 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiCounter: Multiple Action Agnostic Repetition Counting in Untrimmed Videos
Sep 06, 2024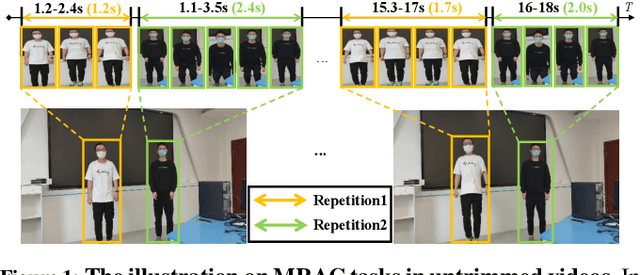

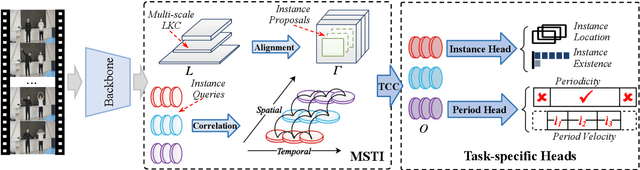
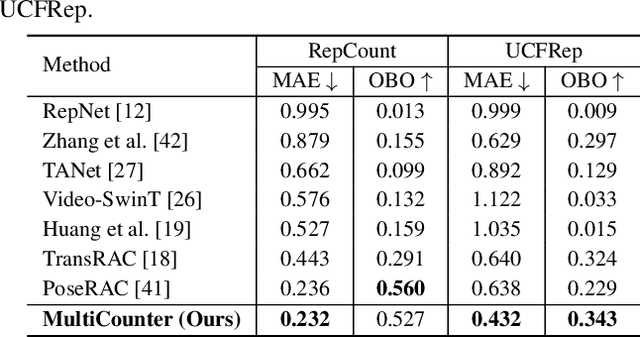
Multi-instance Repetitive Action Counting (MRAC) aims to estimate the number of repetitive actions performed by multiple instances in untrimmed videos, commonly found in human-centric domains like sports and exercise. In this paper, we propose MultiCounter, a fully end-to-end deep learning framework that enables simultaneous detection, tracking, and counting of repetitive actions of multiple human instances. Specifically, MultiCounter incorporates two novel modules: 1) mixed spatiotemporal interaction for efficient context correlation across consecutive frames, and 2) task-specific heads for accurate perception of periodic boundaries and generalization for action-agnostic human instances. We train MultiCounter on a synthetic dataset called MultiRep generated from annotated real-world videos. Experiments on the MultiRep dataset validate the fundamental challenge of MRAC tasks and showcase the superiority of our proposed model. Compared to ByteTrack+RepNet, a solution that combines an advanced tracker with a single repetition counter, MultiCounter substantially improves Period-mAP by 41.0%, reduces AvgMAE by 58.6%, and increases AvgOBO 1.48 times. This sets a new benchmark in the field of MRAC. Moreover, MultiCounter runs in real-time on a commodity GPU server and is insensitive to the number of human instances in a video.
Appformer: A Novel Framework for Mobile App Usage Prediction Leveraging Progressive Multi-Modal Data Fusion and Feature Extraction
Jul 28, 2024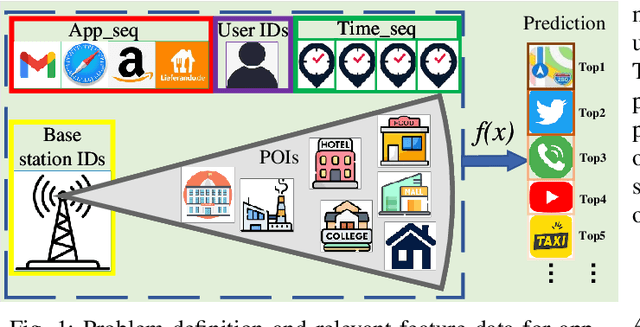
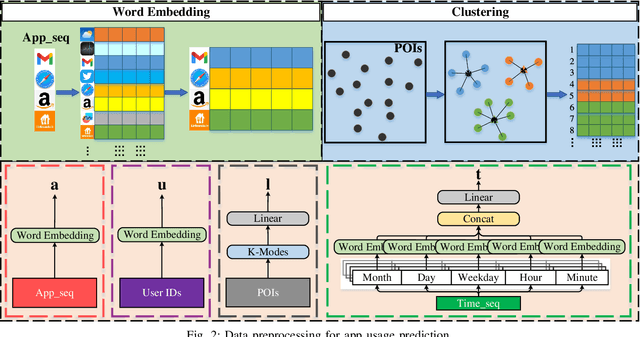
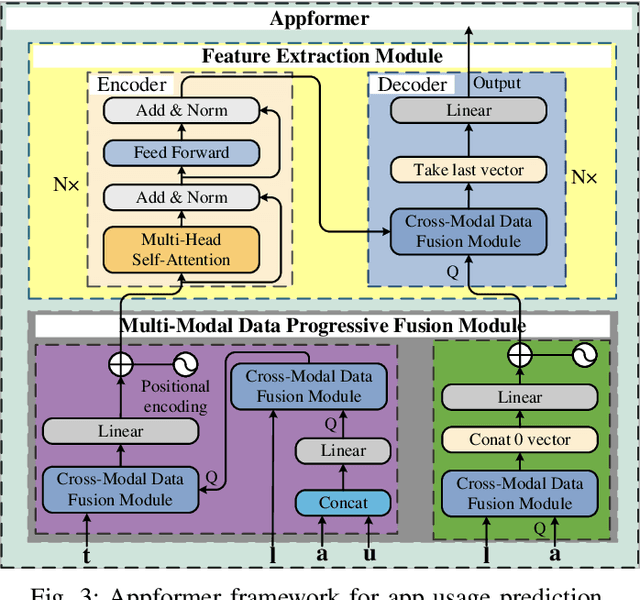
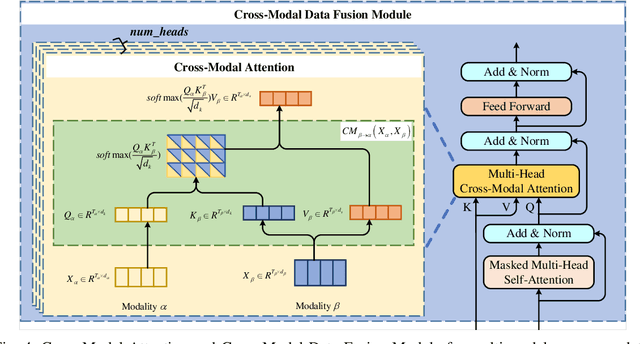
This article presents Appformer, a novel mobile application prediction framework inspired by the efficiency of Transformer-like architectures in processing sequential data through self-attention mechanisms. Combining a Multi-Modal Data Progressive Fusion Module with a sophisticated Feature Extraction Module, Appformer leverages the synergies of multi-modal data fusion and data mining techniques while maintaining user privacy. The framework employs Points of Interest (POIs) associated with base stations, optimizing them through comprehensive comparative experiments to identify the most effective clustering method. These refined inputs are seamlessly integrated into the initial phases of cross-modal data fusion, where temporal units are encoded via word embeddings and subsequently merged in later stages. The Feature Extraction Module, employing Transformer-like architectures specialized for time series analysis, adeptly distils comprehensive features. It meticulously fine-tunes the outputs from the fusion module, facilitating the extraction of high-calibre, multi-modal features, thus guaranteeing a robust and efficient extraction process. Extensive experimental validation confirms Appformer's effectiveness, attaining state-of-the-art (SOTA) metrics in mobile app usage prediction, thereby signifying a notable progression in this field.