 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Bad Molecules: Are MLLMs Ready for Structure-Level Molecular Detoxification?
Jun 12, 2025Toxicity remains a leading cause of early-stage drug development failure. Despite advances in molecular design and property prediction, the task of molecular toxicity repair - generating structurally valid molecular alternatives with reduced toxicity - has not yet been systematically defined or benchmarked. To fill this gap, we introduce ToxiMol, the first benchmark task for general-purpose Multimodal Large Language Models (MLLMs) focused on molecular toxicity repair. We construct a standardized dataset covering 11 primary tasks and 560 representative toxic molecules spanning diverse mechanisms and granularities. We design a prompt annotation pipeline with mechanism-aware and task-adaptive capabilities, informed by expert toxicological knowledge. In parallel, we propose an automated evaluation framework, ToxiEval, which integrates toxicity endpoint prediction, synthetic accessibility, drug-likeness, and structural similarity into a high-throughput evaluation chain for repair success. We systematically assess nearly 30 mainstream general-purpose MLLMs and design multiple ablation studies to analyze key factors such as evaluation criteria, candidate diversity, and failure attribution. Experimental results show that although current MLLMs still face significant challenges on this task, they begin to demonstrate promising capabilities in toxicity understanding, semantic constraint adherence, and structure-aware molecule editing.
LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
May 06, 2025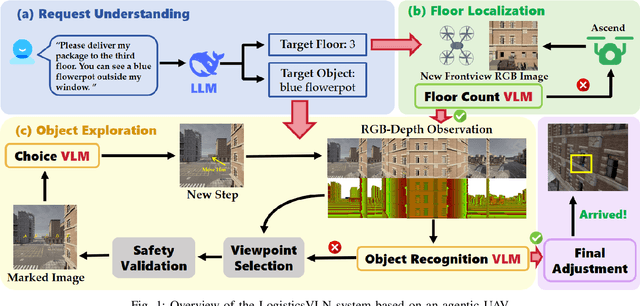
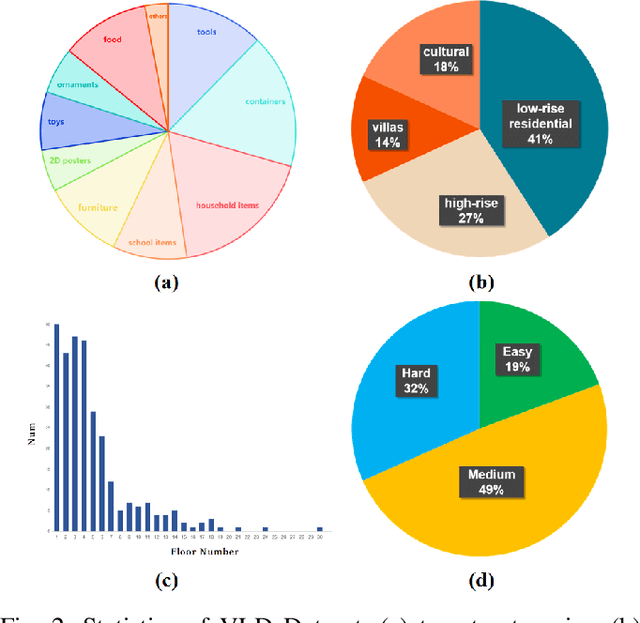

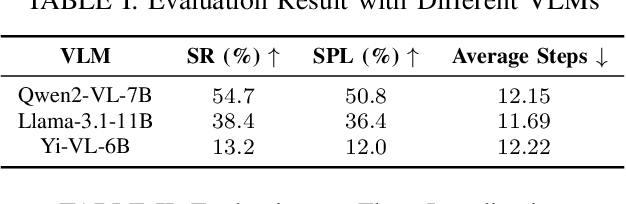
The growing demand for intelligent logistics, particularly fine-grained terminal delivery, underscores the need for autonomous UAV (Unmanned Aerial Vehicle)-based delivery systems. However, most existing last-mile delivery studies rely on ground robots, while current UAV-based Vision-Language Navigation (VLN) tasks primarily focus on coarse-grained, long-range goals, making them unsuitable for precise terminal delivery. To bridge this gap, we propose LogisticsVLN, a scalable aerial delivery system built on multimodal large language models (MLLMs) for autonomous terminal delivery. LogisticsVLN integrates lightweight Large Language Models (LLMs) and Visual-Language Models (VLMs) in a modular pipeline for request understanding, floor localization, object detection, and action-decision making. To support research and evaluation in this new setting, we construct the Vision-Language Delivery (VLD) dataset within the CARLA simulator. Experimental results on the VLD dataset showcase the feasibility of the LogisticsVLN system. In addition, we conduct subtask-level evaluations of each module of our system, offering valuable insights for improving the robustness and real-world deployment of foundation model-based vision-language delivery systems.
CoordField: Coordination Field for Agentic UAV Task Allocation In Low-altitude Urban Scenarios
Apr 30, 2025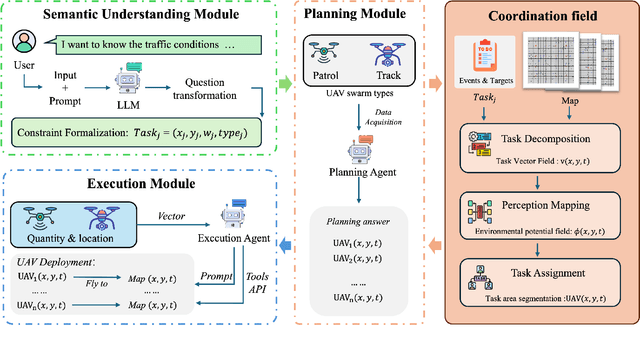
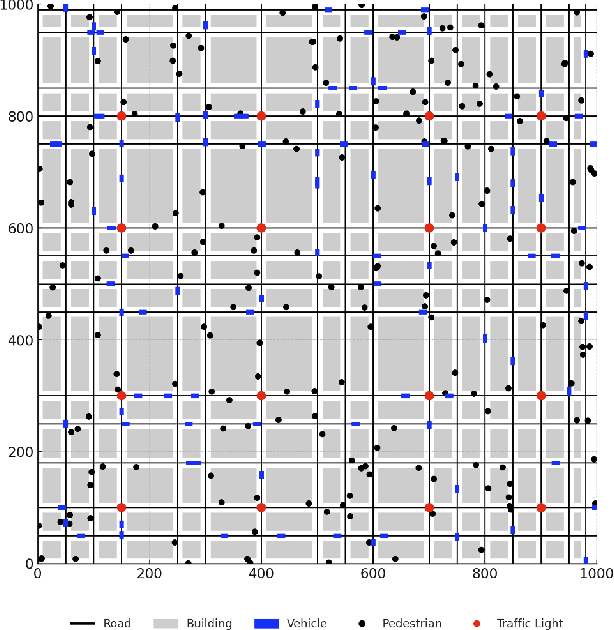
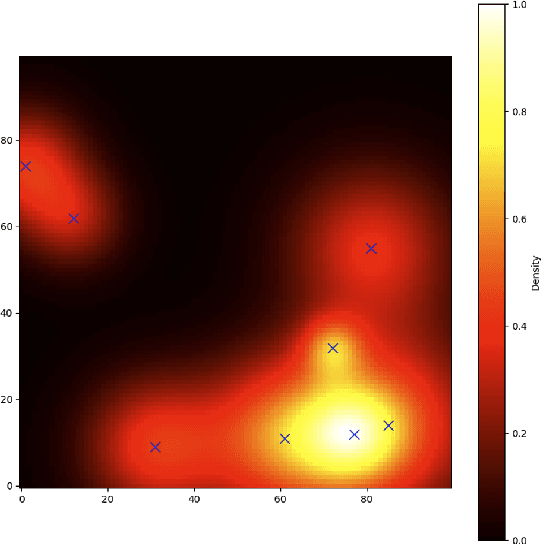
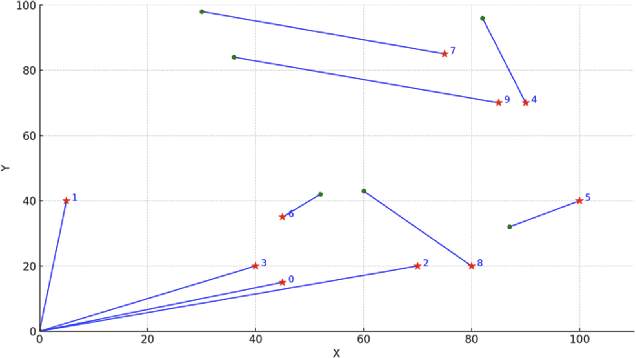
With the increasing demand for heterogeneous Unmanned Aerial Vehicle (UAV) swarms to perform complex tasks in urban environments, system design now faces major challenges, including efficient semantic understanding, flexible task planning, and the ability to dynamically adjust coordination strategies in response to evolving environmental conditions and continuously changing task requirements. To address the limitations of existing approaches, this paper proposes coordination field agentic system for coordinating heterogeneous UAV swarms in complex urban scenarios. In this system, large language models (LLMs) is responsible for interpreting high-level human instructions and converting them into executable commands for the UAV swarms, such as patrol and target tracking. Subsequently, a Coordination field mechanism is proposed to guide UAV motion and task selection, enabling decentralized and adaptive allocation of emergent tasks. A total of 50 rounds of comparative testing were conducted across different models in a 2D simulation space to evaluate their performance. Experimental results demonstrate that the proposed system achieves superior performance in terms of task coverage, response time, and adaptability to dynamic changes.
AirVista-II: An Agentic System for Embodied UAVs Toward Dynamic Scene Semantic Understanding
Apr 13, 2025Unmanned Aerial Vehicles (UAVs) are increasingly important in dynamic environments such as logistics transportation and disaster response. However, current tasks often rely on human operators to monitor aerial videos and make operational decisions. This mode of human-machine collaboration suffers from significant limitations in efficiency and adaptability. In this paper, we present AirVista-II -- an end-to-end agentic system for embodied UAVs, designed to enable general-purpose semantic understanding and reasoning in dynamic scenes. The system integrates agent-based task identification and scheduling, multimodal perception mechanisms, and differentiated keyframe extraction strategies tailored for various temporal scenarios, enabling the efficient capture of critical scene information. Experimental results demonstrate that the proposed system achieves high-quality semantic understanding across diverse UAV-based dynamic scenarios under a zero-shot setting.
UAVs Meet LLMs: Overviews and Perspectives Toward Agentic Low-Altitude Mobility
Jan 04, 2025Low-altitude mobility, exemplified by unmanned aerial vehicles (UAVs), has introduced transformative advancements across various domains, like transportation, logistics, and agriculture. Leveraging flexible perspectives and rapid maneuverability, UAVs extend traditional systems' perception and action capabilities, garnering widespread attention from academia and industry. However, current UAV operations primarily depend on human control, with only limited autonomy in simple scenarios, and lack the intelligence and adaptability needed for more complex environments and tasks. The emergence of large language models (LLMs) demonstrates remarkable problem-solving and generalization capabilities, offering a promising pathway for advancing UAV intelligence. This paper explores the integration of LLMs and UAVs, beginning with an overview of UAV systems' fundamental components and functionalities, followed by an overview of the state-of-the-art in LLM technology. Subsequently, it systematically highlights the multimodal data resources available for UAVs, which provide critical support for training and evaluation. Furthermore, it categorizes and analyzes key tasks and application scenarios where UAVs and LLMs converge. Finally, a reference roadmap towards agentic UAVs is proposed, aiming to enable UAVs to achieve agentic intelligence through autonomous perception, memory, reasoning, and tool utilization. Related resources are available at https://github.com/Hub-Tian/UAVs_Meet_LLMs.
Integrating Medical Imaging and Clinical Reports Using Multimodal Deep Learning for Advanced Disease Analysis
May 23, 2024

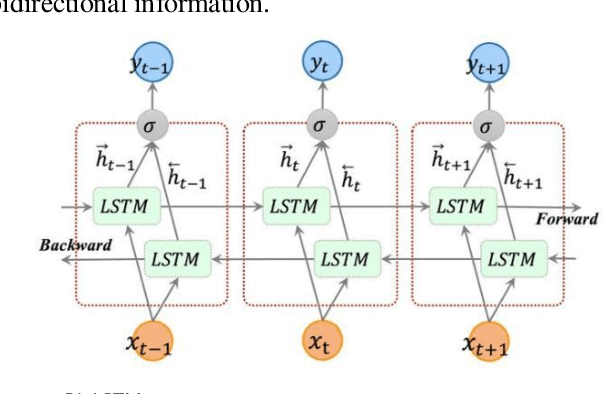

In this paper, an innovative multi-modal deep learning model is proposed to deeply integrate heterogeneous information from medical images and clinical reports. First, for medical images, convolutional neural networks were used to extract high-dimensional features and capture key visual information such as focal details, texture and spatial distribution. Secondly, for clinical report text, a two-way long and short-term memory network combined with an attention mechanism is used for deep semantic understanding, and key statements related to the disease are accurately captured. The two features interact and integrate effectively through the designed multi-modal fusion layer to realize the joint representation learning of image and text. In the empirical study, we selected a large medical image database covering a variety of diseases, combined with corresponding clinical reports for model training and validation. The proposed multimodal deep learning model demonstrated substantial superiority in the realms of disease classification, lesion localization, and clinical description generation, as evidenced by the experimental results.