 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Crowd Counting With Density Guidance For Scene Adaptaion
Feb 08, 2026Crowd scenes captured by cameras at different locations vary greatly, and existing crowd models have limited generalization for unseen surveillance scenes. To improve the generalization of the model, we regard different surveillance scenes as different category scenes, and introduce few-shot learning to make the model adapt to the unseen surveillance scene that belongs to the given exemplar category scene. To this end, we propose to leverage local and global density characteristics to guide the model of crowd counting for unseen surveillance scenes. Specifically, to enable the model to adapt to the varying density variations in the target scene, we propose the multiple local density learner to learn multi prototypes which represent different density distributions in the support scene. Subsequently, these multiple local density similarity matrixes are encoded. And they are utilized to guide the model in a local way. To further adapt to the global density in the target scene, the global density features are extracted from the support image, then it is used to guide the model in a global way. Experiments on three surveillance datasets shows that proposed method can adapt to the unseen surveillance scene and outperform recent state-of-the-art methods in the few-shot crowd counting.
Self-Supervised Enhancement for Depth from a Lightweight ToF Sensor with Monocular Images
Jun 16, 2025



Depth map enhancement using paired high-resolution RGB images offers a cost-effective solution for improving low-resolution depth data from lightweight ToF sensors. Nevertheless, naively adopting a depth estimation pipeline to fuse the two modalities requires groundtruth depth maps for supervision. To address this, we propose a self-supervised learning framework, SelfToF, which generates detailed and scale-aware depth maps. Starting from an image-based self-supervised depth estimation pipeline, we add low-resolution depth as inputs, design a new depth consistency loss, propose a scale-recovery module, and finally obtain a large performance boost. Furthermore, since the ToF signal sparsity varies in real-world applications, we upgrade SelfToF to SelfToF* with submanifold convolution and guided feature fusion. Consequently, SelfToF* maintain robust performance across varying sparsity levels in ToF data. Overall, our proposed method is both efficient and effective, as verified by extensive experiments on the NYU and ScanNet datasets. The code will be made public.
ROA-BEV: 2D Region-Oriented Attention for BEV-based 3D Object
Oct 14, 2024



Vision-based BEV (Bird-Eye-View) 3D object detection has recently become popular in autonomous driving. However, objects with a high similarity to the background from a camera perspective cannot be detected well by existing methods. In this paper, we propose 2D Region-oriented Attention for a BEV-based 3D Object Detection Network (ROA-BEV), which can make the backbone focus more on feature learning in areas where objects may exist. Moreover, our method increases the information content of ROA through a multi-scale structure. In addition, every block of ROA utilizes a large kernel to ensure that the receptive field is large enough to catch large objects' information. Experiments on nuScenes show that ROA-BEV improves the performance based on BEVDet and BEVDepth. The code will be released soon.
IE-NeRF: Inpainting Enhanced Neural Radiance Fields in the Wild
Jul 15, 2024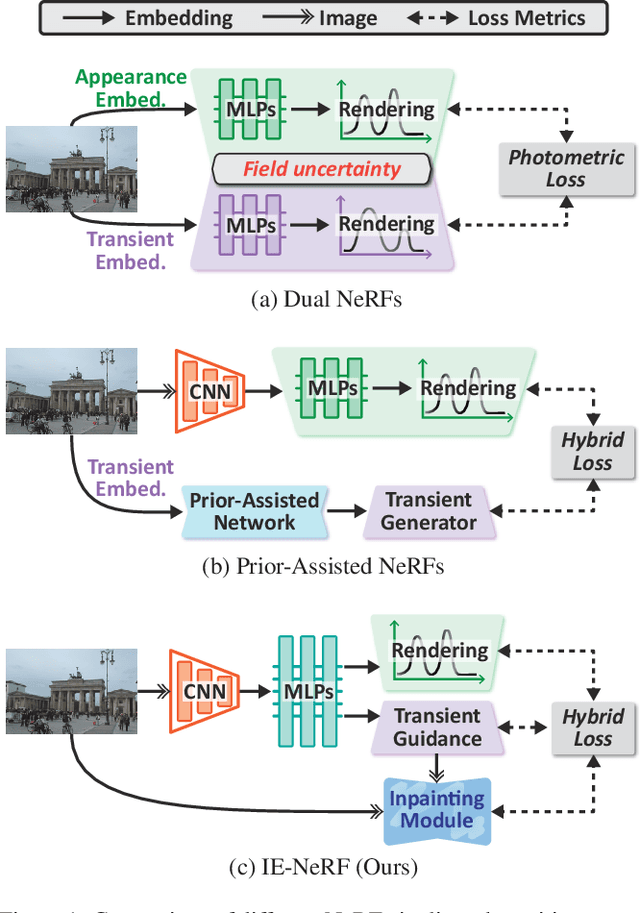

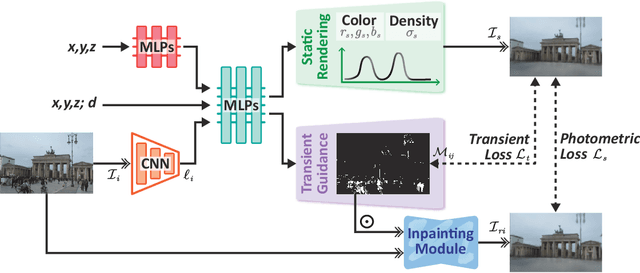
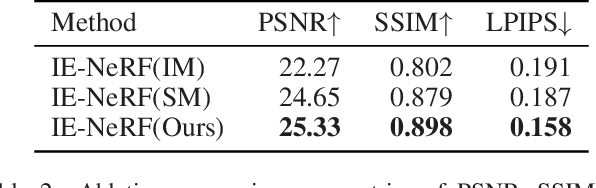
We present a novel approach for synthesizing realistic novel views using Neural Radiance Fields (NeRF) with uncontrolled photos in the wild. While NeRF has shown impressive results in controlled settings, it struggles with transient objects commonly found in dynamic and time-varying scenes. Our framework called \textit{Inpainting Enhanced NeRF}, or \ours, enhances the conventional NeRF by drawing inspiration from the technique of image inpainting. Specifically, our approach extends the Multi-Layer Perceptrons (MLP) of NeRF, enabling it to simultaneously generate intrinsic properties (static color, density) and extrinsic transient masks. We introduce an inpainting module that leverages the transient masks to effectively exclude occlusions, resulting in improved volume rendering quality. Additionally, we propose a new training strategy with frequency regularization to address the sparsity issue of low-frequency transient components. We evaluate our approach on internet photo collections of landmarks, demonstrating its ability to generate high-quality novel views and achieve state-of-the-art performance.
Advertising strategy for profit-maximization: a novel practice on Tmall's online ads manager platforms
Oct 31, 2022Ads manager platform gains popularity among numerous e-commercial vendors/advertisers. It helps advertisers to facilitate the process of displaying their ads to target customers. One of the main challenges faced by advertisers, especially small and medium-sized enterprises, is to configure their advertising strategy properly. An ineffective advertising strategy will bring too many ``just looking'' clicks and, eventually, generate high advertising expenditure unproportionally to the growth of sales. In this paper, we present a novel profit-maximization model for online advertising optimization. The optimization problem is constructed to find optimal set of features to maximize the probability that target customers buy advertising products. We further reformulate the optimization problem to a knapsack problem with changeable parameters, and introduce a self-adjusted algorithm for finding the solution to the problem. Numerical experiment based on statistical data from Tmall show that our proposed method can optimize the advertising strategy given expenditure budget effectively.
SSR-HEF: Crowd Counting with Multi-Scale Semantic Refining and Hard Example Focusing
Apr 15, 2022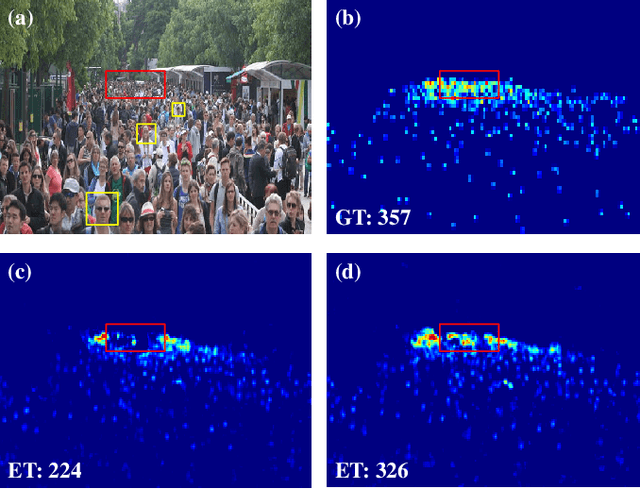
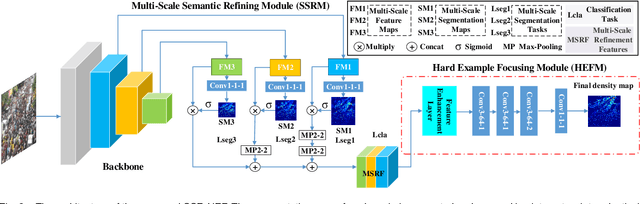
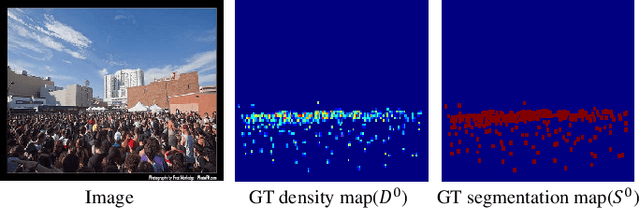
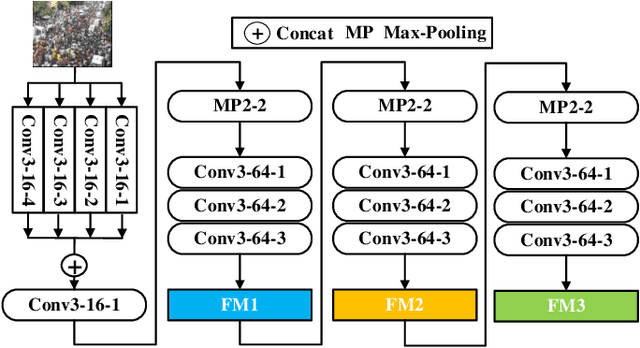
Crowd counting based on density maps is generally regarded as a regression task.Deep learning is used to learn the mapping between image content and crowd density distribution. Although great success has been achieved, some pedestrians far away from the camera are difficult to be detected. And the number of hard examples is often larger. Existing methods with simple Euclidean distance algorithm indiscriminately optimize the hard and easy examples so that the densities of hard examples are usually incorrectly predicted to be lower or even zero, which results in large counting errors. To address this problem, we are the first to propose the Hard Example Focusing(HEF) algorithm for the regression task of crowd counting. The HEF algorithm makes our model rapidly focus on hard examples by attenuating the contribution of easy examples.Then higher importance will be given to the hard examples with wrong estimations. Moreover, the scale variations in crowd scenes are large, and the scale annotations are labor-intensive and expensive. By proposing a multi-Scale Semantic Refining (SSR) strategy, lower layers of our model can break through the limitation of deep learning to capture semantic features of different scales to sufficiently deal with the scale variation. We perform extensive experiments on six benchmark datasets to verify the proposed method. Results indicate the superiority of our proposed method over the state-of-the-art methods. Moreover, our designed model is smaller and faster.
* Accepted by IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS
Crowd counting with segmentation attention convolutional neural network
Apr 15, 2022

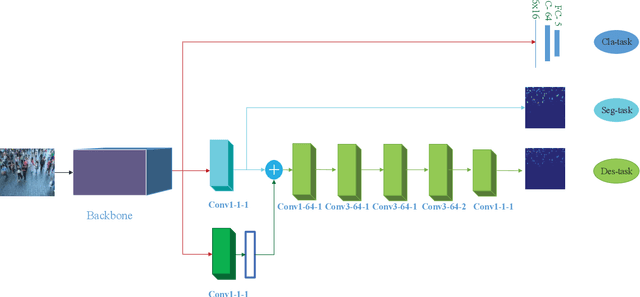

Deep learning occupies an undisputed dominance in crowd counting. In this paper, we propose a novel convolutional neural network (CNN) architecture called SegCrowdNet. Despite the complex background in crowd scenes, the proposeSegCrowdNet still adaptively highlights the human head region and suppresses the non-head region by segmentation. With the guidance of an attention mechanism, the proposed SegCrowdNet pays more attention to the human head region and automatically encodes the highly refined density map. The crowd count can be obtained by integrating the density map. To adapt the variation of crowd counts, SegCrowdNet intelligently classifies the crowd count of each image into several groups. In addition, the multi-scale features are learned and extracted in the proposed SegCrowdNet to overcome the scale variations of the crowd. To verify the effectiveness of our proposed method, extensive experiments are conducted on four challenging datasets. The results demonstrate that our proposed SegCrowdNet achieves excellent performance compared with the state-of-the-art methods.
* Accepted by IET Image Processing
Crowd counting with crowd attention convolutional neural network
Apr 15, 2022



Crowd counting is a challenging problem due to the scene complexity and scale variation. Although deep learning has achieved great improvement in crowd counting, scene complexity affects the judgement of these methods and they usually regard some objects as people mistakenly; causing potentially enormous errors in the crowd counting result. To address the problem, we propose a novel end-to-end model called Crowd Attention Convolutional Neural Network (CAT-CNN). Our CAT-CNN can adaptively assess the importance of a human head at each pixel location by automatically encoding a confidence map. With the guidance of the confidence map, the position of human head in estimated density map gets more attention to encode the final density map, which can avoid enormous misjudgements effectively. The crowd count can be obtained by integrating the final density map. To encode a highly refined density map, the total crowd count of each image is classified in a designed classification task and we first explicitly map the prior of the population-level category to feature maps. To verify the efficiency of our proposed method, extensive experiments are conducted on three highly challenging datasets. Results establish the superiority of our method over many state-of-the-art methods.
* Accepted by Neurocomputing
Greedy Offset-Guided Keypoint Grouping for Human Pose Estimation
Jul 07, 2021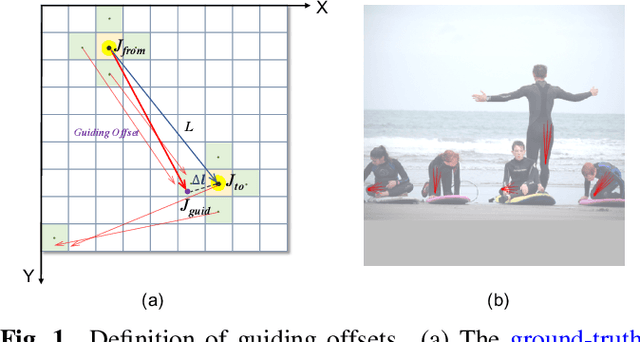
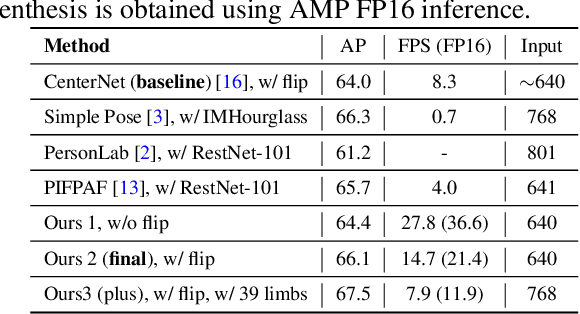


We propose a simple yet reliable bottom-up approach with a good trade-off between accuracy and efficiency for the problem of multi-person pose estimation. Given an image, we employ an Hourglass Network to infer all the keypoints from different persons indiscriminately as well as the guiding offsets connecting the adjacent keypoints belonging to the same persons. Then, we greedily group the candidate keypoints into multiple human poses (if any), utilizing the predicted guiding offsets. And we refer to this process as greedy offset-guided keypoint grouping (GOG). Moreover, we revisit the encoding-decoding method for the multi-person keypoint coordinates and reveal some important facts affecting accuracy. Experiments have demonstrated the obvious performance improvements brought by the introduced components. Our approach is comparable to the state of the art on the challenging COCO dataset under fair conditions. The source code and our pre-trained model are publicly available online.