 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Rectangular Average-Reward Robust MDPs: Optimal Policies and Their Transient Values
Mar 03, 2026We study non-rectangular robust Markov decision processes under the average-reward criterion, where the ambiguity set couples transition probabilities across states and the adversary commits to a stationary kernel for the entire horizon. We show that any history-dependent policy achieving sublinear expected regret uniformly over the ambiguity set is robust-optimal, and that the robust value admits a minimax representation as the infimum over the ambiguity set of the classical optimal gains, without requiring any form of rectangularity or robust dynamic programming principle. Under the weak communication assumption, we establish the existence of such policies by converting high-probability regret bounds from the average-reward reinforcement learning literature into the expected-regret criterion. We then introduce a transient-value framework to evaluate finite-time performance of robust optimal policies, proving that average-reward optimality alone can mask arbitrarily poor transients and deriving regret-based lower bounds on transient values. Finally, we construct an epoch-based policy that combines an optimal stationary policy for the worst-case model with an anytime-valid sequential test and an online learning fallback, achieving a constant-order transient value.
Learning Sequential Decisions from Multiple Sources via Group-Robust Markov Decision Processes
Feb 02, 2026We often collect data from multiple sites (e.g., hospitals) that share common structure but also exhibit heterogeneity. This paper aims to learn robust sequential decision-making policies from such offline, multi-site datasets. To model cross-site uncertainty, we study distributionally robust MDPs with a group-linear structure: all sites share a common feature map, and both the transition kernels and expected reward functions are linear in these shared features. We introduce feature-wise (d-rectangular) uncertainty sets, which preserve tractable robust Bellman recursions while maintaining key cross-site structure. Building on this, we then develop an offline algorithm based on pessimistic value iteration that includes: (i) per-site ridge regression for Bellman targets, (ii) feature-wise worst-case (row-wise minimization) aggregation, and (iii) a data-dependent pessimism penalty computed from the diagonals of the inverse design matrices. We further propose a cluster-level extension that pools similar sites to improve sample efficiency, guided by prior knowledge of site similarity. Under a robust partial coverage assumption, we prove a suboptimality bound for the resulting policy. Overall, our framework addresses multi-site learning with heterogeneous data sources and provides a principled approach to robust planning without relying on strong state-action rectangularity assumptions.
Achieving $\varepsilon^{-2}$ Dependence for Average-Reward Q-Learning with a New Contraction Principle
Jan 29, 2026We present the convergence rates of synchronous and asynchronous Q-learning for average-reward Markov decision processes, where the absence of contraction poses a fundamental challenge. Existing non-asymptotic results overcome this challenge by either imposing strong assumptions to enforce seminorm contraction or relying on discounted or episodic Markov decision processes as successive approximations, which either require unknown parameters or result in suboptimal sample complexity. In this work, under a reachability assumption, we establish optimal $\widetilde{O}(\varepsilon^{-2})$ sample complexity guarantees (up to logarithmic factors) for a simple variant of synchronous and asynchronous Q-learning that samples from the lazified dynamics, where the system remains in the current state with some fixed probability. At the core of our analysis is the construction of an instance-dependent seminorm and showing that, after a lazy transformation of the Markov decision process, the Bellman operator becomes one-step contractive under this seminorm.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Bellman Optimality of Average-Reward Robust Markov Decision Processes with a Constant Gain
Sep 17, 2025Learning and optimal control under robust Markov decision processes (MDPs) have received increasing attention, yet most existing theory, algorithms, and applications focus on finite-horizon or discounted models. The average-reward formulation, while natural in many operations research and management contexts, remains underexplored. This is primarily because the dynamic programming foundations are technically challenging and only partially understood, with several fundamental questions remaining open. This paper steps toward a general framework for average-reward robust MDPs by analyzing the constant-gain setting. We study the average-reward robust control problem with possible information asymmetries between the controller and an S-rectangular adversary. Our analysis centers on the constant-gain robust Bellman equation, examining both the existence of solutions and their relationship to the optimal average reward. Specifically, we identify when solutions to the robust Bellman equation characterize the optimal average reward and stationary policies, and we provide sufficient conditions ensuring solutions' existence. These findings expand the dynamic programming theory for average-reward robust MDPs and lay a foundation for robust dynamic decision making under long-run average criteria in operational environments.
Representation-Aware Distributionally Robust Optimization: A Knowledge Transfer Framework
Sep 11, 2025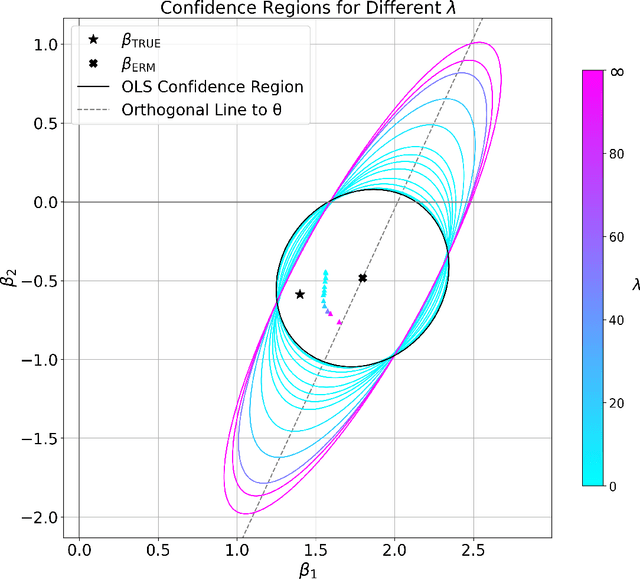
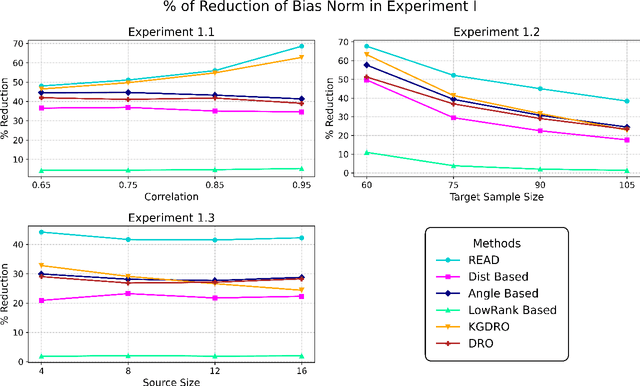
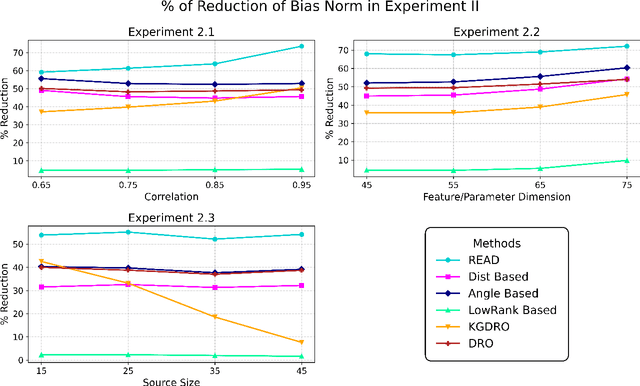
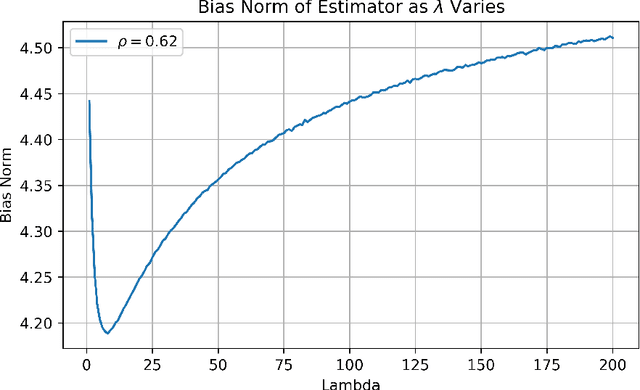
We propose REpresentation-Aware Distributionally Robust Estimation (READ), a novel framework for Wasserstein distributionally robust learning that accounts for predictive representations when guarding against distributional shifts. Unlike classical approaches that treat all feature perturbations equally, READ embeds a multidimensional alignment parameter into the transport cost, allowing the model to differentially discourage perturbations along directions associated with informative representations. This yields robustness to feature variation while preserving invariant structure. Our first contribution is a theoretical foundation: we show that seminorm regularizations for linear regression and binary classification arise as Wasserstein distributionally robust objectives, thereby providing tractable reformulations of READ and unifying a broad class of regularized estimators under the DRO lens. Second, we adopt a principled procedure for selecting the Wasserstein radius using the techniques of robust Wasserstein profile inference. This further enables the construction of valid, representation-aware confidence regions for model parameters with distinct geometric features. Finally, we analyze the geometry of READ estimators as the alignment parameters vary and propose an optimization algorithm to estimate the projection of the global optimum onto this solution surface. This procedure selects among equally robust estimators while optimally constructing a representation structure. We conclude by demonstrating the effectiveness of our framework through extensive simulations and a real-world study, providing a powerful robust estimation grounded in learning representation.
Near-Optimal Sample Complexities of Divergence-based S-rectangular Distributionally Robust Reinforcement Learning
May 18, 2025Distributionally robust reinforcement learning (DR-RL) has recently gained significant attention as a principled approach that addresses discrepancies between training and testing environments. To balance robustness, conservatism, and computational traceability, the literature has introduced DR-RL models with SA-rectangular and S-rectangular adversaries. While most existing statistical analyses focus on SA-rectangular models, owing to their algorithmic simplicity and the optimality of deterministic policies, S-rectangular models more accurately capture distributional discrepancies in many real-world applications and often yield more effective robust randomized policies. In this paper, we study the empirical value iteration algorithm for divergence-based S-rectangular DR-RL and establish near-optimal sample complexity bounds of $\widetilde{O}(|\mathcal{S}||\mathcal{A}|(1-\gamma)^{-4}\varepsilon^{-2})$, where $\varepsilon$ is the target accuracy, $|\mathcal{S}|$ and $|\mathcal{A}|$ denote the cardinalities of the state and action spaces, and $\gamma$ is the discount factor. To the best of our knowledge, these are the first sample complexity results for divergence-based S-rectangular models that achieve optimal dependence on $|\mathcal{S}|$, $|\mathcal{A}|$, and $\varepsilon$ simultaneously. We further validate this theoretical dependence through numerical experiments on a robust inventory control problem and a theoretical worst-case example, demonstrating the fast learning performance of our proposed algorithm.
Sample Complexity of Distributionally Robust Average-Reward Reinforcement Learning
May 15, 2025Motivated by practical applications where stable long-term performance is critical-such as robotics, operations research, and healthcare-we study the problem of distributionally robust (DR) average-reward reinforcement learning. We propose two algorithms that achieve near-optimal sample complexity. The first reduces the problem to a DR discounted Markov decision process (MDP), while the second, Anchored DR Average-Reward MDP, introduces an anchoring state to stabilize the controlled transition kernels within the uncertainty set. Assuming the nominal MDP is uniformly ergodic, we prove that both algorithms attain a sample complexity of $\widetilde{O}\left(|\mathbf{S}||\mathbf{A}| t_{\mathrm{mix}}^2\varepsilon^{-2}\right)$ for estimating the optimal policy as well as the robust average reward under KL and $f_k$-divergence-based uncertainty sets, provided the uncertainty radius is sufficiently small. Here, $\varepsilon$ is the target accuracy, $|\mathbf{S}|$ and $|\mathbf{A}|$ denote the sizes of the state and action spaces, and $t_{\mathrm{mix}}$ is the mixing time of the nominal MDP. This represents the first finite-sample convergence guarantee for DR average-reward reinforcement learning. We further validate the convergence rates of our algorithms through numerical experiments.
Knowledge-Guided Wasserstein Distributionally Robust Optimization
Feb 12, 2025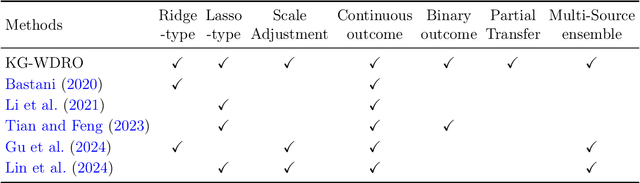
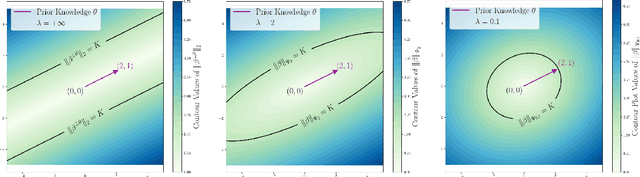
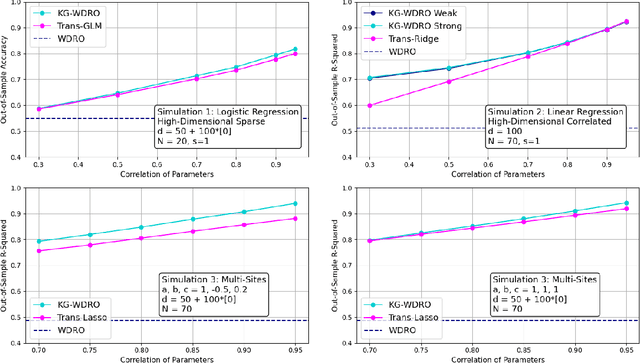
Transfer learning is a popular strategy to leverage external knowledge and improve statistical efficiency, particularly with a limited target sample. We propose a novel knowledge-guided Wasserstein Distributionally Robust Optimization (KG-WDRO) framework that adaptively incorporates multiple sources of external knowledge to overcome the conservativeness of vanilla WDRO, which often results in overly pessimistic shrinkage toward zero. Our method constructs smaller Wasserstein ambiguity sets by controlling the transportation along directions informed by the source knowledge. This strategy can alleviate perturbations on the predictive projection of the covariates and protect against information loss. Theoretically, we establish the equivalence between our WDRO formulation and the knowledge-guided shrinkage estimation based on collinear similarity, ensuring tractability and geometrizing the feasible set. This also reveals a novel and general interpretation for recent shrinkage-based transfer learning approaches from the perspective of distributional robustness. In addition, our framework can adjust for scaling differences in the regression models between the source and target and accommodates general types of regularization such as lasso and ridge. Extensive simulations demonstrate the superior performance and adaptivity of KG-WDRO in enhancing small-sample transfer learning.
ScoreFusion: fusing score-based generative models via Kullback-Leibler barycenters
Jun 28, 2024
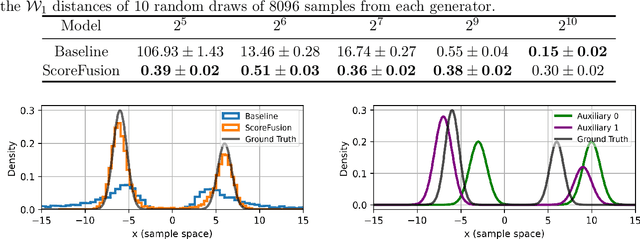


We study the problem of fusing pre-trained (auxiliary) generative models to enhance the training of a target generative model. We propose using KL-divergence weighted barycenters as an optimal fusion mechanism, in which the barycenter weights are optimally trained to minimize a suitable loss for the target population. While computing the optimal KL-barycenter weights can be challenging, we demonstrate that this process can be efficiently executed using diffusion score training when the auxiliary generative models are also trained based on diffusion score methods. Moreover, we show that our fusion method has a dimension-free sample complexity in total variation distance provided that the auxiliary models are well fitted for their own task and the auxiliary tasks combined capture the target well. The main takeaway of our method is that if the auxiliary models are well-trained and can borrow features from each other that are present in the target, our fusion method significantly improves the training of generative models. We provide a concise computational implementation of the fusion algorithm, and validate its efficiency in the low-data regime with numerical experiments involving mixtures models and image datasets.