 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Subgraph Federated Learning with Differentiable Auxiliary Projections
May 29, 2025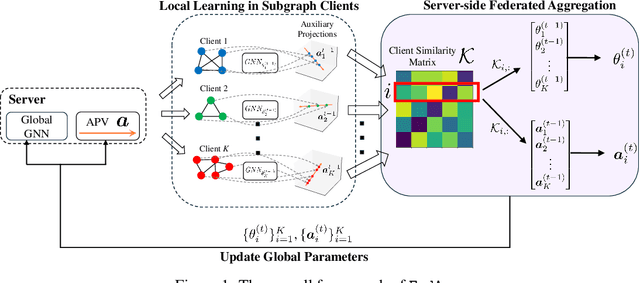
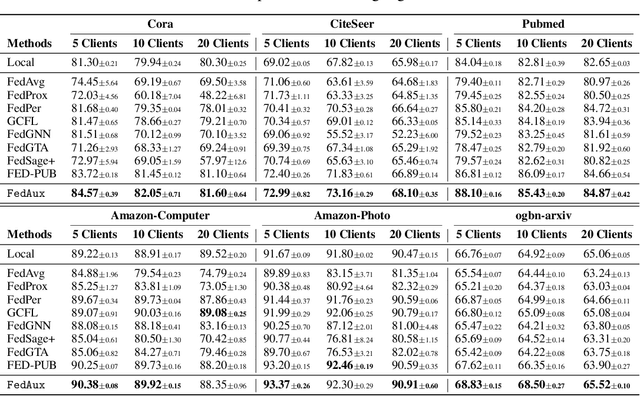
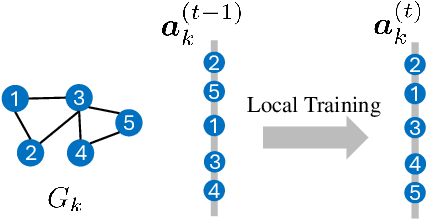
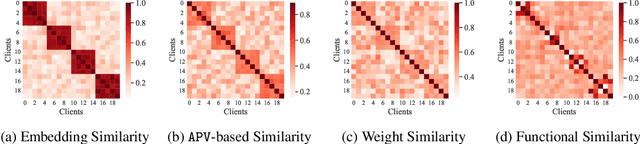
Federated learning (FL) on graph-structured data typically faces non-IID challenges, particularly in scenarios where each client holds a distinct subgraph sampled from a global graph. In this paper, we introduce Federated learning with Auxiliary projections (FedAux), a personalized subgraph FL framework that learns to align, compare, and aggregate heterogeneously distributed local models without sharing raw data or node embeddings. In FedAux, each client jointly trains (i) a local GNN and (ii) a learnable auxiliary projection vector (APV) that differentiably projects node embeddings onto a 1D space. A soft-sorting operation followed by a lightweight 1D convolution refines these embeddings in the ordered space, enabling the APV to effectively capture client-specific information. After local training, these APVs serve as compact signatures that the server uses to compute inter-client similarities and perform similarity-weighted parameter mixing, yielding personalized models while preserving cross-client knowledge transfer. Moreover, we provide rigorous theoretical analysis to establish the convergence and rationality of our design. Empirical evaluations across diverse graph benchmarks demonstrate that FedAux substantially outperforms existing baselines in both accuracy and personalization performance.
HouseLLM: LLM-Assisted Two-Phase Text-to-Floorplan Generation
Nov 20, 2024This paper proposes a two-phase text-to-floorplan generation method, which guides a Large Language Model (LLM) to generate an initial layout (Layout-LLM) and refines them into the final floorplans through conditional diffusion model. We incorporate a Chain-of-Thought approach to prompt the LLM based on user text specifications, enabling a more user-friendly and intuitive house layout design. This method allows users to describe their needs in natural language, enhancing accessibility and providing clearer geometric constraints. The final floorplans generated by Layout-LLM through conditional diffusion refinement are more accurate and better meet user requirements. Experimental results demonstrate that our approach achieves state-of-the-art performance across all metrics, validating its effectiveness in practical home design applications. We plan to release our code for public use.
MC-GPT: Empowering Vision-and-Language Navigation with Memory Map and Reasoning Chains
May 17, 2024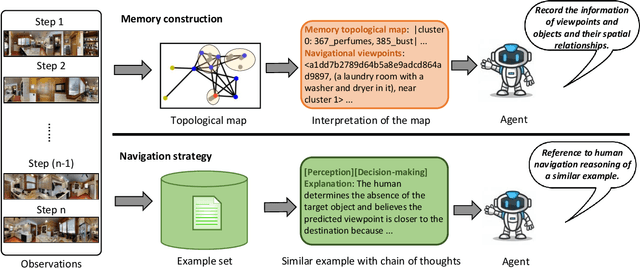
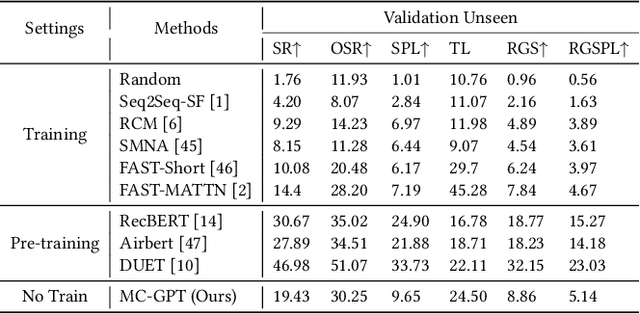
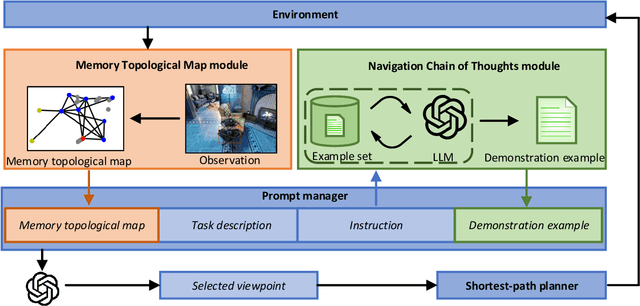
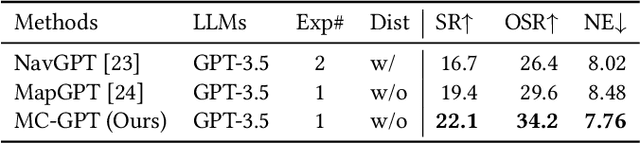
In the Vision-and-Language Navigation (VLN) task, the agent is required to navigate to a destination following a natural language instruction. While learning-based approaches have been a major solution to the task, they suffer from high training costs and lack of interpretability. Recently, Large Language Models (LLMs) have emerged as a promising tool for VLN due to their strong generalization capabilities. However, existing LLM-based methods face limitations in memory construction and diversity of navigation strategies. To address these challenges, we propose a suite of techniques. Firstly, we introduce a method to maintain a topological map that stores navigation history, retaining information about viewpoints, objects, and their spatial relationships. This map also serves as a global action space. Additionally, we present a Navigation Chain of Thoughts module, leveraging human navigation examples to enrich navigation strategy diversity. Finally, we establish a pipeline that integrates navigational memory and strategies with perception and action prediction modules. Experimental results on the REVERIE and R2R datasets show that our method effectively enhances the navigation ability of the LLM and improves the interpretability of navigation reasoning.
Vision-Dialog Navigation by Exploring Cross-modal Memory
Mar 15, 2020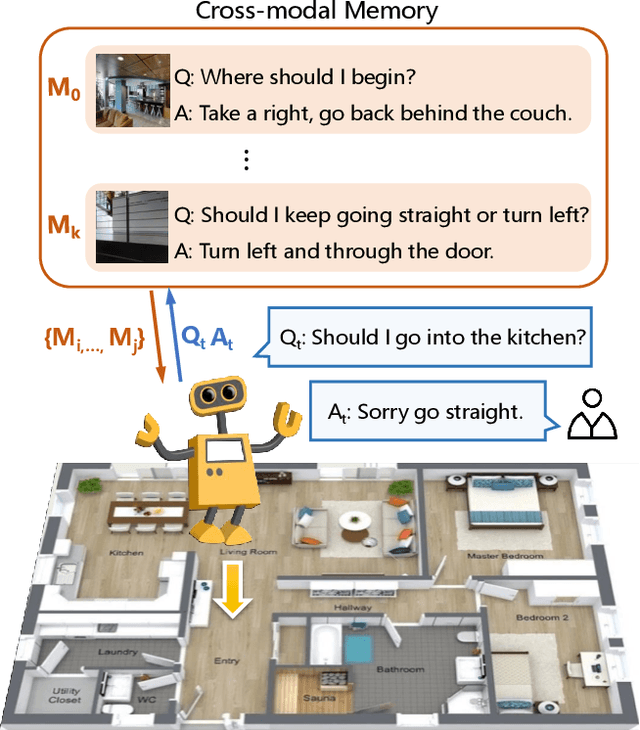
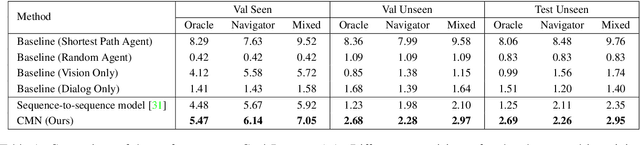
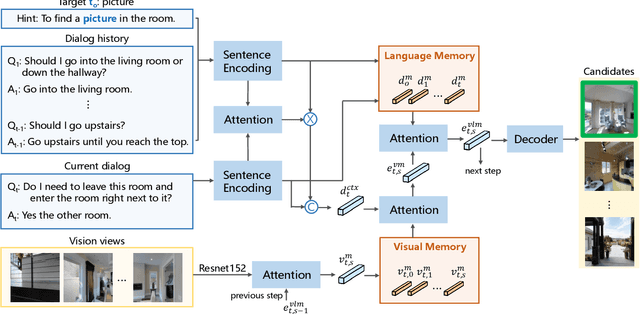
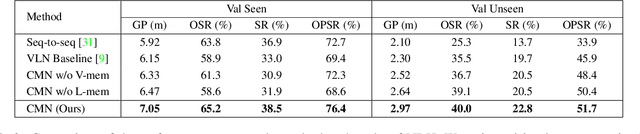
Vision-dialog navigation posed as a new holy-grail task in vision-language disciplinary targets at learning an agent endowed with the capability of constant conversation for help with natural language and navigating according to human responses. Besides the common challenges faced in visual language navigation, vision-dialog navigation also requires to handle well with the language intentions of a series of questions about the temporal context from dialogue history and co-reasoning both dialogs and visual scenes. In this paper, we propose the Cross-modal Memory Network (CMN) for remembering and understanding the rich information relevant to historical navigation actions. Our CMN consists of two memory modules, the language memory module (L-mem) and the visual memory module (V-mem). Specifically, L-mem learns latent relationships between the current language interaction and a dialog history by employing a multi-head attention mechanism. V-mem learns to associate the current visual views and the cross-modal memory about the previous navigation actions. The cross-modal memory is generated via a vision-to-language attention and a language-to-vision attention. Benefiting from the collaborative learning of the L-mem and the V-mem, our CMN is able to explore the memory about the decision making of historical navigation actions which is for the current step. Experiments on the CVDN dataset show that our CMN outperforms the previous state-of-the-art model by a significant margin on both seen and unseen environments.