 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogSAGE: Self-evolving Analog Design Multi-Agents with Stratified Memory and Grounded Experience
Dec 27, 2025Analog circuit design remains a knowledge- and experience-intensive process that relies heavily on human intuition for topology generation and device parameter tuning. Existing LLM-based approaches typically depend on prompt-driven netlist generation or predefined topology templates, limiting their ability to satisfy complex specification requirements. We propose AnalogSAGE, an open-source self-evolving multi-agent framework that coordinates three-stage agent explorations through four stratified memory layers, enabling iterative refinement with simulation-grounded feedback. To support reproducibility and generality, we release the source code. Our benchmark spans ten specification-driven operational amplifier design problems of varying difficulty, enabling quantitative and cross-task comparison under identical conditions. Evaluated under the open-source SKY130 PDK with ngspice, AnalogSAGE achieves a 10$\times$ overall pass rate, a 48$\times$ Pass@1, and a 4$\times$ reduction in parameter search space compared with existing frameworks, demonstrating that stratified memory and grounded reasoning substantially enhance the reliability and autonomy of analog design automation in practice.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
LLM4SecHW: Leveraging Domain Specific Large Language Model for Hardware Debugging
Jan 28, 2024


This paper presents LLM4SecHW, a novel framework for hardware debugging that leverages domain specific Large Language Model (LLM). Despite the success of LLMs in automating various software development tasks, their application in the hardware security domain has been limited due to the constraints of commercial LLMs and the scarcity of domain specific data. To address these challenges, we propose a unique approach to compile a dataset of open source hardware design defects and their remediation steps, utilizing version control data. This dataset provides a substantial foundation for training machine learning models for hardware. LLM4SecHW employs fine tuning of medium sized LLMs based on this dataset, enabling the identification and rectification of bugs in hardware designs. This pioneering approach offers a reference workflow for the application of fine tuning domain specific LLMs in other research areas. We evaluate the performance of our proposed system on various open source hardware designs, demonstrating its efficacy in accurately identifying and correcting defects. Our work brings a new perspective on automating the quality control process in hardware design.
* 6 pages. 1 figure
Hardware Phi-1.5B: A Large Language Model Encodes Hardware Domain Specific Knowledge
Jan 27, 2024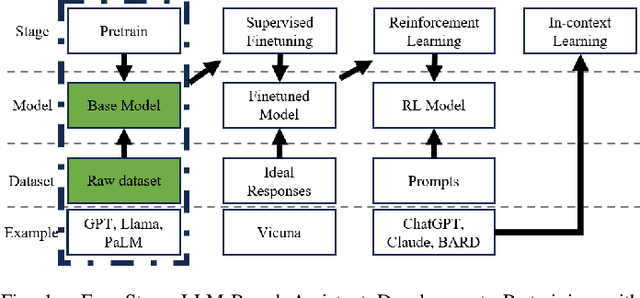

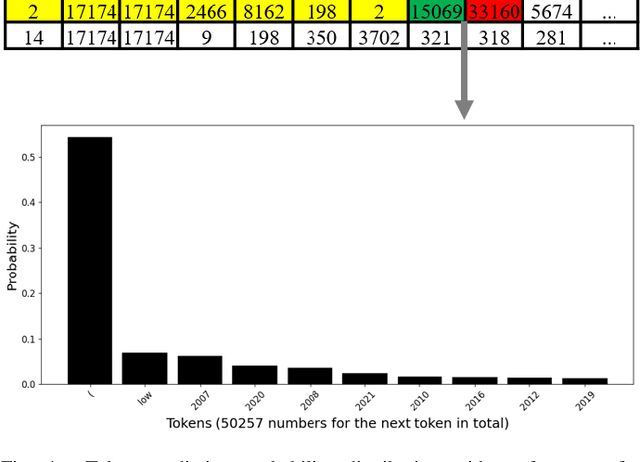
In the rapidly evolving semiconductor industry, where research, design, verification, and manufacturing are intricately linked, the potential of Large Language Models to revolutionize hardware design and security verification is immense. The primary challenge, however, lies in the complexity of hardware specific issues that are not adequately addressed by the natural language or software code knowledge typically acquired during the pretraining stage. Additionally, the scarcity of datasets specific to the hardware domain poses a significant hurdle in developing a foundational model. Addressing these challenges, this paper introduces Hardware Phi 1.5B, an innovative large language model specifically tailored for the hardware domain of the semiconductor industry. We have developed a specialized, tiered dataset comprising small, medium, and large subsets and focused our efforts on pretraining using the medium dataset. This approach harnesses the compact yet efficient architecture of the Phi 1.5B model. The creation of this first pretrained, hardware domain specific large language model marks a significant advancement, offering improved performance in hardware design and verification tasks and illustrating a promising path forward for AI applications in the semiconductor sector.
* 6 pages, 6 figures
Contour Loss for Instance Segmentation via k-step Distance Transformation Image
Feb 22, 2021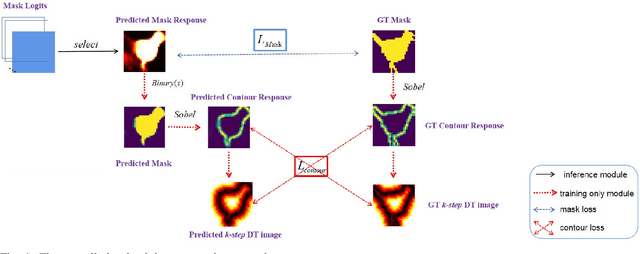
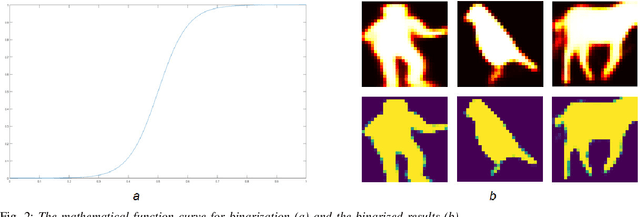


Instance segmentation aims to locate targets in the image and segment each target area at pixel level, which is one of the most important tasks in computer vision. Mask R-CNN is a classic method of instance segmentation, but we find that its predicted masks are unclear and inaccurate near contours. To cope with this problem, we draw on the idea of contour matching based on distance transformation image and propose a novel loss function, called contour loss. Contour loss is designed to specifically optimize the contour parts of the predicted masks, thus can assure more accurate instance segmentation. In order to make the proposed contour loss to be jointly trained under modern neural network frameworks, we design a differentiable k-step distance transformation image calculation module, which can approximately compute truncated distance transformation images of the predicted mask and corresponding ground-truth mask online. The proposed contour loss can be integrated into existing instance segmentation methods such as Mask R-CNN, and combined with their original loss functions without modification of the inference network structures, thus has strong versatility. Experimental results on COCO show that contour loss is effective, which can further improve instance segmentation performances.