 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of AI-Debater 2023: The Challenges of Argument Generation Tasks
Jul 24, 2024



In this paper we present the results of the AI-Debater 2023 Challenge held by the Chinese Conference on Affect Computing (CCAC 2023), and introduce the related datasets. We organize two tracks to handle the argumentative generation tasks in different scenarios, namely, Counter-Argument Generation (Track 1) and Claim-based Argument Generation (Track 2). Each track is equipped with its distinct dataset and baseline model respectively. In total, 32 competing teams register for the challenge, from which we received 11 successful submissions. In this paper, we will present the results of the challenge and a summary of the systems, highlighting commonalities and innovations among participating systems. Datasets and baseline models of the AI-Debater 2023 Challenge have been already released and can be accessed through the official website of the challenge.
An Efficient Method for Sample Adversarial Perturbations against Nonlinear Support Vector Machines
Jun 12, 2022



Adversarial perturbations have drawn great attentions in various machine learning models. In this paper, we investigate the sample adversarial perturbations for nonlinear support vector machines (SVMs). Due to the implicit form of the nonlinear functions mapping data to the feature space, it is difficult to obtain the explicit form of the adversarial perturbations. By exploring the special property of nonlinear SVMs, we transform the optimization problem of attacking nonlinear SVMs into a nonlinear KKT system. Such a system can be solved by various numerical methods. Numerical results show that our method is efficient in computing adversarial perturbations.
SSR-HEF: Crowd Counting with Multi-Scale Semantic Refining and Hard Example Focusing
Apr 15, 2022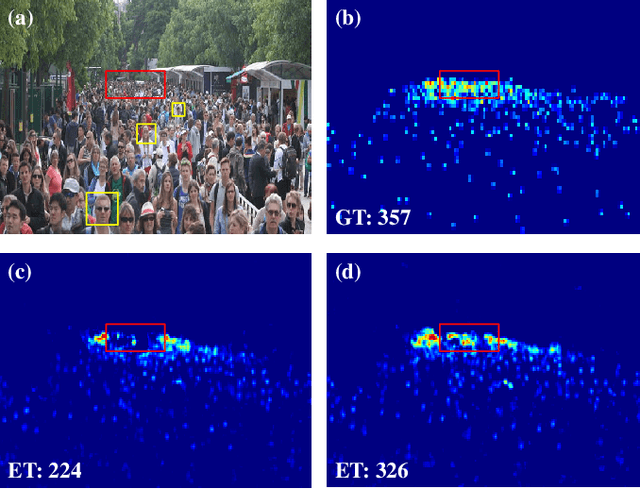
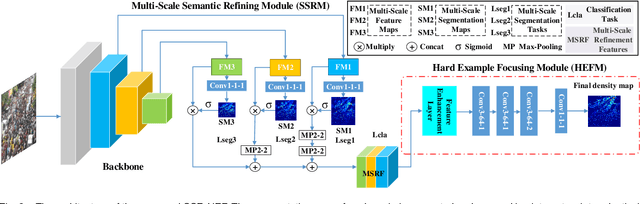
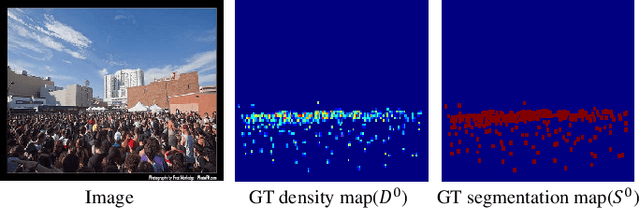
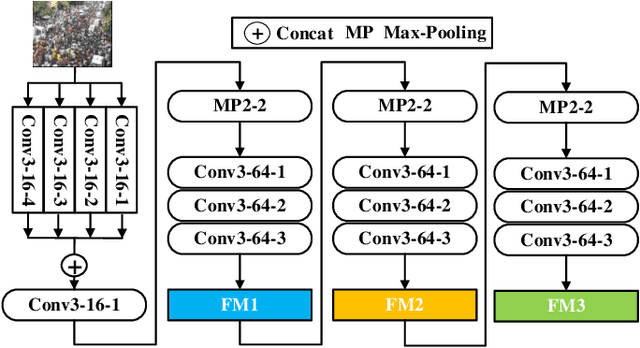
Crowd counting based on density maps is generally regarded as a regression task.Deep learning is used to learn the mapping between image content and crowd density distribution. Although great success has been achieved, some pedestrians far away from the camera are difficult to be detected. And the number of hard examples is often larger. Existing methods with simple Euclidean distance algorithm indiscriminately optimize the hard and easy examples so that the densities of hard examples are usually incorrectly predicted to be lower or even zero, which results in large counting errors. To address this problem, we are the first to propose the Hard Example Focusing(HEF) algorithm for the regression task of crowd counting. The HEF algorithm makes our model rapidly focus on hard examples by attenuating the contribution of easy examples.Then higher importance will be given to the hard examples with wrong estimations. Moreover, the scale variations in crowd scenes are large, and the scale annotations are labor-intensive and expensive. By proposing a multi-Scale Semantic Refining (SSR) strategy, lower layers of our model can break through the limitation of deep learning to capture semantic features of different scales to sufficiently deal with the scale variation. We perform extensive experiments on six benchmark datasets to verify the proposed method. Results indicate the superiority of our proposed method over the state-of-the-art methods. Moreover, our designed model is smaller and faster.
* Accepted by IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS
Crowd counting with crowd attention convolutional neural network
Apr 15, 2022



Crowd counting is a challenging problem due to the scene complexity and scale variation. Although deep learning has achieved great improvement in crowd counting, scene complexity affects the judgement of these methods and they usually regard some objects as people mistakenly; causing potentially enormous errors in the crowd counting result. To address the problem, we propose a novel end-to-end model called Crowd Attention Convolutional Neural Network (CAT-CNN). Our CAT-CNN can adaptively assess the importance of a human head at each pixel location by automatically encoding a confidence map. With the guidance of the confidence map, the position of human head in estimated density map gets more attention to encode the final density map, which can avoid enormous misjudgements effectively. The crowd count can be obtained by integrating the final density map. To encode a highly refined density map, the total crowd count of each image is classified in a designed classification task and we first explicitly map the prior of the population-level category to feature maps. To verify the efficiency of our proposed method, extensive experiments are conducted on three highly challenging datasets. Results establish the superiority of our method over many state-of-the-art methods.
* Accepted by Neurocomputing
Optimization Models and Interpretations for Three Types of Adversarial Perturbations against Support Vector Machines
Apr 07, 2022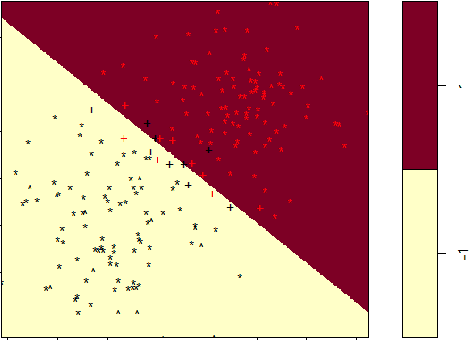
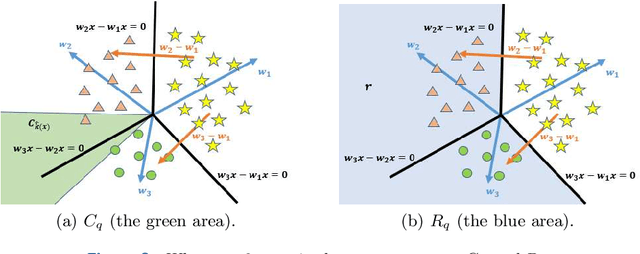

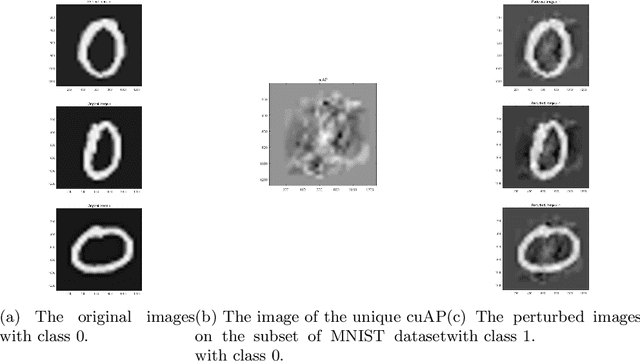
Adversarial perturbations have drawn great attentions in various deep neural networks. Most of them are computed by iterations and cannot be interpreted very well. In contrast, little attentions are paid to basic machine learning models such as support vector machines. In this paper, we investigate the optimization models and the interpretations for three types of adversarial perturbations against support vector machines, including sample-adversarial perturbations (sAP), class-universal adversarial perturbations (cuAP) as well as universal adversarial perturbations (uAP). For linear binary/multi classification support vector machines (SVMs), we derive the explicit solutions for sAP, cuAP and uAP (binary case), and approximate solution for uAP of multi-classification. We also obtain the upper bound of fooling rate for uAP. Such results not only increase the interpretability of the three adversarial perturbations, but also provide great convenience in computation since iterative process can be avoided. Numerical results show that our method is fast and effective in calculating three types of adversarial perturbations.
Simple Pose: Rethinking and Improving a Bottom-up Approach for Multi-Person Pose Estimation
Nov 24, 2019



We rethink a well-know bottom-up approach for multi-person pose estimation and propose an improved one. The improved approach surpasses the baseline significantly thanks to (1) an intuitional yet more sensible representation, which we refer to as body parts to encode the connection information between keypoints, (2) an improved stacked hourglass network with attention mechanisms, (3) a novel focal L2 loss which is dedicated to hard keypoint and keypoint association (body part) mining, and (4) a robust greedy keypoint assignment algorithm for grouping the detected keypoints into individual poses. Our approach not only works straightforwardly but also outperforms the baseline by about 15% in average precision and is comparable to the state of the art on the MS-COCO test-dev dataset. The code and pre-trained models are publicly available online.
MCNE: An End-to-End Framework for Learning Multiple Conditional Network Representations of Social Network
May 27, 2019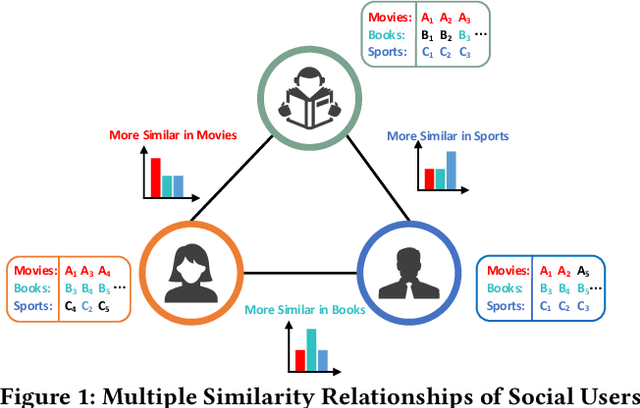
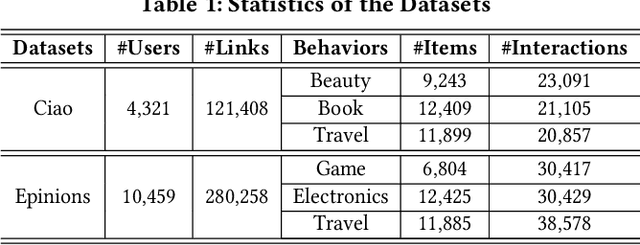
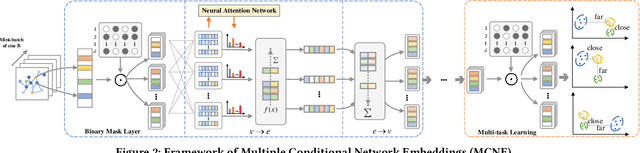
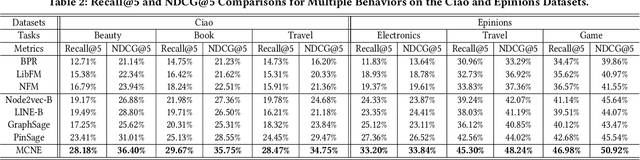
Recently, the Network Representation Learning (NRL) techniques, which represent graph structure via low-dimension vectors to support social-oriented application, have attracted wide attention. Though large efforts have been made, they may fail to describe the multiple aspects of similarity between social users, as only a single vector for one unique aspect has been represented for each node. To that end, in this paper, we propose a novel end-to-end framework named MCNE to learn multiple conditional network representations, so that various preferences for multiple behaviors could be fully captured. Specifically, we first design a binary mask layer to divide the single vector as conditional embeddings for multiple behaviors. Then, we introduce the attention network to model interaction relationship among multiple preferences, and further utilize the adapted message sending and receiving operation of graph neural network, so that multi-aspect preference information from high-order neighbors will be captured. Finally, we utilize Bayesian Personalized Ranking loss function to learn the preference similarity on each behavior, and jointly learn multiple conditional node embeddings via multi-task learning framework. Extensive experiments on public datasets validate that our MCNE framework could significantly outperform several state-of-the-art baselines, and further support the visualization and transfer learning tasks with excellent interpretability and robustness.