 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Quality: Unlocking Diversity in Ad Headline Generation with Large Language Models
Aug 26, 2025
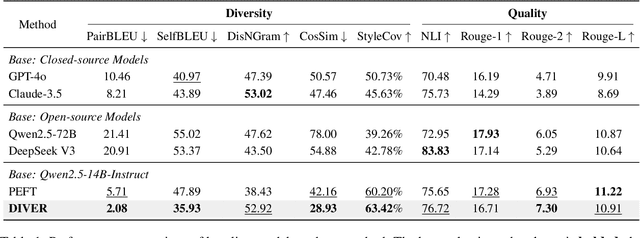
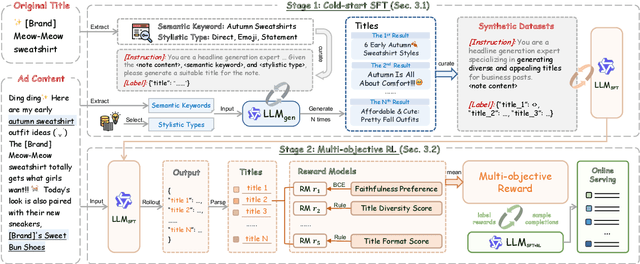
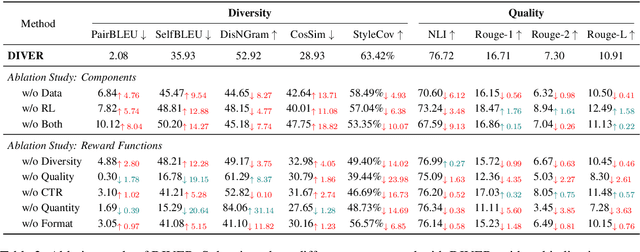
The generation of ad headlines plays a vital role in modern advertising, where both quality and diversity are essential to engage a broad range of audience segments. Current approaches primarily optimize language models for headline quality or click-through rates (CTR), often overlooking the need for diversity and resulting in homogeneous outputs. To address this limitation, we propose DIVER, a novel framework based on large language models (LLMs) that are jointly optimized for both diversity and quality. We first design a semantic- and stylistic-aware data generation pipeline that automatically produces high-quality training pairs with ad content and multiple diverse headlines. To achieve the goal of generating high-quality and diversified ad headlines within a single forward pass, we propose a multi-stage multi-objective optimization framework with supervised fine-tuning (SFT) and reinforcement learning (RL). Experiments on real-world industrial datasets demonstrate that DIVER effectively balances quality and diversity. Deployed on a large-scale content-sharing platform serving hundreds of millions of users, our framework improves advertiser value (ADVV) and CTR by 4.0% and 1.4%.
InternBootcamp Technical Report: Boosting LLM Reasoning with Verifiable Task Scaling
Aug 12, 2025



Large language models (LLMs) have revolutionized artificial intelligence by enabling complex reasoning capabilities. While recent advancements in reinforcement learning (RL) have primarily focused on domain-specific reasoning tasks (e.g., mathematics or code generation), real-world reasoning scenarios often require models to handle diverse and complex environments that narrow-domain benchmarks cannot fully capture. To address this gap, we present InternBootcamp, an open-source framework comprising 1000+ domain-diverse task environments specifically designed for LLM reasoning research. Our codebase offers two key functionalities: (1) automated generation of unlimited training/testing cases with configurable difficulty levels, and (2) integrated verification modules for objective response evaluation. These features make InternBootcamp fundamental infrastructure for RL-based model optimization, synthetic data generation, and model evaluation. Although manually developing such a framework with enormous task coverage is extremely cumbersome, we accelerate the development procedure through an automated agent workflow supplemented by manual validation protocols, which enables the task scope to expand rapidly. % With these bootcamps, we further establish Bootcamp-EVAL, an automatically generated benchmark for comprehensive performance assessment. Evaluation reveals that frontier models still underperform in many reasoning tasks, while training with InternBootcamp provides an effective way to significantly improve performance, leading to our 32B model that achieves state-of-the-art results on Bootcamp-EVAL and excels on other established benchmarks. In particular, we validate that consistent performance gains come from including more training tasks, namely \textbf{task scaling}, over two orders of magnitude, offering a promising route towards capable reasoning generalist.
Code-Driven Inductive Synthesis: Enhancing Reasoning Abilities of Large Language Models with Sequences
Mar 17, 2025
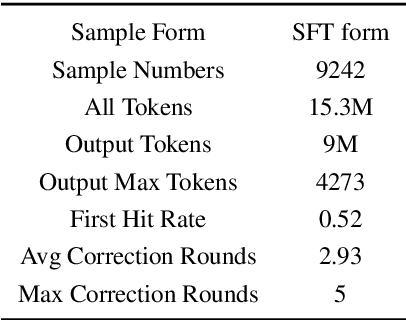
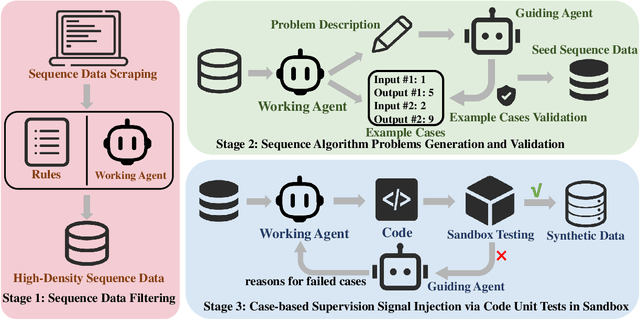

Large language models make remarkable progress in reasoning capabilities. Existing works focus mainly on deductive reasoning tasks (e.g., code and math), while another type of reasoning mode that better aligns with human learning, inductive reasoning, is not well studied. We attribute the reason to the fact that obtaining high-quality process supervision data is challenging for inductive reasoning. Towards this end, we novelly employ number sequences as the source of inductive reasoning data. We package sequences into algorithmic problems to find the general term of each sequence through a code solution. In this way, we can verify whether the code solution holds for any term in the current sequence, and inject case-based supervision signals by using code unit tests. We build a sequence synthetic data pipeline and form a training dataset CodeSeq. Experimental results show that the models tuned with CodeSeq improve on both code and comprehensive reasoning benchmarks.
Enhancing Uncertainty Modeling with Semantic Graph for Hallucination Detection
Jan 02, 2025



Large Language Models (LLMs) are prone to hallucination with non-factual or unfaithful statements, which undermines the applications in real-world scenarios. Recent researches focus on uncertainty-based hallucination detection, which utilizes the output probability of LLMs for uncertainty calculation and does not rely on external knowledge or frequent sampling from LLMs. Whereas, most approaches merely consider the uncertainty of each independent token, while the intricate semantic relations among tokens and sentences are not well studied, which limits the detection of hallucination that spans over multiple tokens and sentences in the passage. In this paper, we propose a method to enhance uncertainty modeling with semantic graph for hallucination detection. Specifically, we first construct a semantic graph that well captures the relations among entity tokens and sentences. Then, we incorporate the relations between two entities for uncertainty propagation to enhance sentence-level hallucination detection. Given that hallucination occurs due to the conflict between sentences, we further present a graph-based uncertainty calibration method that integrates the contradiction probability of the sentence with its neighbors in the semantic graph for uncertainty calculation. Extensive experiments on two datasets show the great advantages of our proposed approach. In particular, we obtain substantial improvements with 19.78% in passage-level hallucination detection.
A Regularization-based Transfer Learning Method for Information Extraction via Instructed Graph Decoder
Mar 01, 2024Information extraction (IE) aims to extract complex structured information from the text. Numerous datasets have been constructed for various IE tasks, leading to time-consuming and labor-intensive data annotations. Nevertheless, most prevailing methods focus on training task-specific models, while the common knowledge among different IE tasks is not explicitly modeled. Moreover, the same phrase may have inconsistent labels in different tasks, which poses a big challenge for knowledge transfer using a unified model. In this study, we propose a regularization-based transfer learning method for IE (TIE) via an instructed graph decoder. Specifically, we first construct an instruction pool for datasets from all well-known IE tasks, and then present an instructed graph decoder, which decodes various complex structures into a graph uniformly based on corresponding instructions. In this way, the common knowledge shared with existing datasets can be learned and transferred to a new dataset with new labels. Furthermore, to alleviate the label inconsistency problem among various IE tasks, we introduce a task-specific regularization strategy, which does not update the gradients of two tasks with 'opposite direction'. We conduct extensive experiments on 12 datasets spanning four IE tasks, and the results demonstrate the great advantages of our proposed method
DiaHalu: A Dialogue-level Hallucination Evaluation Benchmark for Large Language Models
Mar 01, 2024Since large language models (LLMs) achieve significant success in recent years, the hallucination issue remains a challenge, numerous benchmarks are proposed to detect the hallucination. Nevertheless, some of these benchmarks are not naturally generated by LLMs but are intentionally induced. Also, many merely focus on the factuality hallucination while ignoring the faithfulness hallucination. Additionally, although dialogue pattern is more widely utilized in the era of LLMs, current benchmarks only concentrate on sentence-level and passage-level hallucination. In this study, we propose DiaHalu, the first dialogue-level hallucination evaluation benchmark to our knowledge. Initially, we integrate the collected topics into system prompts and facilitate a dialogue between two ChatGPT3.5. Subsequently, we manually modify the contents that do not adhere to human language conventions and then have LLMs re-generate, simulating authentic human-machine interaction scenarios. Finally, professional scholars annotate all the samples in the dataset. DiaHalu covers four common multi-turn dialogue domains and five hallucination subtypes, extended from factuality and faithfulness hallucination. Experiments through some well-known LLMs and detection methods on the dataset show that DiaHalu is a challenging benchmark, holding significant value for further research.