 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Risk Generation for Autonomous Driving: Naturalistic Reconstruction of Vehicle-E-Scooter Interactions
Apr 02, 2026The increasing, high-risk interactions between vehicles and vulnerable micromobility users, such as e-scooter riders, challenge vehicular safety functions and Automated Driving (AD) techniques, often resulting in severe consequences due to the dynamic uncertainty of e-scooter motion. Despite advances in data-driven AD methods, traffic data addressing the e-scooter interaction problem, particularly for safety-critical moments, remains underdeveloped. This paper proposes a pipeline that utilizes collected on-road traffic data and creates configurable synthetic interactions for validating vehicle motion planning algorithms. A Social Force Model (SFM) is applied to offer more dynamic and potentially risky movements for the e-scooter, thereby testing the functionality and reliability of the vehicle collision avoidance systems. A case study based on a real-world interaction scenario was conducted to verify the practicality and effectiveness of the established simulator. Simulation experiments successfully demonstrate the capability of extending the target scenario to more critical interactions that may result in a potential collision.
Lane-Wise Highway Anomaly Detection
May 05, 2025This paper proposes a scalable and interpretable framework for lane-wise highway traffic anomaly detection, leveraging multi-modal time series data extracted from surveillance cameras. Unlike traditional sensor-dependent methods, our approach uses AI-powered vision models to extract lane-specific features, including vehicle count, occupancy, and truck percentage, without relying on costly hardware or complex road modeling. We introduce a novel dataset containing 73,139 lane-wise samples, annotated with four classes of expert-validated anomalies: three traffic-related anomalies (lane blockage and recovery, foreign object intrusion, and sustained congestion) and one sensor-related anomaly (camera angle shift). Our multi-branch detection system integrates deep learning, rule-based logic, and machine learning to improve robustness and precision. Extensive experiments demonstrate that our framework outperforms state-of-the-art methods in precision, recall, and F1-score, providing a cost-effective and scalable solution for real-world intelligent transportation systems.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024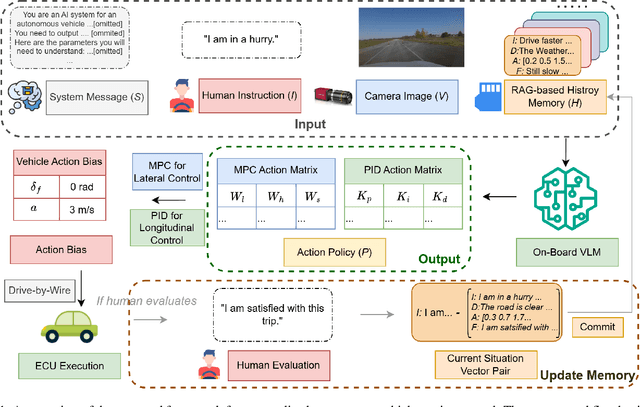
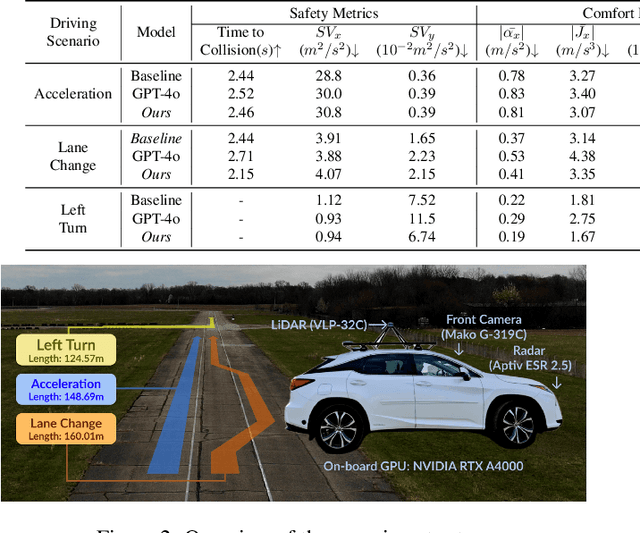

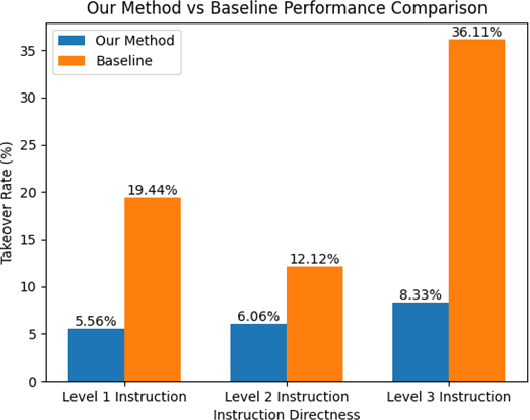
Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.
Optimizing ROI Benefits Vehicle ReID in ITS
Jul 13, 2024



Vehicle re-identification (ReID) is a computer vision task that matches the same vehicle across different cameras or viewpoints in a surveillance system. This is crucial for Intelligent Transportation Systems (ITS), where the effectiveness is influenced by the regions from which vehicle images are cropped. This study explores whether optimal vehicle detection regions, guided by detection confidence scores, can enhance feature matching and ReID tasks. Using our framework with multiple Regions of Interest (ROIs) and lane-wise vehicle counts, we employed YOLOv8 for detection and DeepSORT for tracking across twelve Indiana Highway videos, including two pairs of videos from non-overlapping cameras. Tracked vehicle images were cropped from inside and outside the ROIs at five-frame intervals. Features were extracted using pre-trained models: ResNet50, ResNeXt50, Vision Transformer, and Swin-Transformer. Feature consistency was assessed through cosine similarity, information entropy, and clustering variance. Results showed that features from images cropped inside ROIs had higher mean cosine similarity values compared to those involving one image inside and one outside the ROIs. The most significant difference was observed during night conditions (0.7842 inside vs. 0.5 outside the ROI with Swin-Transformer) and in cross-camera scenarios (0.75 inside-inside vs. 0.52 inside-outside the ROI with Vision Transformer). Information entropy and clustering variance further supported that features in ROIs are more consistent. These findings suggest that strategically selected ROIs can enhance tracking performance and ReID accuracy in ITS.
Enhancing Vehicle Re-identification and Matching for Weaving Analysis
Jul 05, 2024



Vehicle weaving on highways contributes to traffic congestion, raises safety issues, and underscores the need for sophisticated traffic management systems. Current tools are inadequate in offering precise and comprehensive data on lane-specific weaving patterns. This paper introduces an innovative method for collecting non-overlapping video data in weaving zones, enabling the generation of quantitative insights into lane-specific weaving behaviors. Our experimental results confirm the efficacy of this approach, delivering critical data that can assist transportation authorities in enhancing traffic control and roadway infrastructure.
An Efficient Probabilistic Solution to Mapping Errors in LiDAR-Camera Fusion for Autonomous Vehicles
Nov 08, 2023



LiDAR-camera fusion is one of the core processes for the perception system of current automated driving systems. The typical sensor fusion process includes a list of coordinate transformation operations following system calibration. Although a significant amount of research has been done to improve the fusion accuracy, there are still inherent data mapping errors in practice related to system synchronization offsets, vehicle vibrations, the small size of the target, and fast relative moving speeds. Moreover, more and more complicated algorithms to improve fusion accuracy can overwhelm the onboard computational resources, limiting the actual implementation. This study proposes a novel and low-cost probabilistic LiDAR-Camera fusion method to alleviate these inherent mapping errors in scene reconstruction. By calculating shape similarity using KL-divergence and applying RANSAC-regression-based trajectory smoother, the effects of LiDAR-camera mapping errors are minimized in object localization and distance estimation. Designed experiments are conducted to prove the robustness and effectiveness of the proposed strategy.
Risk assessment and mitigation of e-scooter crashes with naturalistic driving data
Dec 24, 2022


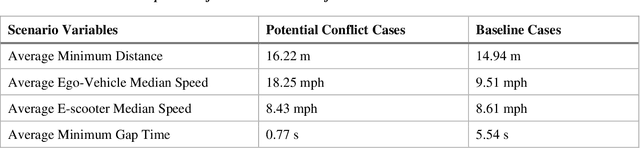
Recently, e-scooter-involved crashes have increased significantly but little information is available about the behaviors of on-road e-scooter riders. Most existing e-scooter crash research was based on retrospectively descriptive media reports, emergency room patient records, and crash reports. This paper presents a naturalistic driving study with a focus on e-scooter and vehicle encounters. The goal is to quantitatively measure the behaviors of e-scooter riders in different encounters to help facilitate crash scenario modeling, baseline behavior modeling, and the potential future development of in-vehicle mitigation algorithms. The data was collected using an instrumented vehicle and an e-scooter rider wearable system, respectively. A three-step data analysis process is developed. First, semi-automatic data labeling extracts e-scooter rider images and non-rider human images in similar environments to train an e-scooter-rider classifier. Then, a multi-step scene reconstruction pipeline generates vehicle and e-scooter trajectories in all encounters. The final step is to model e-scooter rider behaviors and e-scooter-vehicle encounter scenarios. A total of 500 vehicle to e-scooter interactions are analyzed. The variables pertaining to the same are also discussed in this paper.
A Wearable Data Collection System for Studying Micro-Level E-Scooter Behavior in Naturalistic Road Environment
Dec 22, 2022



As one of the most popular micro-mobility options, e-scooters are spreading in hundreds of big cities and college towns in the US and worldwide. In the meantime, e-scooters are also posing new challenges to traffic safety. In general, e-scooters are suggested to be ridden in bike lanes/sidewalks or share the road with cars at the maximum speed of about 15-20 mph, which is more flexible and much faster than the pedestrains and bicyclists. These features make e-scooters challenging for human drivers, pedestrians, vehicle active safety modules, and self-driving modules to see and interact. To study this new mobility option and address e-scooter riders' and other road users' safety concerns, this paper proposes a wearable data collection system for investigating the micro-level e-Scooter motion behavior in a Naturalistic road environment. An e-Scooter-based data acquisition system has been developed by integrating LiDAR, cameras, and GPS using the robot operating system (ROS). Software frameworks are developed to support hardware interfaces, sensor operation, sensor synchronization, and data saving. The integrated system can collect data continuously for hours, meeting all the requirements including calibration accuracy and capability of collecting the vehicle and e-Scooter encountering data.
SceNDD: A Scenario-based Naturalistic Driving Dataset
Dec 22, 2022
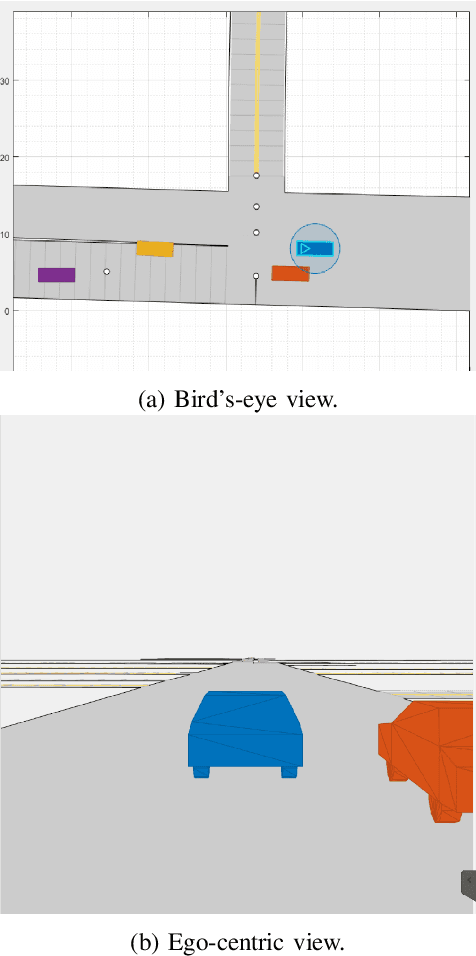

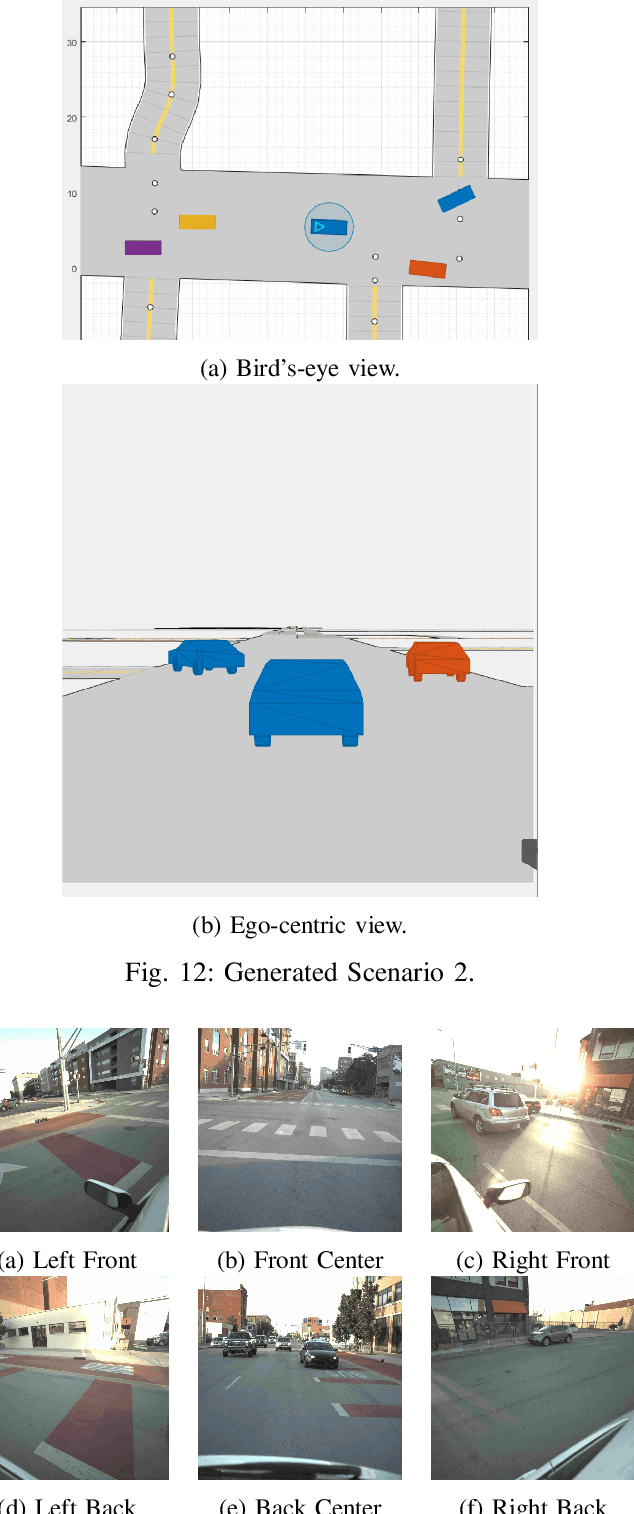
In this paper, we propose SceNDD: a scenario-based naturalistic driving dataset that is built upon data collected from an instrumented vehicle in downtown Indianapolis. The data collection was completed in 68 driving sessions with different drivers, where each session lasted about 20--40 minutes. The main goal of creating this dataset is to provide the research community with real driving scenarios that have diverse trajectories and driving behaviors. The dataset contains ego-vehicle's waypoints, velocity, yaw angle, as well as non-ego actor's waypoints, velocity, yaw angle, entry-time, and exit-time. Certain flexibility is provided to users so that actors, sensors, lanes, roads, and obstacles can be added to the existing scenarios. We used a Joint Probabilistic Data Association (JPDA) tracker to detect non-ego vehicles on the road. We present some preliminary results of the proposed dataset and a few applications associated with it. The complete dataset is expected to be released by early 2023.
PSI: A Pedestrian Behavior Dataset for Socially Intelligent Autonomous Car
Dec 05, 2021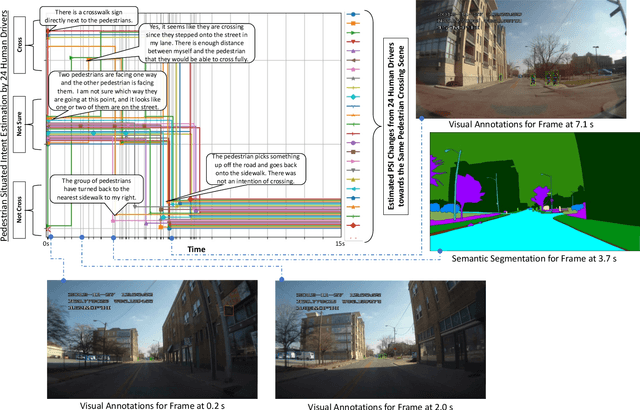


Prediction of pedestrian behavior is critical for fully autonomous vehicles to drive in busy city streets safely and efficiently. The future autonomous cars need to fit into mixed conditions with not only technical but also social capabilities. As more algorithms and datasets have been developed to predict pedestrian behaviors, these efforts lack the benchmark labels and the capability to estimate the temporal-dynamic intent changes of the pedestrians, provide explanations of the interaction scenes, and support algorithms with social intelligence. This paper proposes and shares another benchmark dataset called the IUPUI-CSRC Pedestrian Situated Intent (PSI) data with two innovative labels besides comprehensive computer vision labels. The first novel label is the dynamic intent changes for the pedestrians to cross in front of the ego-vehicle, achieved from 24 drivers with diverse backgrounds. The second one is the text-based explanations of the driver reasoning process when estimating pedestrian intents and predicting their behaviors during the interaction period. These innovative labels can enable several computer vision tasks, including pedestrian intent/behavior prediction, vehicle-pedestrian interaction segmentation, and video-to-language mapping for explainable algorithms. The released dataset can fundamentally improve the development of pedestrian behavior prediction models and develop socially intelligent autonomous cars to interact with pedestrians efficiently. The dataset has been evaluated with different tasks and is released to the public to access.