 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPD: A Multi-sensory Interactive Perception Dataset for Embodied Intelligent Driving
Nov 08, 2024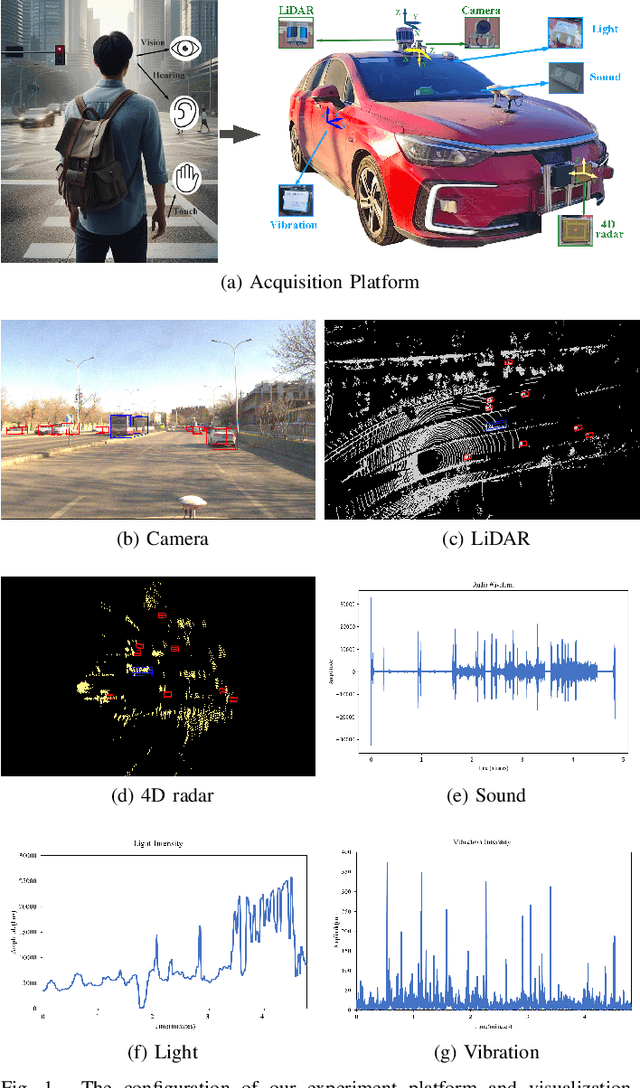
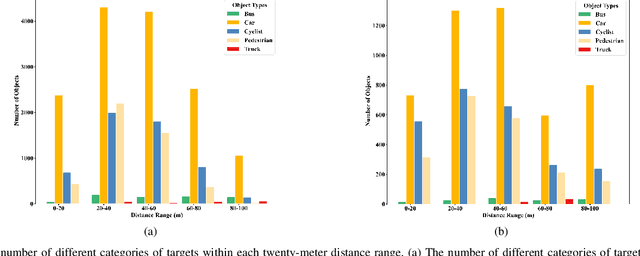
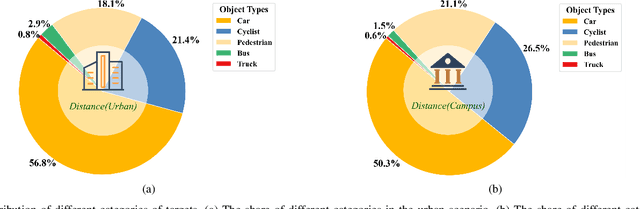
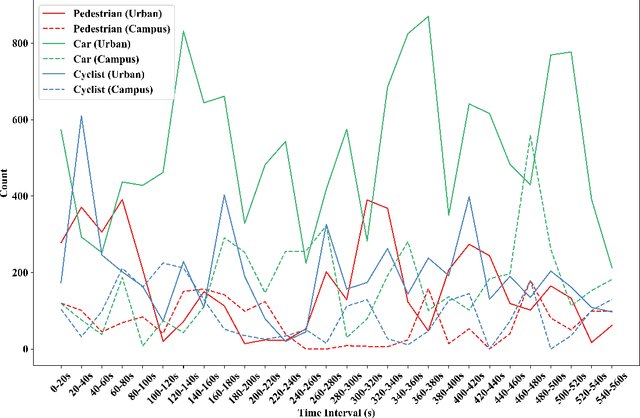
During the process of driving, humans usually rely on multiple senses to gather information and make decisions. Analogously, in order to achieve embodied intelligence in autonomous driving, it is essential to integrate multidimensional sensory information in order to facilitate interaction with the environment. However, the current multi-modal fusion sensing schemes often neglect these additional sensory inputs, hindering the realization of fully autonomous driving. This paper considers multi-sensory information and proposes a multi-modal interactive perception dataset named MIPD, enabling expanding the current autonomous driving algorithm framework, for supporting the research on embodied intelligent driving. In addition to the conventional camera, lidar, and 4D radar data, our dataset incorporates multiple sensor inputs including sound, light intensity, vibration intensity and vehicle speed to enrich the dataset comprehensiveness. Comprising 126 consecutive sequences, many exceeding twenty seconds, MIPD features over 8,500 meticulously synchronized and annotated frames. Moreover, it encompasses many challenging scenarios, covering various road and lighting conditions. The dataset has undergone thorough experimental validation, producing valuable insights for the exploration of next-generation autonomous driving frameworks.
Unified End-to-End V2X Cooperative Autonomous Driving
May 07, 2024

V2X cooperation, through the integration of sensor data from both vehicles and infrastructure, is considered a pivotal approach to advancing autonomous driving technology. Current research primarily focuses on enhancing perception accuracy, often overlooking the systematic improvement of accident prediction accuracy through end-to-end learning, leading to insufficient attention to the safety issues of autonomous driving. To address this challenge, this paper introduces the UniE2EV2X framework, a V2X-integrated end-to-end autonomous driving system that consolidates key driving modules within a unified network. The framework employs a deformable attention-based data fusion strategy, effectively facilitating cooperation between vehicles and infrastructure. The main advantages include: 1) significantly enhancing agents' perception and motion prediction capabilities, thereby improving the accuracy of accident predictions; 2) ensuring high reliability in the data fusion process; 3) superior end-to-end perception compared to modular approaches. Furthermore, We implement the UniE2EV2X framework on the challenging DeepAccident, a simulation dataset designed for V2X cooperative driving.
Self-Supervised Depth Completion Guided by 3D Perception and Geometry Consistency
Dec 23, 2023
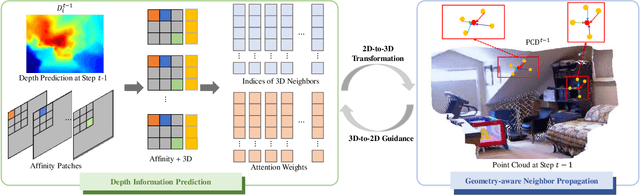


Depth completion, aiming to predict dense depth maps from sparse depth measurements, plays a crucial role in many computer vision related applications. Deep learning approaches have demonstrated overwhelming success in this task. However, high-precision depth completion without relying on the ground-truth data, which are usually costly, still remains challenging. The reason lies on the ignorance of 3D structural information in most previous unsupervised solutions, causing inaccurate spatial propagation and mixed-depth problems. To alleviate the above challenges, this paper explores the utilization of 3D perceptual features and multi-view geometry consistency to devise a high-precision self-supervised depth completion method. Firstly, a 3D perceptual spatial propagation algorithm is constructed with a point cloud representation and an attention weighting mechanism to capture more reasonable and favorable neighboring features during the iterative depth propagation process. Secondly, the multi-view geometric constraints between adjacent views are explicitly incorporated to guide the optimization of the whole depth completion model in a self-supervised manner. Extensive experiments on benchmark datasets of NYU-Depthv2 and VOID demonstrate that the proposed model achieves the state-of-the-art depth completion performance compared with other unsupervised methods, and competitive performance compared with previous supervised methods.
Neural-Network-Driven Method for Optimal Path Planning via High-Accuracy Region Prediction
Aug 15, 2023Sampling-based path planning algorithms suffer from heavy reliance on uniform sampling, which accounts for unreliable and time-consuming performance, especially in complex environments. Recently, neural-network-driven methods predict regions as sampling domains to realize a non-uniform sampling and reduce calculation time. However, the accuracy of region prediction hinders further improvement. We propose a sampling-based algorithm, abbreviated to Region Prediction Neural Network RRT* (RPNN-RRT*), to rapidly obtain the optimal path based on a high-accuracy region prediction. First, we implement a region prediction neural network (RPNN), to predict accurate regions for the RPNN-RRT*. A full-layer channel-wise attention module is employed to enhance the feature fusion in the concatenation between the encoder and decoder. Moreover, a three-level hierarchy loss is designed to learn the pixel-wise, map-wise, and patch-wise features. A dataset, named Complex Environment Motion Planning, is established to test the performance in complex environments. Ablation studies and test results show that a high accuracy of 89.13% is achieved by the RPNN for region prediction, compared with other region prediction models. In addition, the RPNN-RRT* performs in different complex scenarios, demonstrating significant and reliable superiority in terms of the calculation time, sampling efficiency, and success rate for optimal path planning.
Parallel Medical Imaging: A New Data-Knowledge-Driven Evolutionary Framework for Medical Image Analysis
Mar 12, 2019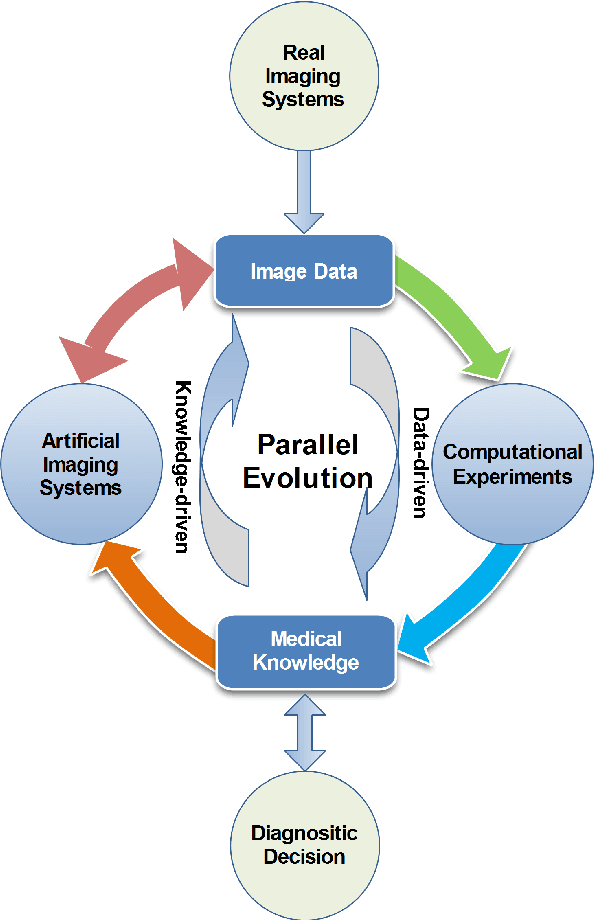
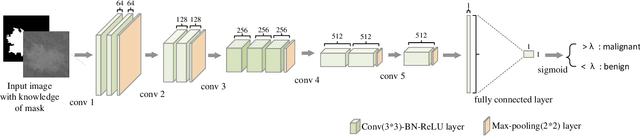
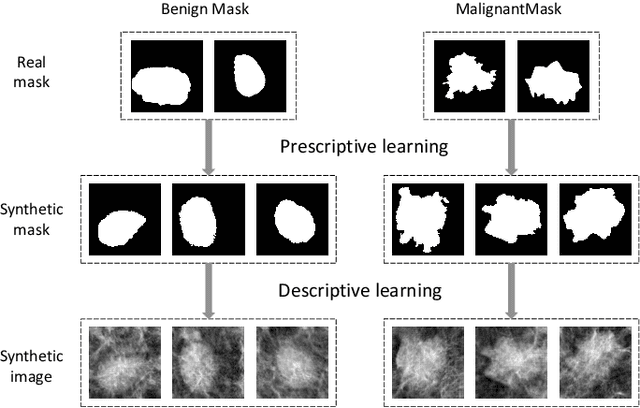
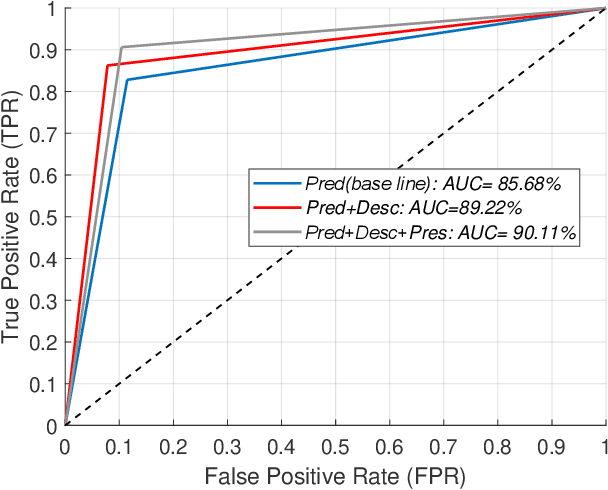
There has been much progress in data-driven artificial intelligence technology for medical image analysis in last decades. However, it still remains a challenge due to its distinctive complexity of acquiring and annotating image data, extracting medical domain knowledge, and explaining the diagnostic decision for medical image analysis. In this paper, we propose a data-knowledge-driven evolutionary framework termed as Parallel Medical Imaging (PMI) for medical image analysis based on the methodology of interactive ACP-based parallel intelligence. In the PMI framework, computational experiments with predictive learning in a data-driven way are conducted to extract medical knowledge for diagnostic decision support. Artificial imaging systems are introduced to select and prescriptively generate medical image data in a knowledge-driven way to utilize medical domain knowledge. Through the parallel evolutionary optimization, our proposed PMI framework can boost the generalization ability and alleviate the limitation of medical interpretation for diagnostic decision. A GANs-based PMI framework for case studies of mammogram analysis is demonstrated in this work.