 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMF-Speech: Achieving Fine-Grained and Compositional Control in Speech Generation via Factor Disentanglement
Nov 19, 2025Generating expressive and controllable human speech is one of the core goals of generative artificial intelligence, but its progress has long been constrained by two fundamental challenges: the deep entanglement of speech factors and the coarse granularity of existing control mechanisms. To overcome these challenges, we have proposed a novel framework called MF-Speech, which consists of two core components: MF-SpeechEncoder and MF-SpeechGenerator. MF-SpeechEncoder acts as a factor purifier, adopting a multi-objective optimization strategy to decompose the original speech signal into highly pure and independent representations of content, timbre, and emotion. Subsequently, MF-SpeechGenerator functions as a conductor, achieving precise, composable and fine-grained control over these factors through dynamic fusion and Hierarchical Style Adaptive Normalization (HSAN). Experiments demonstrate that in the highly challenging multi-factor compositional speech generation task, MF-Speech significantly outperforms current state-of-the-art methods, achieving a lower word error rate (WER=4.67%), superior style control (SECS=0.5685, Corr=0.68), and the highest subjective evaluation scores(nMOS=3.96, sMOS_emotion=3.86, sMOS_style=3.78). Furthermore, the learned discrete factors exhibit strong transferability, demonstrating their significant potential as a general-purpose speech representation.
CMFDFormer: Transformer-based Copy-Move Forgery Detection with Continual Learning
Nov 22, 2023Copy-move forgery detection aims at detecting duplicated regions in a suspected forged image, and deep learning based copy-move forgery detection methods are in the ascendant. These deep learning based methods heavily rely on synthetic training data, and the performance will degrade when facing new tasks. In this paper, we propose a Transformer-style copy-move forgery detection network named as CMFDFormer, and provide a novel PCSD (Pooled Cube and Strip Distillation) continual learning framework to help CMFDFormer handle new tasks. CMFDFormer consists of a MiT (Mix Transformer) backbone network and a PHD (Pluggable Hybrid Decoder) mask prediction network. The MiT backbone network is a Transformer-style network which is adopted on the basis of comprehensive analyses with CNN-style and MLP-style backbones. The PHD network is constructed based on self-correlation computation, hierarchical feature integration, a multi-scale cycle fully-connected block and a mask reconstruction block. The PHD network is applicable to feature extractors of different styles for hierarchical multi-scale information extraction, achieving comparable performance. Last but not least, we propose a PCSD continual learning framework to improve the forgery detectability and avoid catastrophic forgetting when handling new tasks. Our continual learning framework restricts intermediate features from the PHD network, and takes advantage of both cube pooling and strip pooling. Extensive experiments on publicly available datasets demonstrate the good performance of CMFDFormer and the effectiveness of the PCSD continual learning framework.
Joint group and residual sparse coding for image compressive sensing
Jan 23, 2019
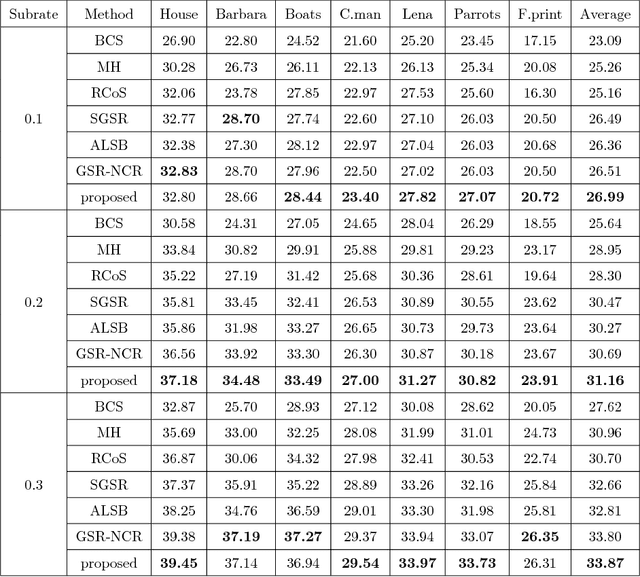
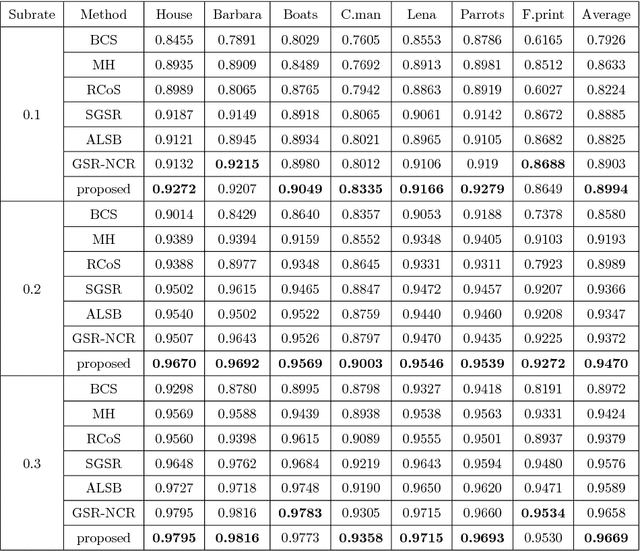

Nonlocal self-similarity and group sparsity have been widely utilized in image compressive sensing (CS). However, when the sampling rate is low, the internal prior information of degraded images may be not enough for accurate restoration, resulting in loss of image edges and details. In this paper, we propose a joint group and residual sparse coding method for CS image recovery (JGRSC-CS). In the proposed JGRSC-CS, patch group is treated as the basic unit of sparse coding and two dictionaries (namely internal and external dictionaries) are applied to exploit the sparse representation of each group simultaneously. The internal self-adaptive dictionary is used to remove artifacts, and an external Gaussian Mixture Model (GMM) dictionary, learned from clean training images, is used to enhance details and texture. To make the proposed method effective and robust, the split Bregman method is adopted to reconstruct the whole image. Experimental results manifest the proposed JGRSC-CS algorithm outperforms existing state-of-the-art methods in both peak signal to noise ratio (PSNR) and visual quality.