 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
ExpLang: Improved Exploration and Exploitation in LLM Reasoning with On-Policy Thinking Language Selection
Feb 25, 2026Current large reasoning models (LRMs) have shown strong ability on challenging tasks after reinforcement learning (RL) based post-training. However, previous work mainly focuses on English reasoning in expectation of the strongest performance, despite the demonstrated potential advantage of multilingual thinking, as well as the requirement for native thinking traces by global users. In this paper, we propose ExpLang, a novel LLM post-training pipeline that enables on-policy thinking language selection to improve exploration and exploitation during RL with the use of multiple languages. The results show that our method steadily outperforms English-only training with the same training budget, while showing high thinking language compliance for both seen and unseen languages. Analysis shows that, by enabling on-policy thinking language selection as an action during RL, ExpLang effectively extends the RL exploration space with diversified language preference and improves the RL exploitation outcome with leveraged non-English advantage. The method is orthogonal to most RL algorithms and opens up a new perspective on using multilinguality to improve LRMs.
LLM4SecHW: Leveraging Domain Specific Large Language Model for Hardware Debugging
Jan 28, 2024


This paper presents LLM4SecHW, a novel framework for hardware debugging that leverages domain specific Large Language Model (LLM). Despite the success of LLMs in automating various software development tasks, their application in the hardware security domain has been limited due to the constraints of commercial LLMs and the scarcity of domain specific data. To address these challenges, we propose a unique approach to compile a dataset of open source hardware design defects and their remediation steps, utilizing version control data. This dataset provides a substantial foundation for training machine learning models for hardware. LLM4SecHW employs fine tuning of medium sized LLMs based on this dataset, enabling the identification and rectification of bugs in hardware designs. This pioneering approach offers a reference workflow for the application of fine tuning domain specific LLMs in other research areas. We evaluate the performance of our proposed system on various open source hardware designs, demonstrating its efficacy in accurately identifying and correcting defects. Our work brings a new perspective on automating the quality control process in hardware design.
* 6 pages. 1 figure
Hardware Phi-1.5B: A Large Language Model Encodes Hardware Domain Specific Knowledge
Jan 27, 2024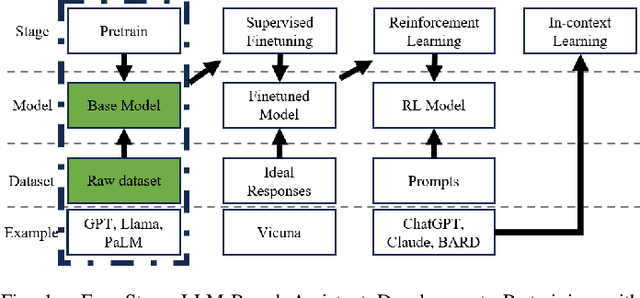

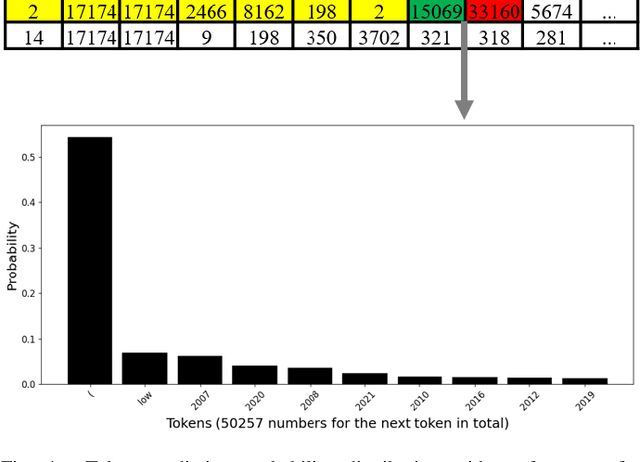
In the rapidly evolving semiconductor industry, where research, design, verification, and manufacturing are intricately linked, the potential of Large Language Models to revolutionize hardware design and security verification is immense. The primary challenge, however, lies in the complexity of hardware specific issues that are not adequately addressed by the natural language or software code knowledge typically acquired during the pretraining stage. Additionally, the scarcity of datasets specific to the hardware domain poses a significant hurdle in developing a foundational model. Addressing these challenges, this paper introduces Hardware Phi 1.5B, an innovative large language model specifically tailored for the hardware domain of the semiconductor industry. We have developed a specialized, tiered dataset comprising small, medium, and large subsets and focused our efforts on pretraining using the medium dataset. This approach harnesses the compact yet efficient architecture of the Phi 1.5B model. The creation of this first pretrained, hardware domain specific large language model marks a significant advancement, offering improved performance in hardware design and verification tasks and illustrating a promising path forward for AI applications in the semiconductor sector.
* 6 pages, 6 figures