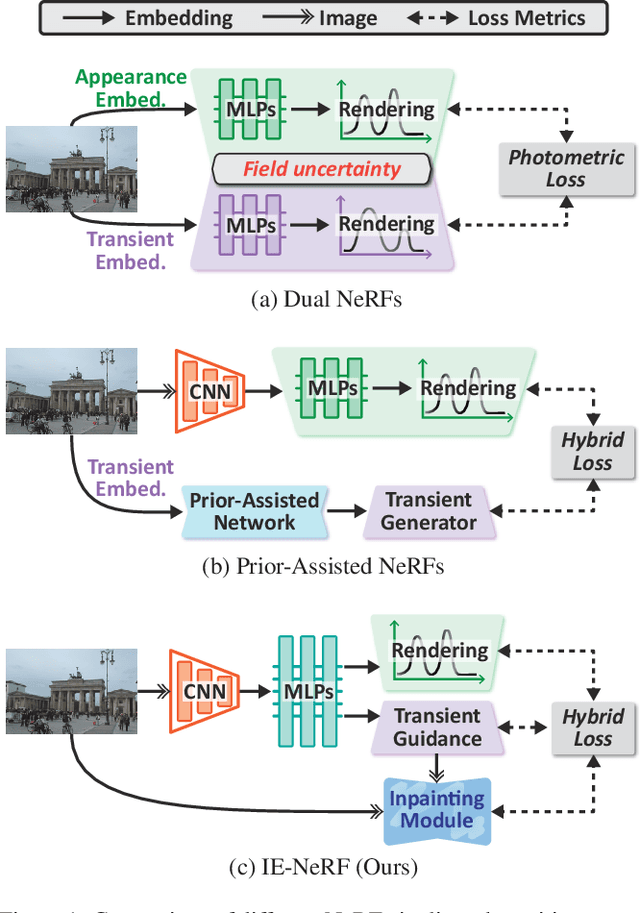

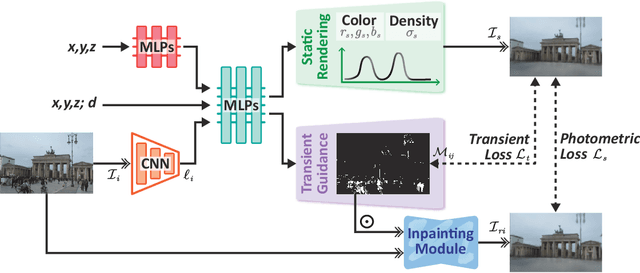
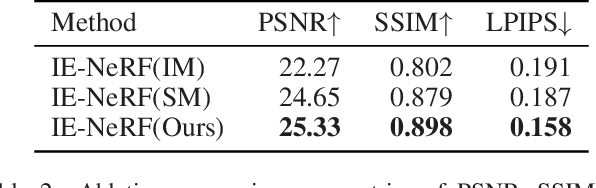
We present a novel approach for synthesizing realistic novel views using Neural Radiance Fields (NeRF) with uncontrolled photos in the wild. While NeRF has shown impressive results in controlled settings, it struggles with transient objects commonly found in dynamic and time-varying scenes. Our framework called \textit{Inpainting Enhanced NeRF}, or \ours, enhances the conventional NeRF by drawing inspiration from the technique of image inpainting. Specifically, our approach extends the Multi-Layer Perceptrons (MLP) of NeRF, enabling it to simultaneously generate intrinsic properties (static color, density) and extrinsic transient masks. We introduce an inpainting module that leverages the transient masks to effectively exclude occlusions, resulting in improved volume rendering quality. Additionally, we propose a new training strategy with frequency regularization to address the sparsity issue of low-frequency transient components. We evaluate our approach on internet photo collections of landmarks, demonstrating its ability to generate high-quality novel views and achieve state-of-the-art performance.
Commute Graph Neural Networks
Jun 30, 2024Graph Neural Networks (GNNs) have shown remarkable success in learning from graph-structured data. However, their application to directed graphs (digraphs) presents unique challenges, primarily due to the inherent asymmetry in node relationships. Traditional GNNs are adept at capturing unidirectional relations but fall short in encoding the mutual path dependencies between nodes, such as asymmetrical shortest paths typically found in digraphs. Recognizing this gap, we introduce Commute Graph Neural Networks (CGNN), an approach that seamlessly integrates node-wise commute time into the message passing scheme. The cornerstone of CGNN is an efficient method for computing commute time using a newly formulated digraph Laplacian. Commute time information is then integrated into the neighborhood aggregation process, with neighbor contributions weighted according to their respective commute time to the central node in each layer. It enables CGNN to directly capture the mutual, asymmetric relationships in digraphs.
Efficient Graph Similarity Computation with Alignment Regularization
Jun 21, 2024We consider the graph similarity computation (GSC) task based on graph edit distance (GED) estimation. State-of-the-art methods treat GSC as a learning-based prediction task using Graph Neural Networks (GNNs). To capture fine-grained interactions between pair-wise graphs, these methods mostly contain a node-level matching module in the end-to-end learning pipeline, which causes high computational costs in both the training and inference stages. We show that the expensive node-to-node matching module is not necessary for GSC, and high-quality learning can be attained with a simple yet powerful regularization technique, which we call the Alignment Regularization (AReg). In the training stage, the AReg term imposes a node-graph correspondence constraint on the GNN encoder. In the inference stage, the graph-level representations learned by the GNN encoder are directly used to compute the similarity score without using AReg again to speed up inference. We further propose a multi-scale GED discriminator to enhance the expressive ability of the learned representations. Extensive experiments on real-world datasets demonstrate the effectiveness, efficiency and transferability of our approach.
MC-GPT: Empowering Vision-and-Language Navigation with Memory Map and Reasoning Chains
May 17, 2024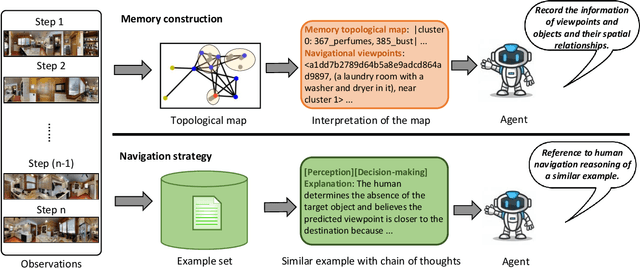
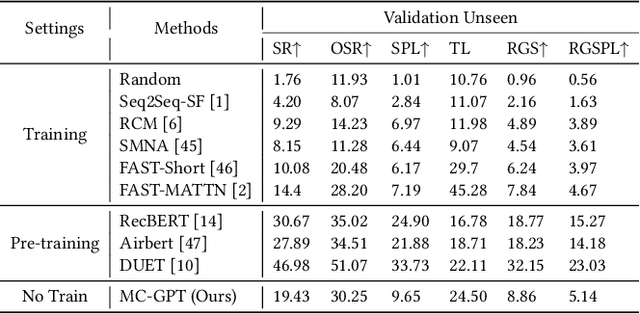
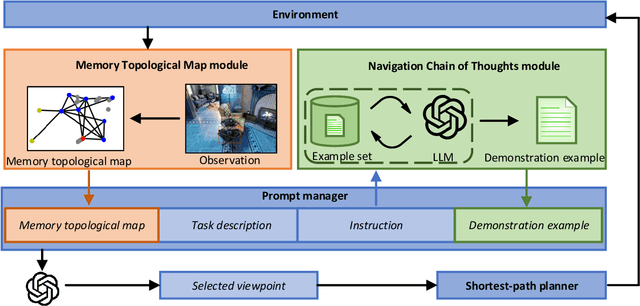
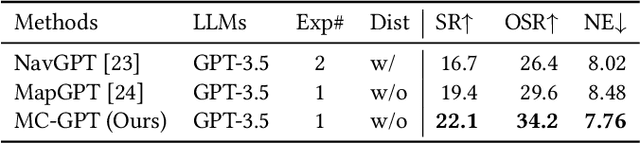
In the Vision-and-Language Navigation (VLN) task, the agent is required to navigate to a destination following a natural language instruction. While learning-based approaches have been a major solution to the task, they suffer from high training costs and lack of interpretability. Recently, Large Language Models (LLMs) have emerged as a promising tool for VLN due to their strong generalization capabilities. However, existing LLM-based methods face limitations in memory construction and diversity of navigation strategies. To address these challenges, we propose a suite of techniques. Firstly, we introduce a method to maintain a topological map that stores navigation history, retaining information about viewpoints, objects, and their spatial relationships. This map also serves as a global action space. Additionally, we present a Navigation Chain of Thoughts module, leveraging human navigation examples to enrich navigation strategy diversity. Finally, we establish a pipeline that integrates navigational memory and strategies with perception and action prediction modules. Experimental results on the REVERIE and R2R datasets show that our method effectively enhances the navigation ability of the LLM and improves the interpretability of navigation reasoning.
Taming Uncertainty in Sparse-view Generalizable NeRF via Indirect Diffusion Guidance
Feb 06, 2024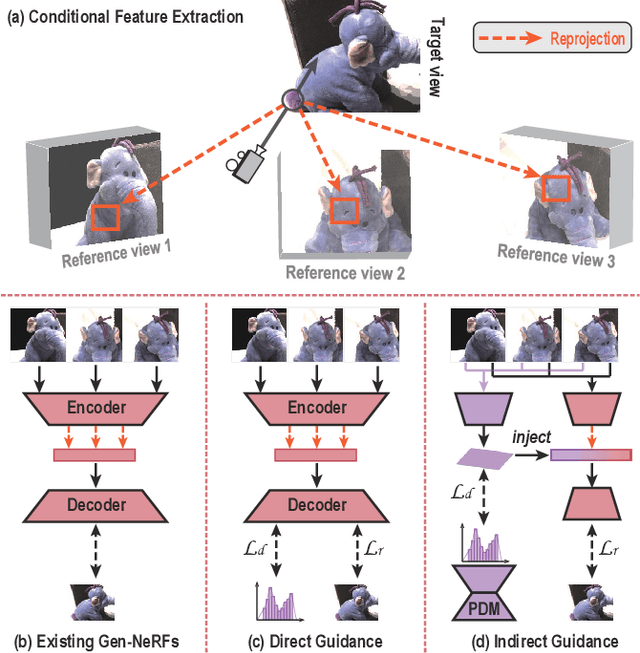
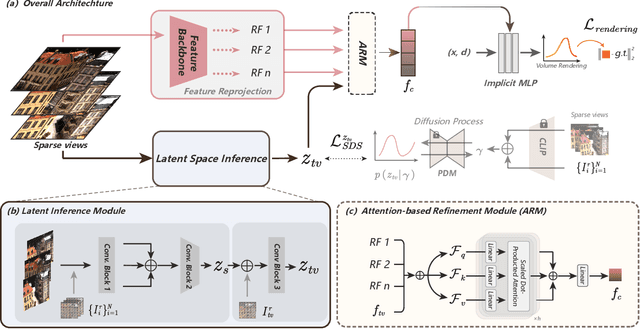
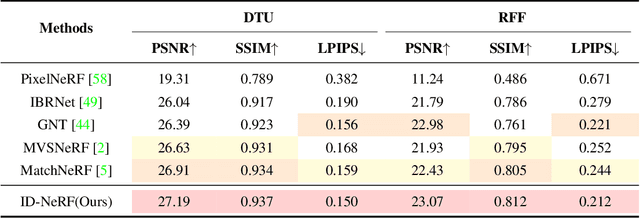
Neural Radiance Fields (NeRF) have demonstrated effectiveness in synthesizing novel views. However, their reliance on dense inputs and scene-specific optimization has limited their broader applicability. Generalizable NeRFs (Gen-NeRF), while intended to address this, often produce blurring artifacts in unobserved regions with sparse inputs, which are full of uncertainty. In this paper, we aim to diminish the uncertainty in Gen-NeRF for plausible renderings. We assume that NeRF's inability to effectively mitigate this uncertainty stems from its inherent lack of generative capacity. Therefore, we innovatively propose an Indirect Diffusion-guided NeRF framework, termed ID-NeRF, to address this uncertainty from a generative perspective by leveraging a distilled diffusion prior as guidance. Specifically, to avoid model confusion caused by directly regularizing with inconsistent samplings as in previous methods, our approach introduces a strategy to indirectly inject the inherently missing imagination into the learned implicit function through a diffusion-guided latent space. Empirical evaluation across various benchmarks demonstrates the superior performance of our approach in handling uncertainty with sparse inputs.