 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Offset-Guided Keypoint Grouping for Human Pose Estimation
Jul 07, 2021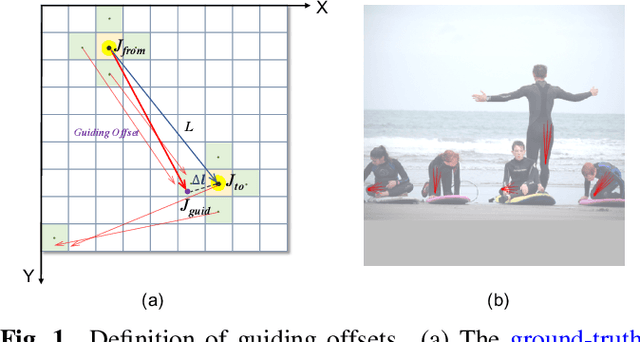


We propose a simple yet reliable bottom-up approach with a good trade-off between accuracy and efficiency for the problem of multi-person pose estimation. Given an image, we employ an Hourglass Network to infer all the keypoints from different persons indiscriminately as well as the guiding offsets connecting the adjacent keypoints belonging to the same persons. Then, we greedily group the candidate keypoints into multiple human poses (if any), utilizing the predicted guiding offsets. And we refer to this process as greedy offset-guided keypoint grouping (GOG). Moreover, we revisit the encoding-decoding method for the multi-person keypoint coordinates and reveal some important facts affecting accuracy. Experiments have demonstrated the obvious performance improvements brought by the introduced components. Our approach is comparable to the state of the art on the challenging COCO dataset under fair conditions. The source code and our pre-trained model are publicly available online.