 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFullPart: Generating each 3D Part at Full Resolution
Oct 30, 2025Part-based 3D generation holds great potential for various applications. Previous part generators that represent parts using implicit vector-set tokens often suffer from insufficient geometric details. Another line of work adopts an explicit voxel representation but shares a global voxel grid among all parts; this often causes small parts to occupy too few voxels, leading to degraded quality. In this paper, we propose FullPart, a novel framework that combines both implicit and explicit paradigms. It first derives the bounding box layout through an implicit box vector-set diffusion process, a task that implicit diffusion handles effectively since box tokens contain little geometric detail. Then, it generates detailed parts, each within its own fixed full-resolution voxel grid. Instead of sharing a global low-resolution space, each part in our method - even small ones - is generated at full resolution, enabling the synthesis of intricate details. We further introduce a center-point encoding strategy to address the misalignment issue when exchanging information between parts of different actual sizes, thereby maintaining global coherence. Moreover, to tackle the scarcity of reliable part data, we present PartVerse-XL, the largest human-annotated 3D part dataset to date with 40K objects and 320K parts. Extensive experiments demonstrate that FullPart achieves state-of-the-art results in 3D part generation. We will release all code, data, and model to benefit future research in 3D part generation.
IE-NeRF: Inpainting Enhanced Neural Radiance Fields in the Wild
Jul 15, 2024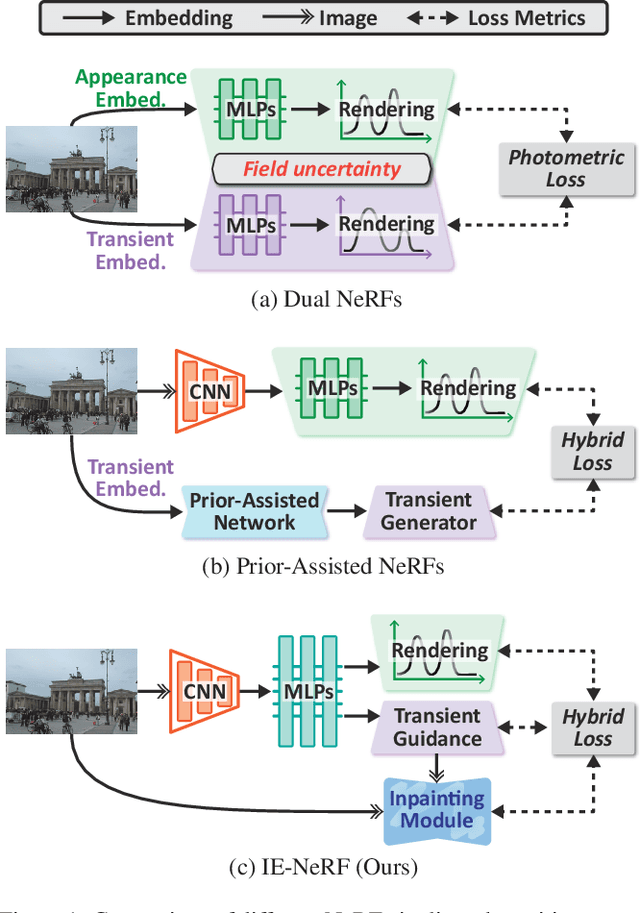

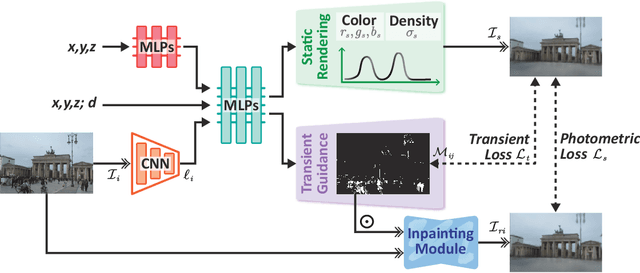
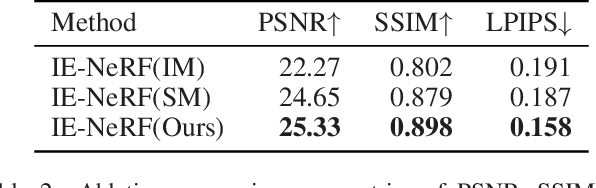
We present a novel approach for synthesizing realistic novel views using Neural Radiance Fields (NeRF) with uncontrolled photos in the wild. While NeRF has shown impressive results in controlled settings, it struggles with transient objects commonly found in dynamic and time-varying scenes. Our framework called \textit{Inpainting Enhanced NeRF}, or \ours, enhances the conventional NeRF by drawing inspiration from the technique of image inpainting. Specifically, our approach extends the Multi-Layer Perceptrons (MLP) of NeRF, enabling it to simultaneously generate intrinsic properties (static color, density) and extrinsic transient masks. We introduce an inpainting module that leverages the transient masks to effectively exclude occlusions, resulting in improved volume rendering quality. Additionally, we propose a new training strategy with frequency regularization to address the sparsity issue of low-frequency transient components. We evaluate our approach on internet photo collections of landmarks, demonstrating its ability to generate high-quality novel views and achieve state-of-the-art performance.
Taming Uncertainty in Sparse-view Generalizable NeRF via Indirect Diffusion Guidance
Feb 06, 2024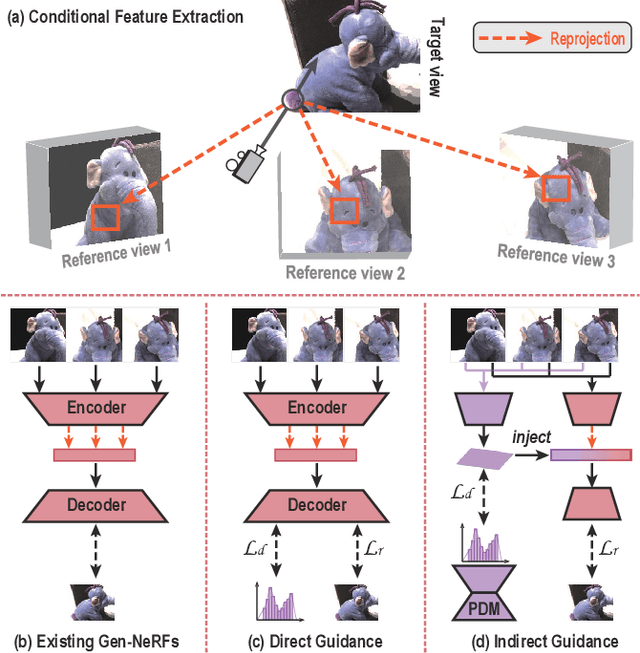
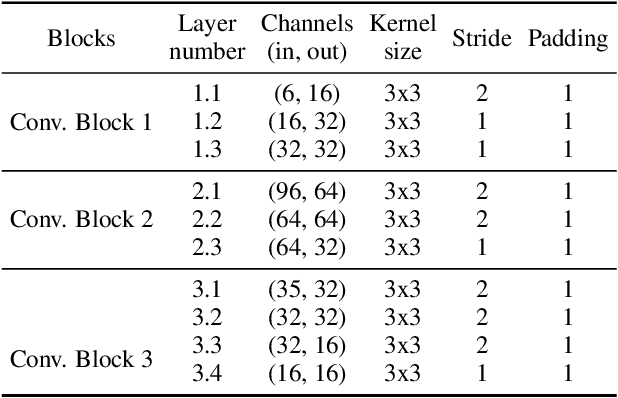
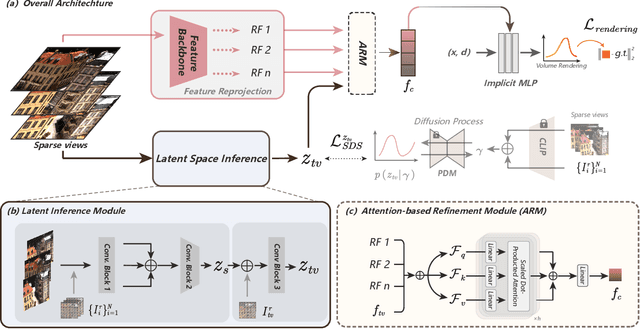
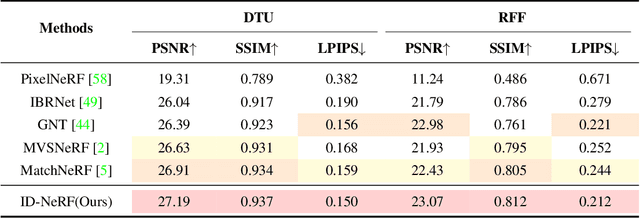
Neural Radiance Fields (NeRF) have demonstrated effectiveness in synthesizing novel views. However, their reliance on dense inputs and scene-specific optimization has limited their broader applicability. Generalizable NeRFs (Gen-NeRF), while intended to address this, often produce blurring artifacts in unobserved regions with sparse inputs, which are full of uncertainty. In this paper, we aim to diminish the uncertainty in Gen-NeRF for plausible renderings. We assume that NeRF's inability to effectively mitigate this uncertainty stems from its inherent lack of generative capacity. Therefore, we innovatively propose an Indirect Diffusion-guided NeRF framework, termed ID-NeRF, to address this uncertainty from a generative perspective by leveraging a distilled diffusion prior as guidance. Specifically, to avoid model confusion caused by directly regularizing with inconsistent samplings as in previous methods, our approach introduces a strategy to indirectly inject the inherently missing imagination into the learned implicit function through a diffusion-guided latent space. Empirical evaluation across various benchmarks demonstrates the superior performance of our approach in handling uncertainty with sparse inputs.