 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeJOT: An Intelligent Job Cost Orchestration Solution for Databricks Platform
Dec 20, 2025With the rapid advancements in big data technologies, the Databricks platform has become a cornerstone for enterprises and research institutions, offering high computational efficiency and a robust ecosystem. However, managing the escalating operational costs associated with job execution remains a critical challenge. Existing solutions rely on static configurations or reactive adjustments, which fail to adapt to the dynamic nature of workloads. To address this, we introduce LeJOT, an intelligent job cost orchestration framework that leverages machine learning for execution time prediction and a solver-based optimization model for real-time resource allocation. Unlike conventional scheduling techniques, LeJOT proactively predicts workload demands, dynamically allocates computing resources, and minimizes costs while ensuring performance requirements are met. Experimental results on real-world Databricks workloads demonstrate that LeJOT achieves an average 20% reduction in cloud computing costs within a minute-level scheduling timeframe, outperforming traditional static allocation strategies. Our approach provides a scalable and adaptive solution for cost-efficient job scheduling in Data Lakehouse environments.
FFCG: Effective and Fast Family Column Generation for Solving Large-Scale Linear Program
Dec 26, 2024



Column Generation (CG) is an effective and iterative algorithm to solve large-scale linear programs (LP). During each CG iteration, new columns are added to improve the solution of the LP. Typically, CG greedily selects one column with the most negative reduced cost, which can be improved by adding more columns at once. However, selecting all columns with negative reduced costs would lead to the addition of redundant columns that do not improve the objective value. Therefore, selecting the appropriate columns to add is still an open problem and previous machine-learning-based approaches for CG only add a constant quantity of columns per iteration due to the state-space explosion problem. To address this, we propose Fast Family Column Generation (FFCG) -- a novel reinforcement-learning-based CG that selects a variable number of columns as needed in an iteration. Specifically, we formulate the column selection problem in CG as an MDP and design a reward metric that balances both the convergence speed and the number of redundant columns. In our experiments, FFCG converges faster on the common benchmarks and reduces the number of CG iterations by 77.1% for Cutting Stock Problem (CSP) and 84.8% for Vehicle Routing Problem with Time Windows (VRPTW), and a 71.4% reduction in computing time for CSP and 84.0% for VRPTW on average compared to several state-of-the-art baselines.
Hardware Phi-1.5B: A Large Language Model Encodes Hardware Domain Specific Knowledge
Jan 27, 2024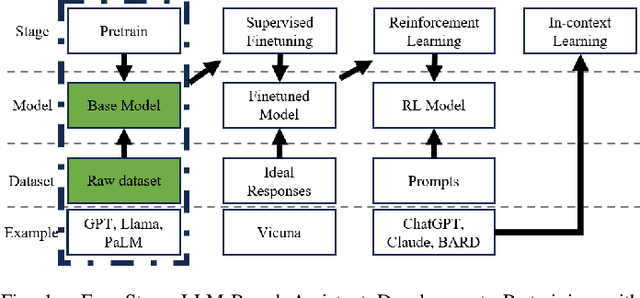

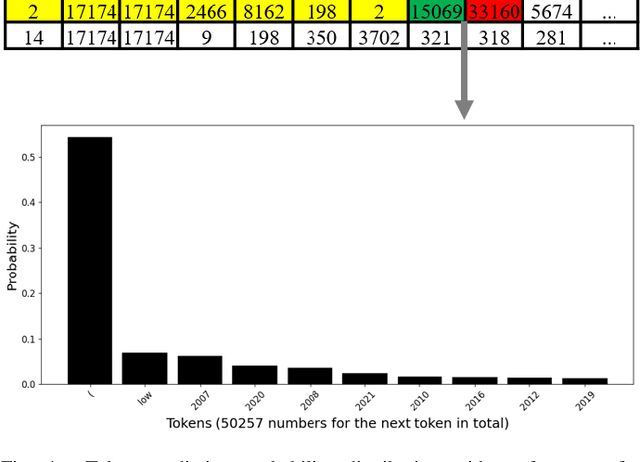
In the rapidly evolving semiconductor industry, where research, design, verification, and manufacturing are intricately linked, the potential of Large Language Models to revolutionize hardware design and security verification is immense. The primary challenge, however, lies in the complexity of hardware specific issues that are not adequately addressed by the natural language or software code knowledge typically acquired during the pretraining stage. Additionally, the scarcity of datasets specific to the hardware domain poses a significant hurdle in developing a foundational model. Addressing these challenges, this paper introduces Hardware Phi 1.5B, an innovative large language model specifically tailored for the hardware domain of the semiconductor industry. We have developed a specialized, tiered dataset comprising small, medium, and large subsets and focused our efforts on pretraining using the medium dataset. This approach harnesses the compact yet efficient architecture of the Phi 1.5B model. The creation of this first pretrained, hardware domain specific large language model marks a significant advancement, offering improved performance in hardware design and verification tasks and illustrating a promising path forward for AI applications in the semiconductor sector.
* 6 pages, 6 figures